






鱼鱼的DataWhale组队学习笔记(持续更新)
2023-9 大模型学习入门笔记
2024-4 图神经网络入门笔记
文章目录
图表示学习
在图上表示学习和嵌入指的是同一个事情,从不同角度的称呼。
“嵌入”是指将网络中的每个节点映射到低维空间,这将使我们深入了解节点的相似性和网络结构。
鉴于图在网络和物理世界中的广泛流行,图的表示学习在广泛的应用中发挥着重要作用,例如链接预测和异常检测。
然而,现代机器学习算法是为简单的序列或网格(例如,固定大小的图像/网格或文本/序列)而设计的,网络通常具有复杂的拓扑结构和多模型特征。
我们将探索嵌入方法来克服困难。
节点表示学习
节点嵌入的目标是对节点进行解码,使得嵌入空间中的相似性(例如点积)近似于原始网络中的相似性。
通过把节点的特点转换成一个连续的向量形式,使得可以应用基于向量的机器学习算法进行进一步的分析和预测。
嵌入空间(Embedding Space)是指节点被映射到的低维向量空间。在嵌入空间中,节点之间的几何关系和相似性可以通过向量之间的距离和角度来表示。
嵌入空间的维度通常是用户预先指定的超参数。
节点嵌入算法:在图中自动学习节点嵌入的算法,这些算法通常会探索图的结构和节点之间的关系,并将节点映射到嵌入空间中的向量表示。
1.定义一个编码器,将节点映射到低维向量中。
编码器应该是一个如同函数的东西。一般在图神经网络里,编码器指的是一个神经网络模型如mlp。一般是用来提取节点特征。
2.定义节点相似度函数,度量原本网络中的相似性。指定向量空间中的关系如何映射原本网络中的关系。
节点相似度函数可以与编码器的损失函数相结合,通过最小化相似节点之间的嵌入距离或最大化不相似节点之间的嵌入距离来优化编码器的参数。
3.优化编码器的参数,使得节点在嵌入空间的相似度更高。
随机游走normal 深度游走
常见的随机游走策略包括正常随机游走(Random Walk)和深度游走(DeepWalk),它们在节点选择和游走路径的长度上有所不同。
正常随机游走(Random Walk):正常随机游走是指从当前节点出发,按照一定的概率随机选择下一个节点进行移动。在每一步中,根据预定义的转移概率,从当前节点的邻居节点中随机选择一个节点作为下一个节点,并重复这个过程进行多次步骤。正常随机游走通常不限制游走路径的长度,可以根据具体需求进行设置。
深度游走(DeepWalk):深度游走是一种特殊的随机游走策略,在游走过程中限制了游走路径的长度。深度游走从当前节点出发,按照预定义的转移概率选择下一个节点,并在每一步中限制游走路径的长度,通常使用固定长度的路径(例如,在每次游走中只选择固定步数的节点)。深度游走通过控制游走路径的长度,可以更好地捕捉到节点之间的局部结构信息。
深度游走通常与词向量模型(如Word2Vec)相结合,通过将游走路径视为句子序列,使用Word2Vec等技术来学习节点嵌入。
希望在嵌入空间中使得附近的节点嵌入相似度高,因此我们需要进行嵌入的优化,以使附近的节点在网络中靠近在一起。
损失函数𝐿由两部分组成。第一部分是对所有中心节点𝑢的游走邻居集合𝑅(𝑢)求和,表示要最大化所有节点与其邻居节点出现在游走路径中的共现次数。第二部分是对每个中心节点𝑢的邻居节点𝑣求和,并对条件概率𝑃(𝑣|𝑧𝑢)取负对数。目标是最小化节点𝑣的条件概率,即增大节点𝑣出现在𝑅(𝑢)中的概率。
引入负采样可以解决计算所有节点对之间相似度的问题,负采样通过随机采样一小部分负样本,将计算的范围缩小到了采样的节点对上。(在节点嵌入任务中,负样本是指与中心节点𝑢不相关的节点对。即它们在图中可能没有直接的连接或共现关系。)通过合理的负采样策略,可以提高节点嵌入的质量和表示能力,从而更好地捕捉图的结构和特征。
具体来说,对于每个中心节点𝑢,从随机概率分布𝑃𝑣中采样𝑘个负样本𝑛𝑖。
通过引入负样本,我们可以将节点嵌入任务转化为一个二分类问题,即判别一个节点对是正样本还是负样本。
噪声对比估计(NCE)是一种用于二分类问题的训练方法。在NCE中,我们通过最大化正样本的概率和最小化负样本的概率来训练模型。具体来说,对于每个中心节点𝑢,我们希望模型能够将正样本的概率分布尽可能地靠近1,将负样本的概率分布尽可能地靠近0。
子图搜索(看群里的小伙伴聊起所以搜了搜)
子图搜索在DeepWalk中起到两个关键的作用:
- 游走长度(Walk Length):子图搜索确定了每个游走路径的长度,即游走过程中经过的节点数。较长的游走路径可以更好地捕捉节点之间的高阶关系,但也可能导致过度采样和计算复杂度增加。较短的游走路径则更注重节点的局部邻域信息。因此,子图搜索决定了游走路径的长度,从而影响到DeepWalk算法中节点嵌入的特征表达。
- 邻域采样(Neighbor Sampling):子图搜索还决定了每个节点在游走过程中选择邻居节点的方式。在每个游走步骤中,根据节点的邻居关系,子图搜索决定了选择哪些邻居节点作为下一步的访问节点。邻域采样的策略可以影响到游走路径的随机性和覆盖性,从而影响到节点嵌入的质量和多样性。
子图搜索的选择需要根据具体的图结构和任务进行调优。较长的游走路径和更广泛的邻域采样可以捕捉到更丰富的图结构信息,但可能导致过度采样和计算复杂度增加。较短的游走路径和更局部化的邻域采样则更加高效,但可能损失一部分全局信息。因此,需要在选择子图搜索策略时,权衡嵌入质量、计算效率和应用需求。
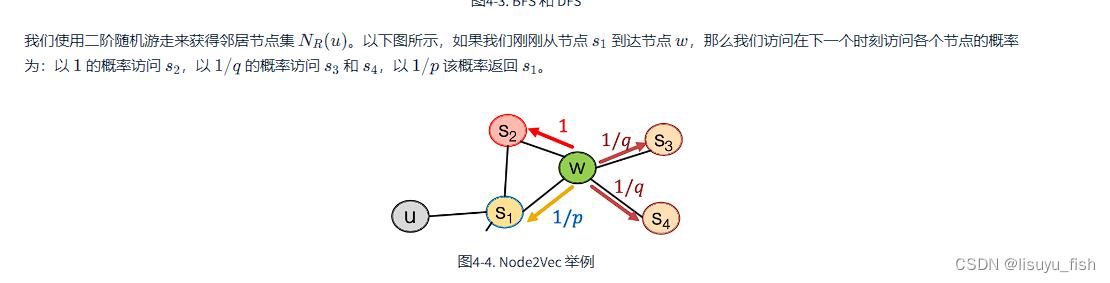
有偏随机游走:Node2Vec
Node2Vec是一种基于随机游走的节点嵌入方法。它引入了有偏随机游走策略,通过平衡广度优先和深度优先策略,更好地探索图的结构,并生成节点序列用于学习节点嵌入。
Node2Vec 提出了一种更高效的、灵活的、有偏的随机游走策略,以得到一个更好的 𝑁_𝑅(𝑢)。Node2Vec 通过图上的广度优先遍历(Breath First Search, BFS)和深度优先遍历(Depth First Search, DFS)在网络的局部视图和全局视图之间进行权衡。
需要定义两个参数:p 和 q。参数 p 控制游走过程中返回到之前节点的概率,从而使游走更倾向于广度优先;参数 q 控制游走过程中转向到邻居节点的概率,从而使游走更倾向于深度优先。
昨晚书里面这个地方一直都不会,问了一下学弟才知道,公式在图中大家自己看下吧。

图表示学习
在传统的图节点嵌入技术中,仅考虑图中的实际节点(例如,社交网络中的用户、推荐系统中的物品)。然而,有时候我们想要将不同类型的图结构或图之间的关系整合到一个统一的嵌入空间中。
这时,可以引入"虚拟节点"来表示这些不同类型的图结构或图之间的关系。虚拟节点并不代表实际的节点,而是一种表示特定关系或上下文的节点。通过引入虚拟节点,可以将不同类型的图结构映射到同一个嵌入空间中,从而使得不同类型的图之间可以进行联合分析和比较。
代码研究
边分类任务是指根据图中的边的特征和节点的特征,将边分为正类或负类的任务**。正类边表示具有某种关系或连接性的边,而负类边表示没有关系或连接性的边。** 在这个课题中,正边是图中存在的边,负边:图中不存在的边,即两个节点之间在真实图中没有连线的边。
NetworkX是一个用于创建、操作和研究复杂网络的Python库。它提供了丰富的工具和函数,用于构建、分析和可视化各种类型的网络,包括有向图和无向图。
NetworkX提供了一个灵活而强大的数据结构来表示网络,例如图(Graph)、有向图(DiGraph)、多重图(MultiGraph)等。它支持节点和边的各种属性,并提供了许多用于操作和访问网络的方法。
初始化嵌入函数:
给定节点的数量和嵌入向量的维度,函数create_node_emb创建了一个嵌入层(nn.Embedding对象),并将节点映射为向量表示。
nn.Embedding是PyTorch中用于创建嵌入层的类,它提供了将离散索引映射为连续向量表示的功能。
随机初始化过程将这个随机张量的值赋给nn.Embedding对象的权重矩阵,使得权重矩阵的每个元素都被初始化为一个随机的值。
通过俱乐部的属性进行分类。
def create_node_emb(num_node=34, embedding_dim=16):
emb=nn.Embedding(num_node,embedding_dim) # 创建 Embedding
emb.weight.data=torch.rand(num_node,embedding_dim) # 均匀初始化
return emb
components = pca.fit_transform(X)
for node in G.nodes(data=True):
if node[1]['club'] == 'Mr. Hi':
#node的形式:第一个元素是索引,第二个元素是attributes字典
club1_x.append(components[node[0]][0])
club1_y.append(components[node[0]][1])
#这里添加的元素就是节点对应的embedding经PCA后的两个维度
else:
club2_x.append(components[node[0]][0])
club2_y.append(components[node[0]][1])
使用边分类任务来完成表示学习,是指通过训练一个模型来预测图中边的类别,从而学习到节点和边的低维向量表示,以便更好地理解图的结构和关系,并应用于其他图相关的任务。
将图数据转换为边列表,并将边列表转换为张量表示作为正边,以便在后续的操作中使用。
def graph_to_edge_list(G):
# 将 tensor 变成 edge_list
edge_list = []
for edge in G.edges():
edge_list.append(edge)
return edge_list
def edge_list_to_tensor(edge_list):
# 将 edge_list 变成 tesnor
edge_index = torch.tensor([])
edge_index=torch.LongTensor(edge_list).t()
return edge_index
pos_edge_list = graph_to_edge_list(G)
pos_edge_index = edge_list_to_tensor(pos_edge_list)
print("The pos_edge_index tensor has shape {}".format(pos_edge_index.shape))
print("The pos_edge_index tensor has sum value {}".format(torch.sum(pos_edge_index)))
采样获取负边:
通过调用 nx.non_edges(G) 函数获取图中所有不存在的边(即非边),并将其存储在 non_edges_one_side 列表中。然后,它随机选择 num_neg_samples 个非边的索引,并根据这些索引从 non_edges_one_side 中获取对应的负边,并将其添加到 neg_edge_list 列表中。
import random
# 采样负边
def sample_negative_edges(G, num_neg_samples):
neg_edge_list = []
# 得到图中所有不存在的边(这个函数只会返回一侧,不会出现逆边)
non_edges_one_side = list(enumerate(nx.non_edges(G)))
neg_edge_list_indices = random.sample(range(0,len(non_edges_one_side)), num_neg_samples)
# 取样num_neg_samples长度的索引
for i in neg_edge_list_indices:
neg_edge_list.append(non_edges_one_side[i][1])
return neg_edge_list
# Sample 78 negative edges
neg_edge_list = sample_negative_edges(G, len(pos_edge_list))
# Transform the negative edge list to tensor
neg_edge_index = edge_list_to_tensor(neg_edge_list)
print("The neg_edge_index tensor has shape {}".format(neg_edge_index.shape))
对点对之间的嵌入进行逐元素相乘操作(train_node_emb[0].mul(train_node_emb[1])),并将结果求和,得到点对之间的点积结果 dot_product_result。将点积结果经过 sigmoid 函数得到激活后的结果 sigmoid_result。接下来,使用损失函数 loss_fn 计算损失结果 loss_result。然后,通过反向传播(loss_result.backward())计算梯度并更新参数(optimizer.step())。
dot_product_result = train_node_emb[0].mul(train_node_emb[1]) # 点对之间对应位置嵌入相乘,[156,16]
dot_product_result = torch.sum(dot_product_result,1) # 加起来,构成点对之间向量的点积,[156]
sigmoid_result = sigmoid(dot_product_result) # 将这个点积结果经过激活函数映射到0,1之间
loss_result = loss_fn(sigmoid_result,train_label)
loss_result.backward()
optimizer.step()
正样本标签 pos_label设为全为 1 ,负样本标签 neg_label设为全为 0 。
pos_label = torch.ones(pos_edge_index.shape[1], )
neg_label = torch.zeros(neg_edge_index.shape[1], )
将正样本边索引 pos_edge_index 和负样本边索引 neg_edge_index 进行拼接,得到训练集的边索引 train_edge。将正样本标签 pos_label 和负样本标签 neg_label 进行拼接,得到训练集的标签 train_label。
train_label = torch.cat([pos_label, neg_label], dim=0)
# 拼接正负样本
# 因为数据集太小,我们就全部作为训练集
train_edge = torch.cat([pos_edge_index, neg_edge_index], dim=1)
最后,目前为止我们并没有对优化后的嵌入进行评价,这也是接下来需要进一步去学习和探索的。
写在最后
前段时间24fall终于结束了,终于可以安心的继续学习新内容了。这段时间日语、驾照、深度学习、英语等多样事情齐头并进中。终于把大家的日本语第一册学完了,下周考完科目一后开始复习背诵,接着就可以开始学第二册了好开心。。
这个四月报名了图神经网络学习和GPT蝴蝶书共读,希望可以坚持下去哇。前几天比较匆忙所以没有写笔记。。今天正好科目一的题目刷完了,仔细来学一下今天的内容!话说新组装的电脑是A卡……并不能用cuda来着。不知道tensorflow能不能使用,过段时间看看吧。
今天学习的时间有点长,很多内容都需要重新补充和思考。做深度学习的时候时常感觉自己的数学基础不够扎实,公式不会用也不知道是怎么在代码中实现的。例如今日在二阶随机游走那思考了好久。思考了一下之后才得到了答案。总之潦草的过一遍是肯定不行的,还需要深入研究和思考。
话说CSDN竟然不支持Latex啊……这下可能要转github了。















 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









