









第1关:走进机器学习
机器学习简介
机器学习近年来被大规模应用在各种领域,特别是 NLP 领域。虽然机器学习是门建立在统计和优化上的新兴学科,但是在自然语言处理、数据科学等领域,它却占据着核心的地位。

图 1
机器学习最初的研究动机是让计算机系统具有人的学习能力以便实现人工智能。因为没有学习能力的系统很难被认为是具有智能的。目前被广泛采用的机器学习的定义是“利用经验来改善计算机系统自身的性能”。事实上,由于“经验”在计算机系统中主要以数据的形式存在,因此机器学习需要设法对数据进行分析学习,这就使得它逐渐成为智能数据分析技术的创新源之一,并且受到越来越多的关注。机器学习的核心在于建模和算法,学习得到的参数只是一个结果。
机器学习训练的要素
成功地训练一个模型需要四个要素:数据、转换数据的模型、衡量模型好坏的损失函数和一个调整模型权重以便最小化损失函数的算法。
1、数据
对于数据,肯定是越多越好。事实上,数据是机器学习发展的核心,因为复杂的非线性模型比其他线性模型需要更多的数据。
2、模型
通常数据和我们最终想要的相差很远,例如我们想知道照片中的人是不是在高兴,所以我们需要把一千万像素变成一个高兴度的概率值。通常我们需要在数据上应用数个非线性函数(例如神经网络)。
3、损失函数
我们需要对比模型的输出和真实值之间的误差。损失函数可以帮助我们平衡先验和后验的期望,以便我们做出决策。损失函数的选取,取决于我们想短线还是长线。
4、训练
通常一个模型里面有很多参数。我们通过最小化损失函数来寻找最优参数。不幸的是,即使我们在训练集上面拟合得很好,也不能保证在新的没见过的数据上我们可以仍然做得很好。
5、误差
训练误差是模型在训练数据集上的误差;测试误差则指的是模型在没见过的新数据上的误差,可能会跟训练误差不一样(统计上叫过拟合)。
机器学习的组成部分
机器学习中最重要的四类问题(按学习结果分类):
-
预测( Prediction ):用回归( Regression,Arima )等模型;
-
聚类( Clustering ):如 K-means 方法;
-
分类( Classification ):支持向量机( Support Vector Machine,SVM )、逻辑回归( Logistic Regression );
-
降维( Dimensional reduction ):主成分分析法( Principal Component Analysis,即纯矩阵运算)。
如果按照学习方法,机器学习又可以分为如下几类:
-
监督学习 ( Supervised Learning ,如深度学习);
-
无监督学习 ( Un-supervised Learning ,如聚类);
-
半监督学习 ( Semi- supervised Learning );
-
增强学习 ( Reinforced Learning )。
监督学习描述的主要任务是:对给定输入 x ,如何通过在标注输入和输出的数据上训练模型而预测输出 y ;
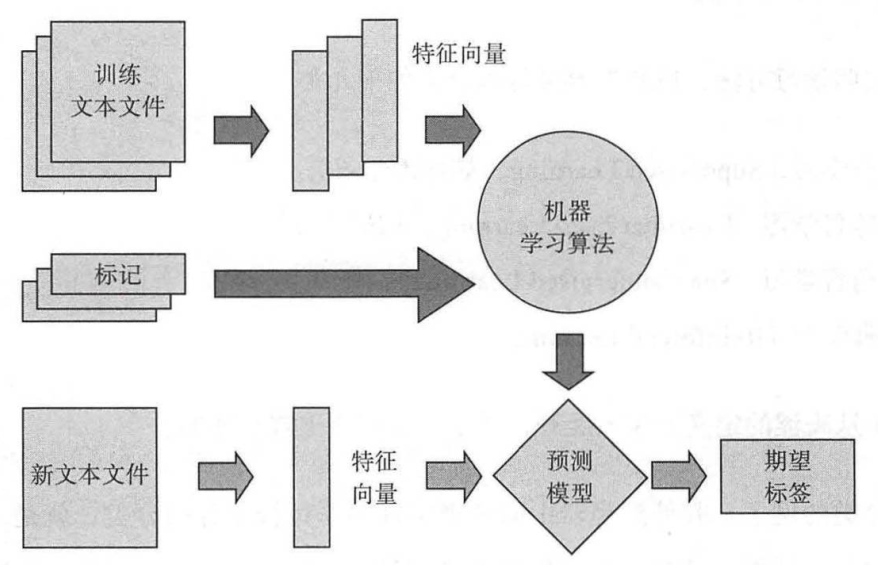
图 2 监督学习框架图
如图2所示,监督学习任务的基本框架流程有:
-
先准备训练数据,然后抽取所需特征形成特征向量;
-
将这些特征连同对应标记一起给学习算法,训练出一个预测模型;
-
采用同样的特征抽取方法作用于新测试数据,得到用于测试的特征向量;
-
使用预测模型对将来的数据进行预测。
无监督学习即在没有人工标记的情况下,计算机进行预测、分类等工作,半监督则介于两者之间。

第2关:常用的机器学习方法
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









