







AdaBoost算法系列1
1 前言
跟踪方面有些经典的算法,前几天在研究Boris Babenko.和Ming-Hsuan Yang的文章"Robust Object Tracking with Online Multiple Instance Learning",2011,PAMI,其中Ming-Hsuan Yang大牛就不说了,在计算机视觉方面除了很多成果,具体可以在他的主页上去了解下,可以找到很多CVPR和PAMI上的牛文都出于他的指导。由于知识点上的薄弱,这篇文章只是看懂了一个大概,这里特别把其中涉及到的AdaBoost方面的内容进行一下学习总结。
Boosting翻译过来就是我们所说的提升算法,是一种常用的统计学习方法,应用广泛且有效,在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。我们先从它的历史说起,认识几个大牛人物,Leslie Valiant教授(2010年图灵奖得主)、Michael Kearns(Valiant教授的学生)、Robert Schapire教授(Boosting和AdaBoost的发明人,另一个合作者是
Yoav Freund),Schapire和Freund因为AdaBoost算法获得了2003年的哥德尔奖。
故事要从PAC(Probably Approximately Correct)说起,80年代的时候Valiant教授提出了PAC算法,当然他的学生Kearns也是有贡献的,PAC中译过来叫概率近似正确,研究的主要是一个问题什么时候是可以被学习的,涉及的应该是计算机理论知识方面的内容,我就没有去深入研究了,不过牛人Free Mind的一篇博文《机器学习物语(4):PAC Learn ability》对此做了一些解释,感兴趣的可以去参考下。Kearns和Valiant首先提出了“强可学习(strongly learnable)”和“弱可学习(weakly learnable)”的概念,指出:在PAC学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就可以称这个概念是强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么称这个概念是弱可学习的[1]。如果二者等价 ,那么只需找到一个比随机猜测略好的弱学习算法就可以将其提升为强学习算法 ,而不必寻找很难获得的强学习算法。也就是这种猜测,让无数牛人去设计算法来验证PAC理论的正确性。不过,很长的一段时间都没有一个切实可以的所谓的"一个多项式学习算法"来实现这个理想。直到Schapire和Freund在1996年提出了一个有效的算法才真正实现了这个夙愿,它的名字就叫做AdaBoost。Schapire证明了“强可学习”与“弱可学习”等价的,也就是说在PAC学习的框架下,一个概念的强可学习的充分必要条件是这个概念是弱可学习的。这样一来问题便成为了:如果已经发现了“弱学习算法”,那么能否将它提升为“强学习算法”,大家知道,发现弱学习算法通常比发现强学习算法容易得的多,对于分类问题而言,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易得多[1]。那么具体如何提升,便成为了提升算法要解决的问题,也因此发展了很多的提升算法,代表性的便是AdaBoost算法。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类器。大多数的提升算法是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。这样对于提升方法来说就有两个问题需要回答:一是在每一轮如何改变训练数据的权值或概率分布;二是如何将弱分类器组合成一个强分类器。关于第一个问题,AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值加大而受到后一轮的弱分类器的更大关注。第二个问题,AdaBoost采取的是加权多数表决的方法,即加大分类误差率小的弱分类器权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。下面就具体讲下用数学表达式是怎么实现的。
(***实际上,在提升算法之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boosttrapping方法和bagging方法,但是这两种方法都只是将分类器进行简单的组合,实际上并没有发挥出分类器组合的威力。***)
2. AdaBoost的数学表达
假设给定一个二类分类的训练数据集

输入:训练数据集;
输出:最终分类器G(X)


对于上述公式的说明与理解:
(1)假设训练数据集具有均匀的权值分布,即N个样本,每个样本的权重值为1/N,每个训练样本在基本分类器的学习中作用相同,这一假设保证第1步能够在原始数据上学习第一个基本弱分类器。
(2)由每轮循环学习到的弱分类器,计算在训练数据集上的分类误差率,I(X)是一个指示函数(假设有一个集合,X属于A则I(X)等于1,否则为0),在分类误差率的计算公式中表示的意思就是X属于错误分类集合中的时候I(X)为1,这样,分类误差率其实就是被弱分类器误分类样本的权值之和,这样可以看出数据的权值分布D和弱分类器G的分类误差率的关系。且由于权值进行了归一化的处理,所以有:

(3)计算弱分类器的系数是通过分类误差率计算而来,由计算公式可知,当分类误差率e小于等于1/2时,系数大于等于0,并且系数随着e的减少而增大,也即分类误差率越小的弱分类器在最终分类器中的权重越大。
(4)权值更新,对于一个+1和-1的二分类器,公式可以改写成:
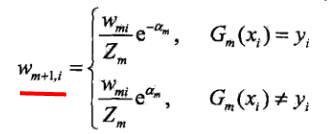
这样,有常指数函数的值可以知道误分类的样本值(公式下面的值)在系数大于0的时候,要大于正确分类的样本的权值(公式上面的值)。且误分类样本的权值在扩大,正确分类样本的权值在减小,两者的增大的其实增大与减小之和,为e/(1-e)。注意,系数大于0的条件是分类误差率e小于1/2,而e/(1-e)在e大于0小于1/2的时候是随着e的增大而增大的,所以说分类误差率越小,权值的变化就越小。不改变所给训练数据,而不断改变训练数据权值的分布,使得训练数据在弱分类器的学习中起不同的作用,这是AdaBoost的一个特点。
3. 一个例子
这里取自[1]中的一个例子,我觉得讲的非常好,大家可以实际计算下,这样可以增强理解。




4. AdaBoost几乎不会过拟合
AdaBoost的优点还是很多的,精度比较高,还可以在训练弱分类器的过程中选择不同的方法,AdaBoost其实提供的只是一个框架,最主要的是几乎不用担心过拟合。其实在90年代末的时候,大家都对于AdaBoost为什么会如此好迷惑不解,直到1999年,另一个大牛Friedman的一篇论文"Additive Logistic Regression: A Statistical View of Boosting",解释了大部分的疑惑,但是没有解释为什么AdaBoost不容易过拟合,而且这个问题至今好像都还没有定论。
后面还将继续对AdaBoost进行进一步扩展讲解。
[1] 李航,《统计学习方法》,8.1.1















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









