







后缀数组(Suffix Array)是某一字符串的所有后缀按照字典序的一个排列。本文数组的索引从0开始。称s[j..len(s)-1]为后缀j。sa[i] = j,表示原串的所有后缀按字典序排列,排在第i个的是后缀j。一个字符串的后缀数组是唯一的。
sa根据排名查后缀编号,与之对应的是rank数组,根据后缀编号查排名。sa[i] = j <=> rank[j] = i。
给后缀排序有什么作用呢?一个字符串的所有子串,都可以表示为它某个后缀的前缀。对于一个有序的序列,我们可以二分查找。设文本串的长度为n,模板串的长度为m。直接二分,可以做到O(n lg n)+O(m lg n)的时间复杂度。用height数组进行优化,则可以做到O(n lg n)+O(m+lg n)。height是后缀数组中相邻两个后缀的最长公共前缀。
后缀数组的构造
从上一段可以看出,我们能用O(n lg n)的时间构造一个字符串的后缀数组——倍增算法。存在O(n)的算法,在OI中似乎不常用。
给数排序有很多方法。基于比较的排序,最快可做到O(n lg n),理论上不能进一步优化。在我们的模型中,数之间的比较是O(1)的,然而,字符串的比较是O(n)的。所以,我们得另辟蹊径。
除了基于比较的排序,我们还有计数排序、基数排序等。字符串的集合太大,计数排序不可行。但是字符集往往很小,我们应该试试基于计数排序的基数排序。每次计数排序用时O(n),进行n轮计数排序,总共是O(n^2),仍然不理想。
字典序有什么特性?把s和t都拆成[0..i],[i+1..len-1]两截,则s < t <=> (s[0..i] < t[0..i]) 或 (s[0..i] = t[0..i] 且 s[i+1..len(s)-1] < t[i+1..len(t)-1])。从中看出两点:一,我们可以递归或者递推地比较两个字符串;二,这和二元组之间的比较很像!
设sa_k为只取每个后缀的前缀k得到的“后缀数组”,rank_k类似。我们能根据它们计算出sa_2k和rank_2k。图示如下:

取二元组(rank_k[i], rank_k[i+k])为后缀i的关键字排序,就得到了sa_2k。相当于rank_k能帮助我们快速地比较两个后缀。再根据sa_2k计算出rank_2k。如果i+k越界怎么办?我采用的方法是令它的rank等于-1。后面,我们将看到,置rank[n]=-1即可。
如果用快速排序,至此,我们已经得到O(n lg^2 n)构造后缀数组的算法。
rank的取值范围是0~n-1,统计一下每个rank对应多少个后缀是可接受的,能不能用先前提到的基数排序呢?基数排序从低位到高位循环,每一趟以这一位为关键字采用某种稳定排序算法(如计数排序)排序,最后就得到了有序的序列。以上面banana例子中k=4时的二元组为例:
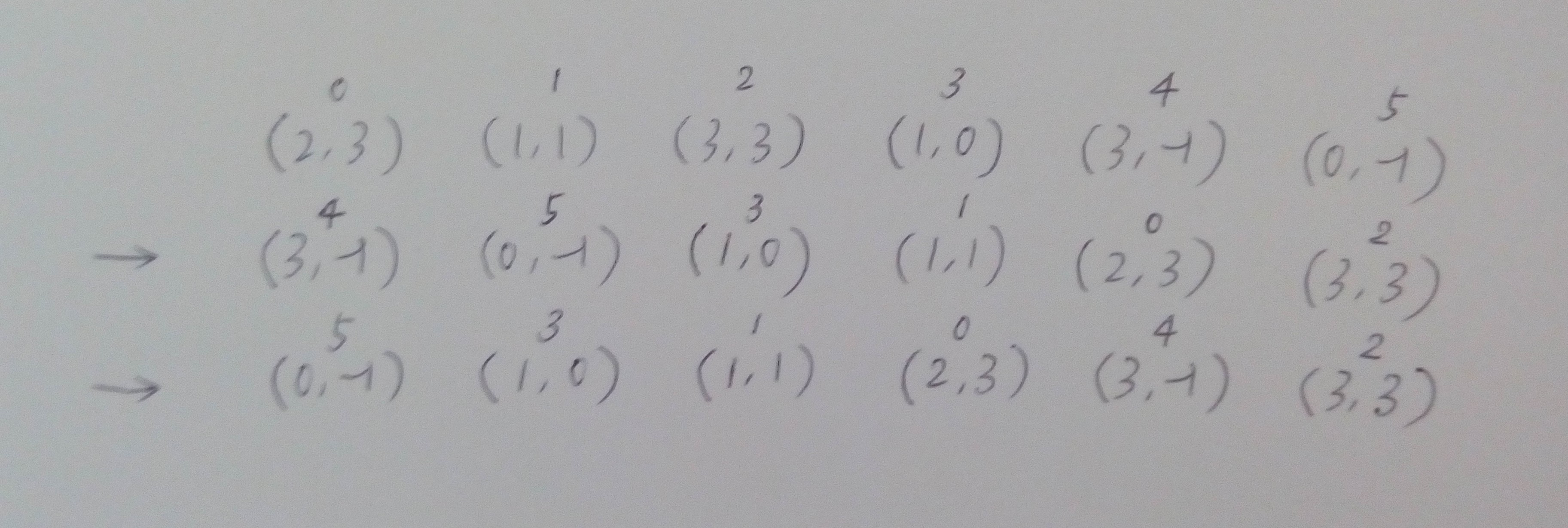
Pretty cool !
一种简单的实现方法是,以rank_k[i+k]为关键字,对所有后缀计数排序,得到pre。再以rank_k[i]为关键字,对pre计数排序,得到sa_2k。
有没有可以优化的地方?
sa_k是什么?以rank_k[i]为关键字,对所有后缀排序的结果。现在取rank_k[i+k]为关键字,对于那些满足i+k < n的后缀,它们的先后顺序保持不变,而对于那些i+k >= n的后缀,根据上面的约定,其第二关键字等于-1,应该排在pre的最前面。所以,我们可以直接从sa_k得到pre。
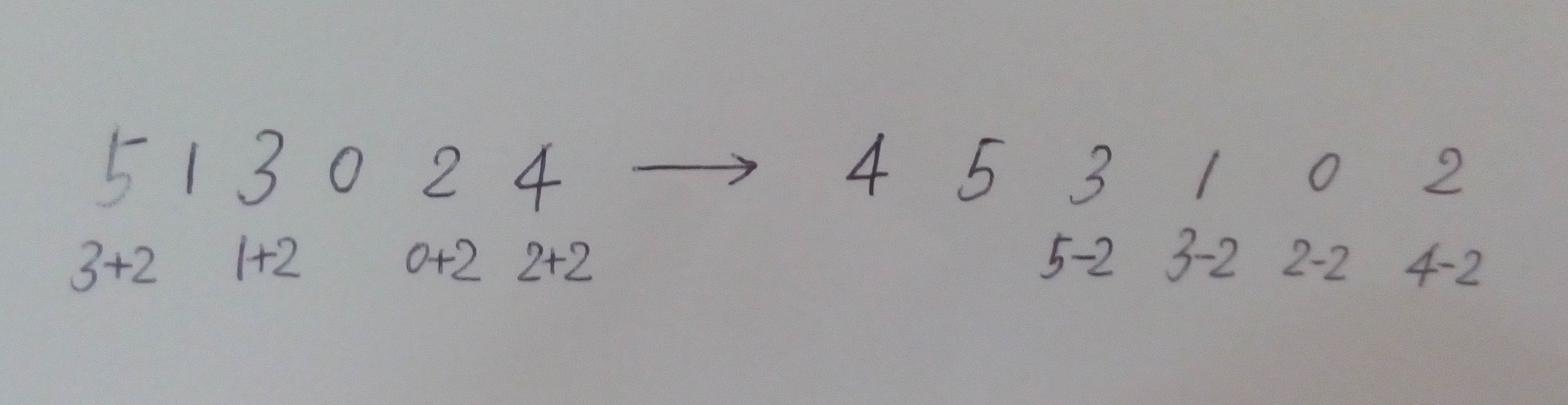
开始写代码吧。以下代码仅作说明之用,为了叙述方便打乱了顺序。
#include <cstring>
#include <algorithm>
void build_SA(char s[], int n)
{
memset(b, 0, sizeof(int)*SIGMA_SIZE);
for (int i = 0; i < n; ++i)
++b[s[i]-'a'];
for (int i = 1; i < SIGMA_SIZE; ++i)
b[i] += b[i-1];
for (int i = n-1; i >= 0; --i)
sa[--b[s[i]-'a']] = i;
int m = rank[sa[0]] = 0;
for (int i = 1; i < n; ++i)
rank[sa[i]] = m += s[sa[i]] != s[sa[i-1]];
++m;这一段求出sa_1和rank_1。假定SIGMA_SIZE > MAX_N。如果字符集比较大,std::sort即可,不影响渐近的运行时间。m是不同rank的种数。
int *&pre = t;
for (int k = 1; m < n; k *= 2, ++m) {
for (int i = 0, p = k; i < n; ++i)
if (sa[i] >= k)
pre[p++] = sa[i]-k;
for (int i = 0; i < k; ++i)
pre[i] = n-k+i;这一段求出pre。t是一个指针,定义为全局变量。
int b[MAX_N], buff[2][MAX_N+1], *t = buff[0];接下来根据第一关键字计数排序。
memset(b, 0, sizeof(int)*m);
for (int i = 0; i < n; ++i)
++b[rank[i]];
for (int i = 1; i < m; ++i)
b[i] += b[i-1];
for (int i = n-1; i >= 0; --i)
sa[--b[rank[pre[i]]]] = pre[i];至此,已求出新的sa。接着,我们来计算rank。
m = r[sa[0]] = 0;
for (int i = 1; i < n; ++i)
r[sa[i]] = m += rank[sa[i]] != rank[sa[i-1]] || rank[sa[i]+k] != rank[sa[i-1]+k];
swap(r, rank);
}r是一个中间“数组”。这时pre数组已经没用了,所以它们可以共用一块内存。rank也定义为指针。
int *&pre = t, *&r = t;现在可以看到定义数组指针的用意。无须copy,无须memcpy,swap即可。DP里搞滚动数组也可以借鉴这个技巧。
int b[MAX_N], sa[MAX_N], buff[2][MAX_N+1], *t = buff[0], *rank = buff[1];别忘了在for k外面加上这句!
rank[n] = r[n] = -1;两个后缀i、j,设i < j。若j+k <= n,则rank[i+k]和rank[j+k]有定义。若j+k > n,则必有rank[j] < rank[i],根据短路法则,无须再比较rank[i+k]和rank[j+k]。
最后,还有:
}最长公共前缀
设后缀sa[i]和sa[j]的最长公共前缀为LCP(i, j),有定理:LCP(i, j) = min{height[k] | min{i, j} < k <= max{i, j}}。
一开始,刘汝佳告诉我这很显然,我是拒绝的。然而现在我也想建议大家使用显然法……
还是证一下吧。先证一个引理,设i < k <= j,则LCP(i, j) = min{LCP(i, k), LCP(k, j)}。当k = j时显然成立。以下说明k < j时的情形。
设LCP(i, k)=a,LCP(j, k)=b,LCP(i, j)=c,sa[i]=x,sa[j]=y,sa[k]=z,不妨设a <= b。那么,s[x..x+a-1] = s[z..z+a-1],s[z..z+b-1] = s[y..y+b-1],由传递性,s[x..x+a-1] = s[y+a-1..y+a-1],故LCP(i, j) >= a。由字典序的定义,后缀数组中i~k项后缀的前c个字符相等,故a >= LCP(i, j)。证毕。
结合这个引理和数学归纳法,上述定理成立。
所以说height数组很重要啦。有了它,再求求RMQ,任意两后缀的最长公共前缀就搞定了。
上面这个定理有个推论,帮我们线性时间求height:height[rank[i]] >= height[rank[i-1]]-1。后缀i和i-1,拿掉i-1的第一个字符,二者就相等了。考虑sa[rank[i-1]-1]=p-1,则后缀p-1<后缀i-1。如果它俩的第一个字符相等,那么,有后缀p < 后缀i,由定理,有height[rank[i-1]]-1 = LCP(sa[p], sa[i]) <= height[rank[i]]。如果它俩的第一个字符不等,则height[rank[i-1]] = 0,显然成立。推论得证。
height[rank[i]]相对于前一项只能增加或减1,最多累计减少(n-1)个1,且height[rank[i]] <= n。于是,按照height[rank[0]], height[rank[1]], height[rank[2]], …的顺序愉快地递推吧!
UOJ #35是一道模板题,我的代码:http://uoj.ac/submission/93286。
写在最后
后缀数组最初是从兄弟学校的MYJ学长那里学的。研究了一下刘汝佳老师的代码,然后默写了一遍……UOJ #35始终是0分,CodeVS的模板题过了。那时我还没发现UOJ可以看一部分数据啊……我自己也不太清楚自己在写什么,这就是照着别人代码打的坏处。但是自己写不出来啊。于是这个数据结构和莫队算法等等在今年1~4月于匆忙中囫囵吞枣的知识一样,属于不可用的。
这次是自己重新写的,但心底里对于以前的代码还是有个模糊的印象。根据刘汝佳老师的代码修改的。有两个地方比我更优:一是他通过共用pre和r(原代码变量名不一样),只用4n的空间;二是引入m变量。
本文参考了刘汝佳、陈锋编著的《算法竞赛入门经典训练指南》和国家集训队2004年许智磊前辈的《后缀数组》一文。
如有不当之处,欢迎指正~















 275
275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









