








动机
创建Parquet是利用压缩性,高效的列式存储来在Haddop生态圈任何项目中应用.
记住Parquet是构建在复杂嵌套的数据结构, 并且使用记录分解和集成的算法在Dremely论文中描述.我们相信这种方法是更强大的的可以非常简单的使嵌套命令空间的扁平化.
Parquet构建可以非常高效的压缩和编程结构.多个项目已经证明了应用正确的压缩与编码结构对项目的性能是多大的影响.Parquet允许压缩的结构指定到列层次,并且未来允许增加开发或实现的更多的编码.
Parquet被任何构建.Hadoop生态是一个丰富的数据处理框架,并且我们不感兴趣也没有偏向.我们相信高效,容易实现的列式存储,底层对所有框架应该是不需要花费大量的扩展和非常难的设置依赖.
模块
parquet-format 项目包含格式说明并且Thrift定义的元数据需要严格的说明在Parquet文件中.
parquet-mr 包含多个子项目,它实现核心元件的读和写一个嵌套,面向列的流数据,对核心到parquet格式,并且提供Hadoop 输入/输出格式,Pig加载器和其它基于Java工具交互的Parquet.
parquet-cpp 项目 是C++库可以读写Parquet文件
parquet-rs 项目是Rust 库来读写Parquet文件
parquet-compatibility 项目包含兼容测试,可以核对实现不同语言读写文件.
构建
Java资源可以编译用 mvn package. 当前稳定版本应该用Maven库中心包.
C++ thrift资源用make来生成
Thrift 也能编码到任何其它支持thrift的语言中
发版.
术语
Block(HDFS块):表示hdfs上的一个块,也描述这是一个不能改变的文件格式.这个文件被设计在hdfs上运行的非常好.
File:hdfs文件一定包含本文件的元信息.它实现上不必需要包含数据.
行组: 一个水平逻辑数据的一行. 没有物理结构来保证一个行组.在数据集中一个行组由每个列的一个列块来组成.
列块: 一个块数据是列的一部分.它位保存在指定的行组中,并且被一个连续的文件保护.
页: 列块被分割到页中.一页是不可分割单位的概念(包含压缩和编码). 可以多个页类型插入到同一个列块中.
分层的说,一个文件可以包含一个或多个行组.一个行组可以包含至少每个列一个列块.列块包含一个或更多页.
并且单元
- MapReduce - 文件/行组
- IO - 列块
- 编码/压缩 - 页
文件格式
文件和thrift定义应该被读一起可以明白里边格式.
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata
4-byte magic number "PAR1"上面例子中,在表中有N个列,被切分成M个行组.文件元数据包含列元数据的起始位置.更多包含在元数据的细节可以在thrift文件找到.
当数据允许单独写之后元数据被写.
读者期待刚读认为元数据就可以找到所有他们感兴趣的列块.万块应该顺序的读.
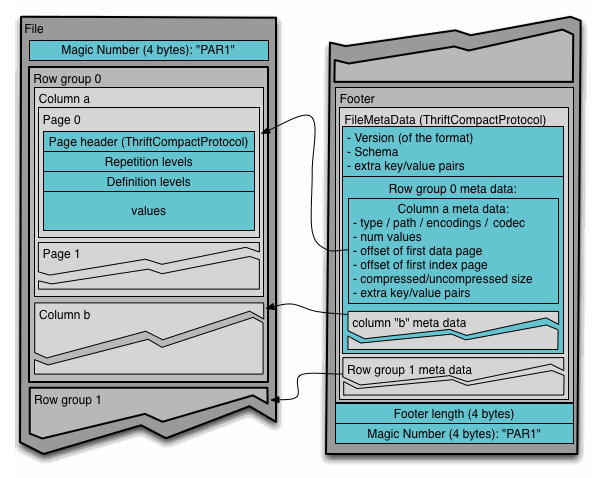
元数据
有三个类型的元数据:文件元数据,列(块) 元数据和页元数据.所有的thrift结构是TCompactProtocol用序列化.
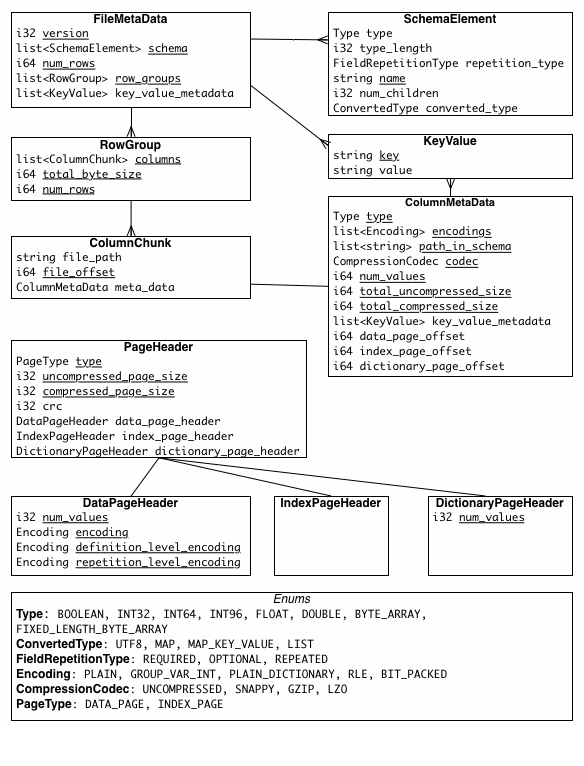
...















 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









