







今天的课是上课的时候记了一部分笔记,接着第二天又听一遍重新整理。
给一张图片,定位物体,预测类别
相对于图像分类,目标检测中的物体数量不固定,位置和大小也不固定。
滑窗:
1.设定一个固定大小的窗口,扫所有的位置。返回网络里预测一个类别,预测一个划一块,
一直划,直到产生物体;
遍历完后,就可以找到所有有物体的位置并预测出来。
为了检测不同大小形状的物体,可以用不同大小长宽比的窗口进行扫描。
问题:效率
改进1:启发式算法替换暴力遍历
启发式算法(heuristic algorithm)是相对于最优化算法提出的。一个问题的最优算法求得该问题每个实例的最优解。启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。现阶段,启发式算法以仿自然体算法为主,主要有蚁群算法、模拟退火法、神经网络等。
使用selective search产生提议框,系统复杂难以联合优化性能。
selective search:
https://blog.csdn.net/weixin_43694096/article/details/121610856
Selective Search算法就是将空间相邻且特征相似的图像块逐步合并到一起,形成可能包含物体的区域,称为提议区域或提议框。
2.减少冗余计算,使用卷积网络进行密集预测(因为卷积也是滑窗)
因为是预测图像中的每个像素,这个任务通常被称为密集预测(dense prediction)
小插播:相比全卷积,Vision Transformer在单目深度估计应用任务上,性能提高了28%。
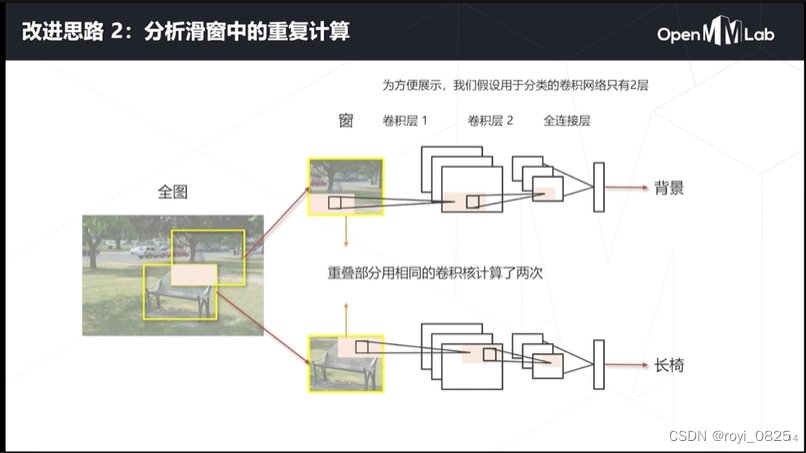
最开始每次用卷积核扫窗,生成一个特征图,再拿一个卷积核去扫特征图,得到全连接层。
这样中间重复的部分就是用相同的卷积核计算了两次。
如何把重复的地方去掉?
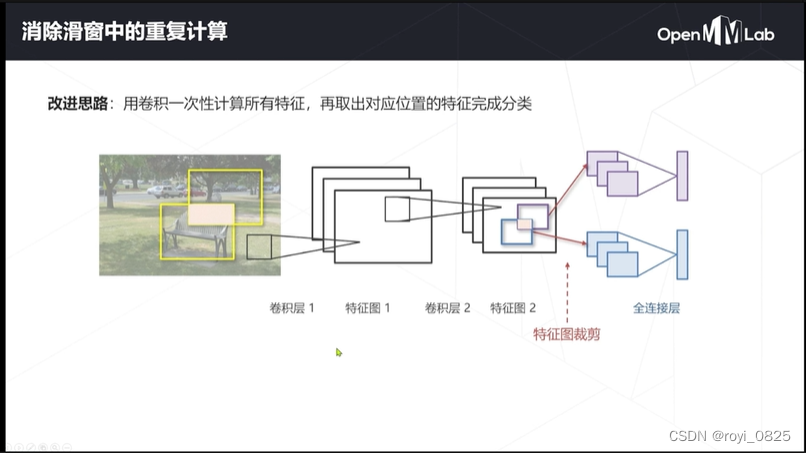
改进:用卷积一次性计算所有特征,再取出对应位置的特征完成分类。
用卷积核扫整张图象,得到完整的特征图(两层),分类的时候按照位置在对特征图2进行裁剪送入全连接层,
重复区域只计算一次卷积特征,与窗的个数无关.
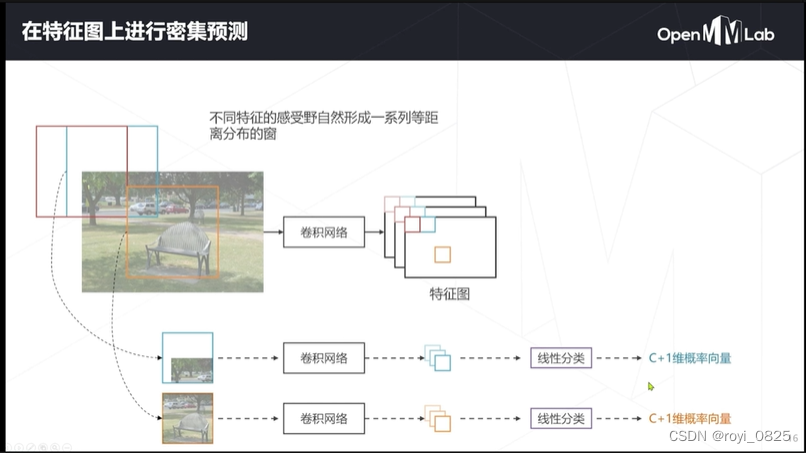
特征计算:不同特征的感受野自然形成了一系列等距离分布的窗,把这些特征送入线性分类后形成概率向量,向量最后生成一个概率图。(+1是有可能没有物体是背景)
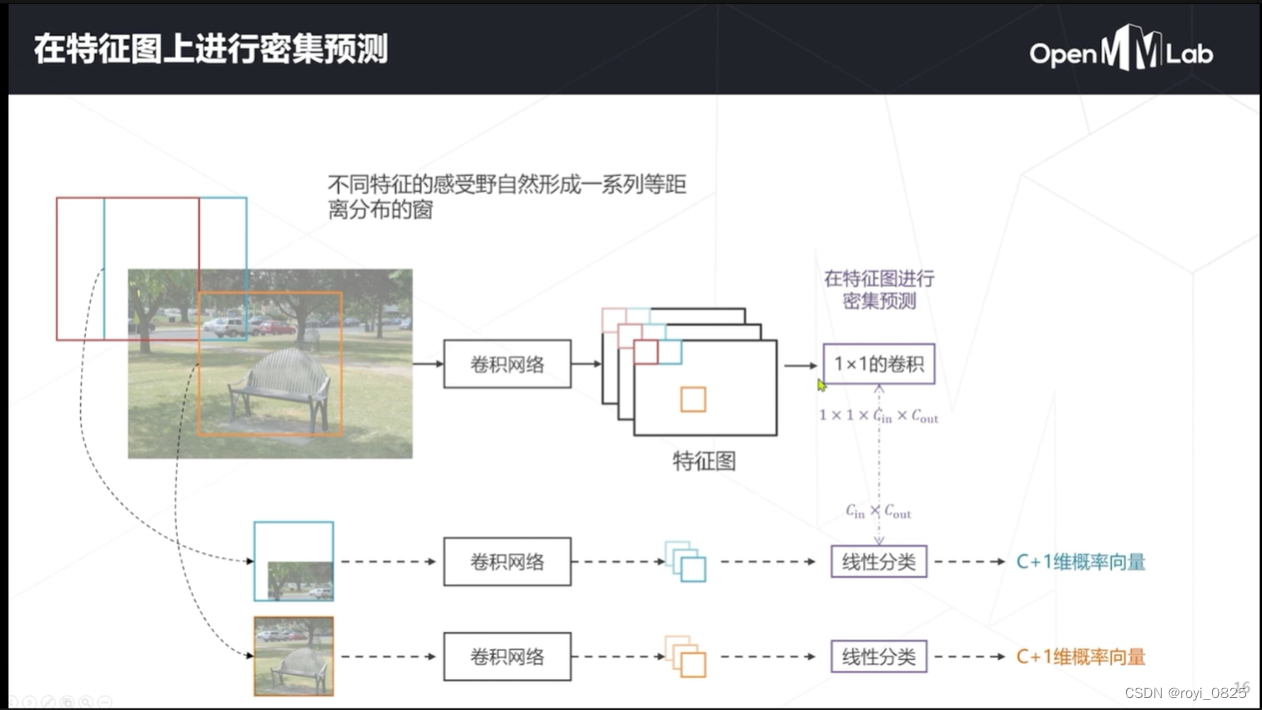
实际上变成了一个3X(C+1)维的这么一个东西,这时候可以在形状上进行一些改变,变成1x1x{C_in}x{C_out},把产生的概率也按照对应的位置排起来,就会得到一个叫概率图的东西。
密集预测实际上是一种隐式的滑窗方法,计算效率远高于滑窗。
两阶段方法:先产生窗,然后基于窗口的特征预测
单阶段:在特征图上基于单点特征实现密集预测
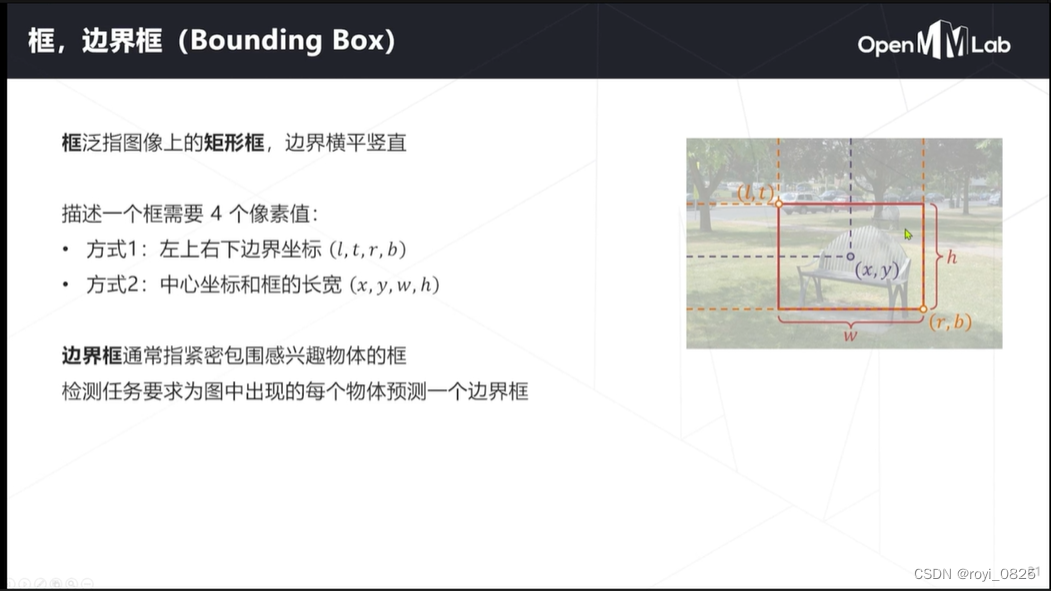

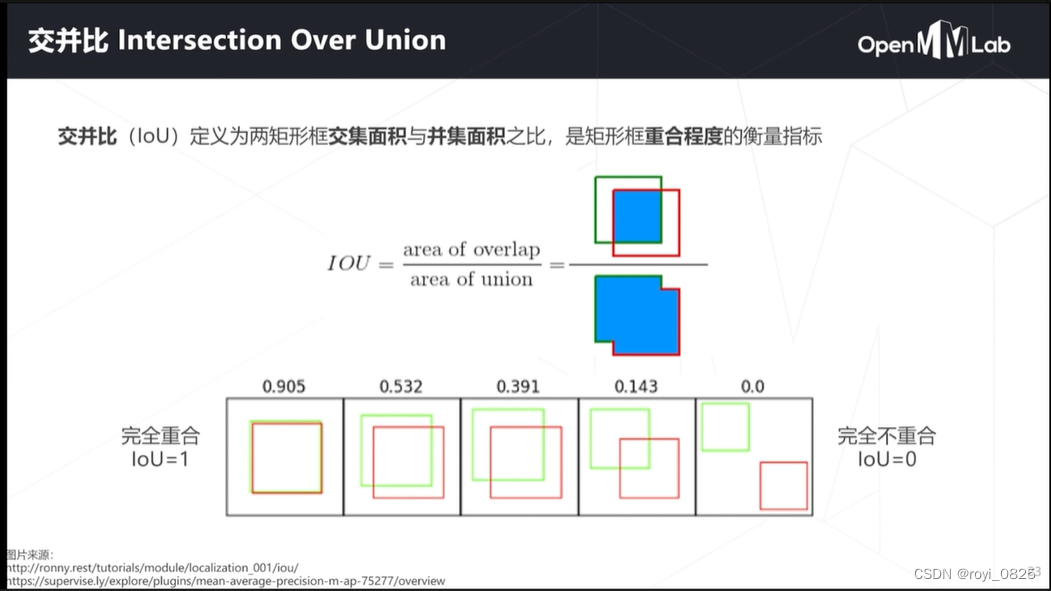


预测边界问题
实际上是一个回归问题,滑窗(或其他方式产生的基准框)与物体精准边界常有偏差。
处理方法:让模型在预测物体类别同时预测边界框相对于滑窗的偏移量
(多任务学习)分类的同时基于相同的特征去预测一下偏移量,计算回归损失。
backward的时候把这两个的损失积累到一起来计算梯度

实际上:
存在局限:
1.物体的大小不同,区域提议算法需要产生不同尺寸的提议框,以适应不同尺寸的物体
2.物体可能有一定程度的重合,区域提议算法要有能力在同一位置产生不同尺寸的提议框,以适应重合情况。
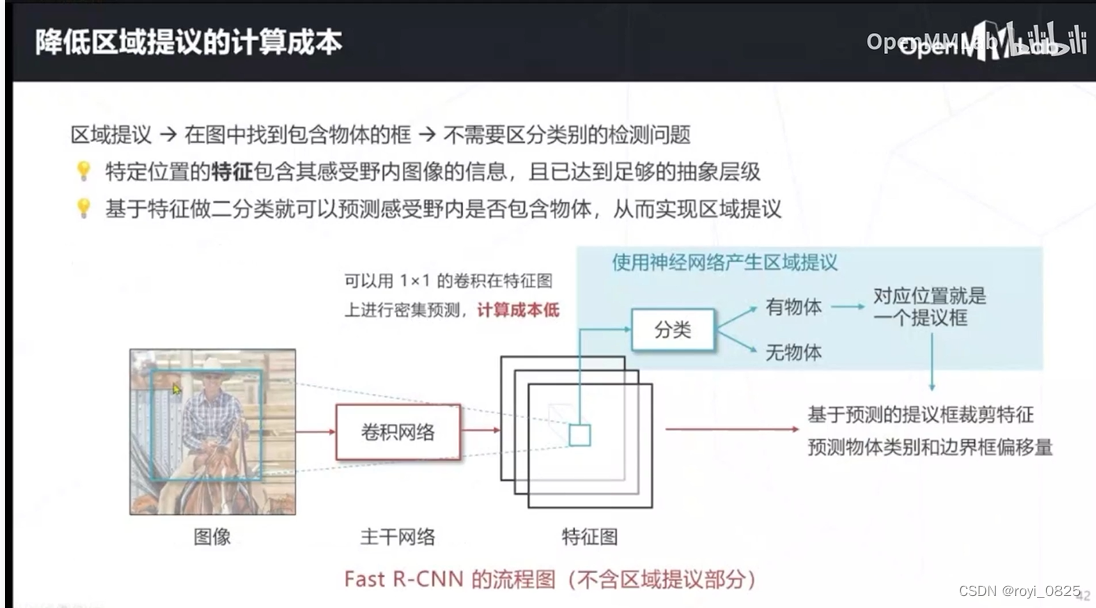
锚框:对局限的改进
根据特征图中心的位置在原图上对应位置的上设置一些不同大小不同长宽比同时有重合的一些基准框,然后对其进行扩展,计算这些不同尺度的框中是否有物体。
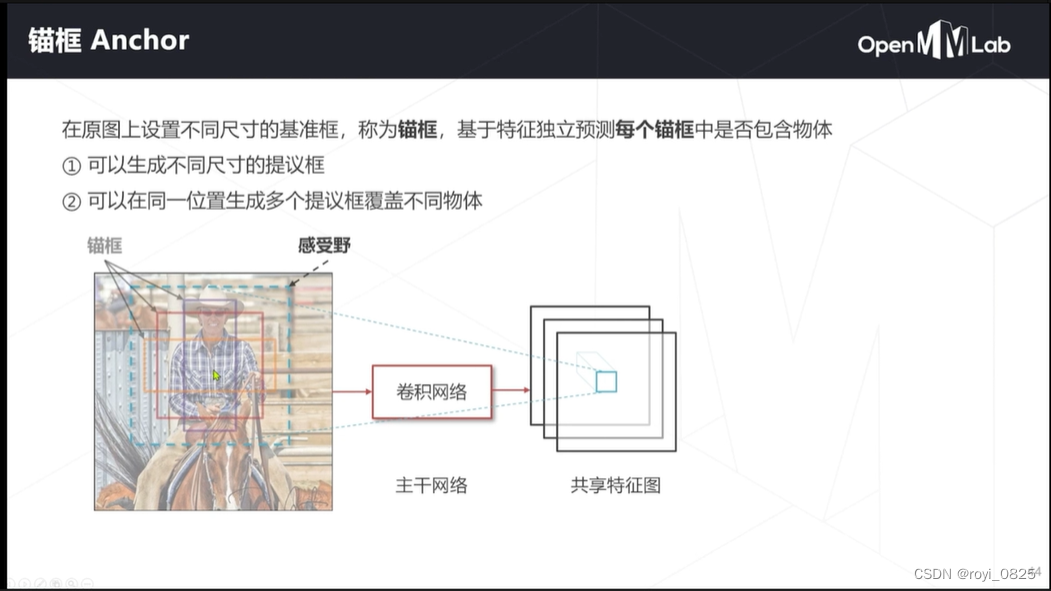
那么,这样一个工作能否扩展到多类呢?
把下图所示的二分类改成多分类的检测。

多分类有名的最早做出来的:YOLO,同时期SSD
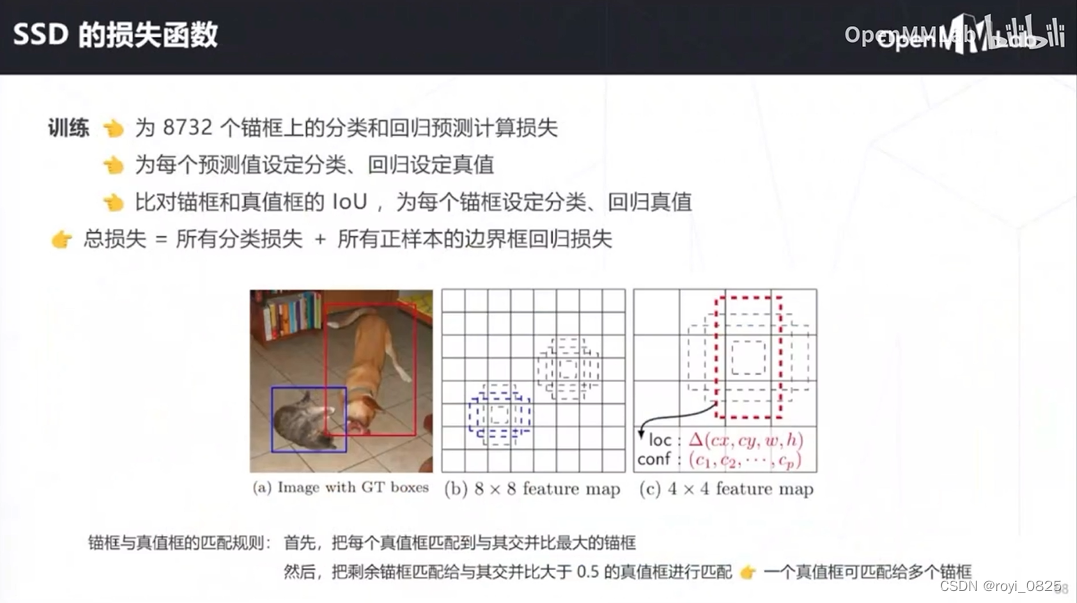
一阶段的问题:正负样本不均衡问题,漏检错检达不到平衡
目标检测中正负样本指的是模型自己预测出来的框与GT的IoU大于你设定的阈值即为正样本,
首先,检测问题中的正负样本并非人工标注的那些框框,而是程序中(网络)生成出来的框框,也就是faster rcnn中的anchor boxes以及SSD中在不同分辨率的feature map中的默认框,这些框中的一部分被选为正样本,一部分被选为负样本,另外一部分被当作背景或者不参与运算。
损失函数:focal loss:RetinaNet,解决问题。
无锚框算法:这是因为引入了多尺度的概念。
多尺度物体问题是指图像中存在多个不同大小的物体。这种情况可能对目标检测算法造成困难,因为算法可能难以确定如何适当地覆盖图像中的所有物体。如果图像中的物体大小不同,则使用固定大小的锚框可能无法很好地覆盖图像中的所有物体。例如,如果锚框太大,则可能覆盖到多个小物体;如果锚框太小,则可能遗漏大物体。因此,处理多尺度物体问题是目标检测中一个关键的挑战。
CerterNet:以中心点来表示物体
Detection Transformer(问题是收敛特别慢)
可以放到Transformer的框架下去做,产生最后框的预测。
密集预测是一个辅助方法,并不是端到端的。
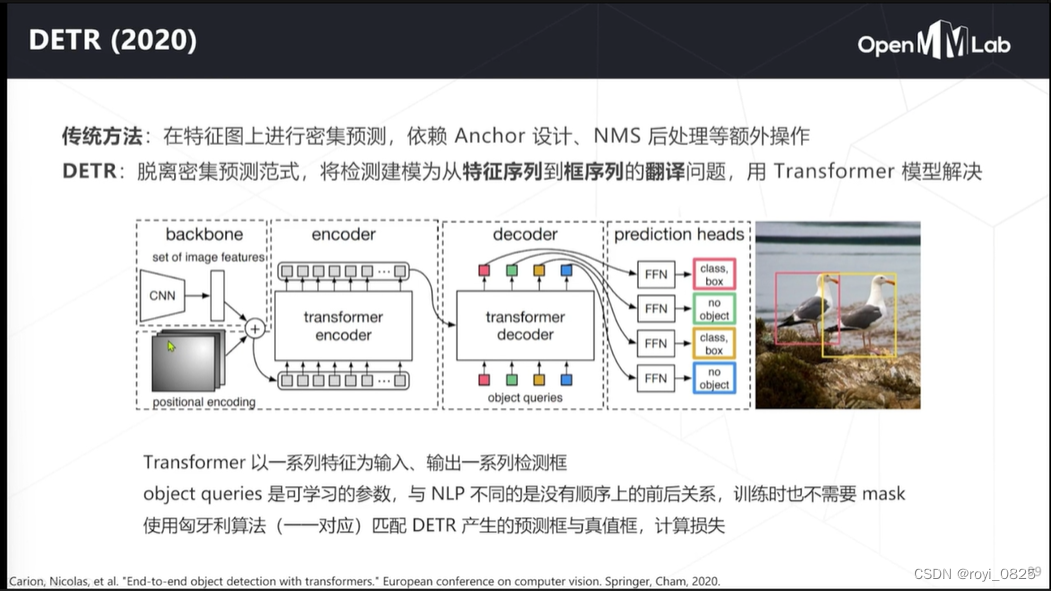
后面有了一种Deformable DETR,直接基于query feature,提高了收敛速度。
评估:评估这里和机器学习所用的评估方法是没什么区别的,TP,TN,FP,FN,PR曲线,AP值,召回率,准确率。















 3740
3740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









