







目录
HTTP的连接管理
HTTP 协议最初(0.9/1.0)是个非常简单的协议,通信过程采用了简单的“请求 - 应答”方式。它底层的数据传输基于 TCP/IP,每次发送请求前需要先与服务器建立连接,收到响应报文后会立即关闭连接。因为客户端与服务器的整个连接过程很短暂,不会与服务器保持长时间的连接状态,所以就被称为“短连接”(short-lived connections)。早期的 HTTP 协议也被称为是“无连接”的协议。
短连接的缺点相当严重,因为在 TCP 协议里,建立连接和关闭连接都是非常耗费资源的操作。TCP 建立连接要有“三次握手”,发送 3 个数据包,需要 1 个 RTT;关闭连接是“四次挥手”,4 个数据包需要 2 个 RTT。而 HTTP 的一次简单“请求 - 响应”通常只需要 4 个包,如果不算服务器内部的处理时间,最多是 2 个 RTT。
短连接举个例子:上班打卡需要打开打卡机的盖子(花费1秒钟),实际打卡只需要0.1秒钟,然后关闭盖子(花费5秒钟)。下一个人继续重复这样的操作,大部分时间都浪费在了开关盖子上。
针对短连接暴露出的缺点,HTTP 协议就提出了“长连接”的通信方式,也叫“持久连接”(persistent connections),用的就是“成本均摊”的思路,既然 TCP 的连接和关闭非常耗时间,那么就把这个时间成本由原来的一个“请求 - 应答”均摊到多个“请求 - 应答”上。这样虽然不能改善 TCP 的连接效率,但如果在这个长连接上发送的请求越多,分母就越大,利用率也就越高。
长连接举个例子:上班的时候打开盖子,然后所有人开始打卡,下班后再关闭盖子。
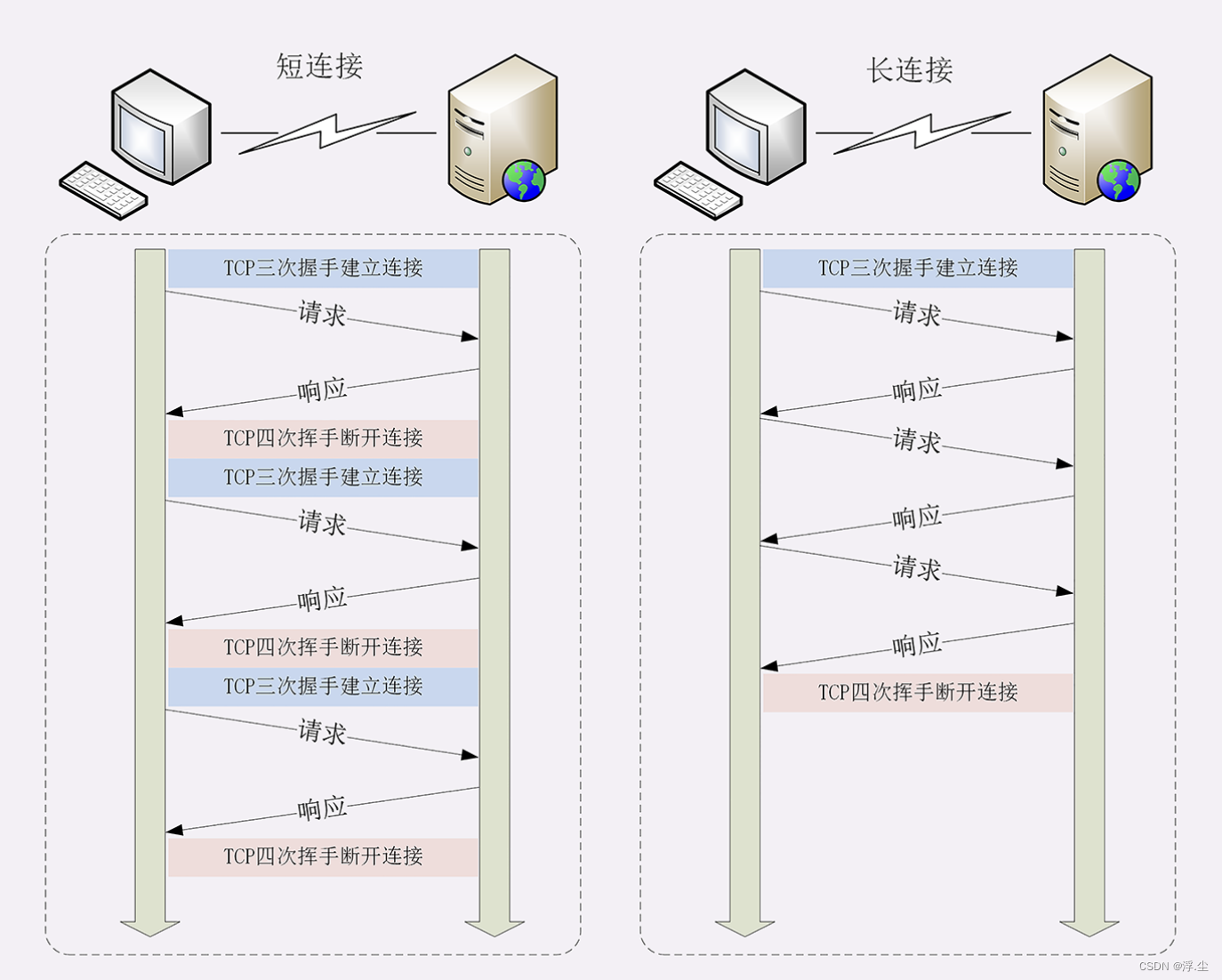
由于长连接对性能的改善效果非常显著,所以在 HTTP/1.1 中的连接都会默认启用长连接,不需要用什么特殊的头字段指定,只要向服务器发送了第一次请求,后续的请求都会重复利用第一次打开的 TCP 连接。也可以在请求头里明确地要求使用长连接机制,使用的字段是Connection,值是“keep-alive”。不过不管客户端是否显式要求长连接,如果服务器支持长连接,它总会在响应报文里放一个 “Connection: keep-alive” 字段,告诉客户端:“我是支持长连接的,接下来就用这个 TCP 一直收发数据吧”。
为了防止内存耗尽,长连接需要在恰当的时间关闭,不能永远保持与服务器的连接,这在客户端或者服务器都可以做到。
-
客户端可以在请求头里加上“Connection: close”,告诉服务器:“这次通信后就关闭连接”。服务器看到这个字段,就知道客户端要主动关闭连接,于是在响应报文里也加上这个字段,发送之后就调用 Socket API 关闭 TCP 连接。
-
另外,客户端和服务器都可以在报文里附加通用头字段“Keep-Alive: timeout=value”,限定长连接的超时时间。但这个字段的约束力并不强,通信的双方可能并不会遵守,所以不太常见。
-
服务器端通常不会主动关闭连接,但也可以使用一些策略:
服务器Nginx对长连接的处理方式:
-
使用“keepalive_timeout”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
-
使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当 Nginx 在这个连接上处理了 1000 个请求后,也会主动断开连接。
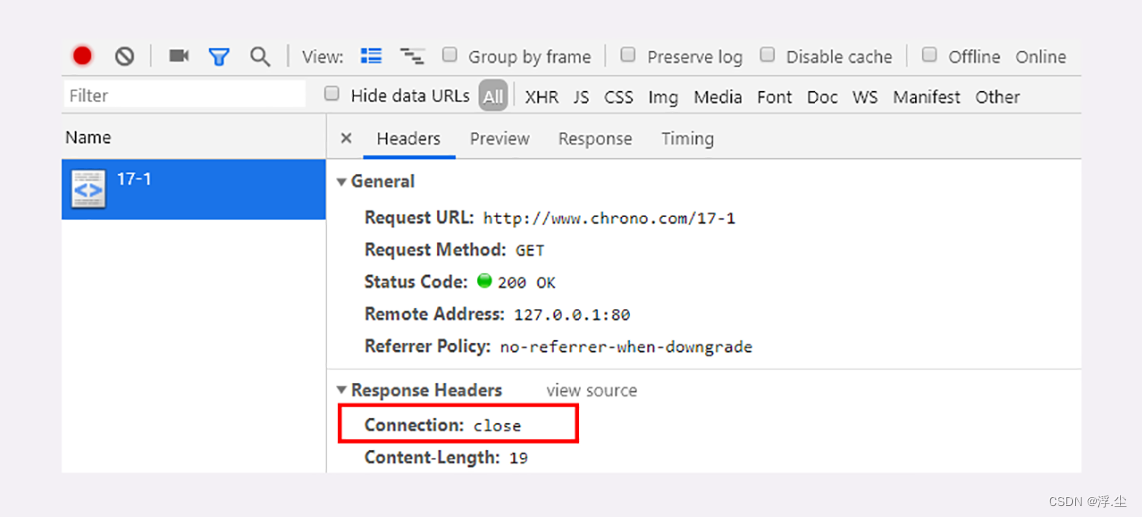
数据测试:配置“keepalive_timeout 60”和“keepalive_requests 5”,意思是空闲连接最多 60 秒,最多发送 5 个请求。
所以,如果连续刷新五次页面,就能看到响应头里的“Connection: close”了。
队头阻塞
“队头阻塞” 与短连接和长连接无关,而是由 HTTP 基本的“请求 - 应答”模型所导致的。因为 HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求没有轻重缓急的优先级,只有入队的先后顺序,排在最前面的请求被最优先处理。如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本。
再举个例子:大家排队打卡,突然打卡机故障,导致后面排队的人全都等到这,然后全都迟到了。
“队头阻塞”问题在 HTTP/1.1 里无法解决,只能缓解。
-
缓解的办法1(不推荐):“并发连接”(concurrent connections),也就是同时对一个域名发起多个长连接,用数量来解决质量的问题。举个例子:多买几个打卡机。但是会存在连接数被滥用的情况。
-
缓解的办法2(推荐):使用“域名分片”(domain sharding)技术,用数量来解决质量的思路。HTTP 协议和浏览器有限制并发连接数量,那就多开几个域名,比如 shard1.test.com、shard2.test.com,而这些域名都指向同一台服务器 www.test.com,这样实际长连接的数量就又上去了。举个例子:多开几个打卡机,每个楼层、办公区的入口也放上三四台打卡机,把人进一步分流,不要都往前台挤。
关于重定向
客户端点击超链接发起的跳转称为:主动跳转,服务器自发的跳转称为:重定向。301 是“永久重定向”,302 是“临时重定向”,浏览器收到这两个状态码就会跳转到新的 URI。如果不用开发者工具的话,你是完全看不到这个跳转过程的,也就是说,重定向是“用户无感知”的。
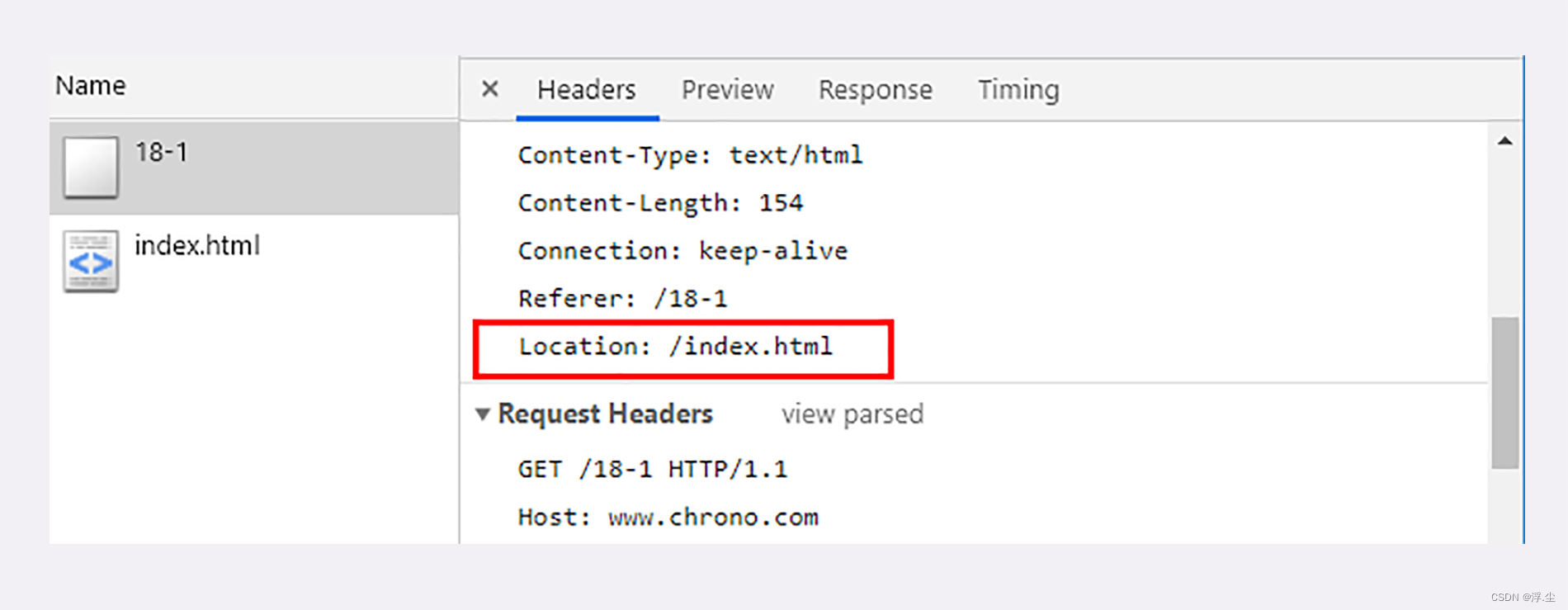
重定向前的响应字段 “Location”标记了服务器要求重定向的 URI,这里就是要求浏览器跳转到“index.html”。浏览器收到 301/302 报文,会检查响应头里有没有“Location”。如果有,就从字段值里提取出 URI,发出新的 HTTP 请求,相当于自动替我们点击了这个链接。这里的Location可以使用绝对URI也可以使用相对URI。
重定向状态码:除了上面的301和302,还有下面集中不常用的,部分浏览器可能支持的不够好。
303 See Other:类似 302,但要求重定向后的请求改为 GET 方法,访问一个结果页面,避免 POST/PUT 重复操作;
307 Temporary Redirect:类似 302,但重定向后请求里的方法和实体不允许变动,含义比 302 更明确;
308 Permanent Redirect:类似 307,不允许重定向后的请求变动,但它是 301“永久重定向”的含义。
什么时候需要重定向?
-
一个最常见的原因就是“资源不可用”,需要用另一个新的 URI 来代替。例如域名变更、服务器变更、网站改版、系统维护,这些都会导致原 URI 指向的资源无法访问,为了避免出现 404,就需要用重定向跳转到新的 URI。
-
另一个原因就是“避免重复”,让多个网址都跳转到一个 URI,比如访问旧域名跳转到新域名。
301 和 302的使用场景区分:
-
301:如果域名、服务器、网站架构发生了大幅度的改变,比如启用了新域名、服务器切换到了新机房、网站目录层次重构,这些都算是“永久性”的改变。原来的 URI 已经不能用了,必须用 301“永久重定向”,通知浏览器和搜索引擎更新到新地址,这也是搜索引擎优化(SEO)要考虑的因素之一。
-
原来的 URI 在将来的某个时间点还会恢复正常,常见的应用场景就是系统维护,把网站重定向到一个通知页面,告诉用户过一会儿再来访问。另一种用法就是“服务降级”,比如在双十一促销的时候,把订单查询、领积分等不重要的功能入口暂时关闭,保证核心服务能够正常运行。
重定向需要注意的问题:
-
第一个问题是“性能损耗”,不可滥用。站内重定向还好说,可以长连接复用,站外重定向就要开两个连接,如果网络连接质量差,那成本可就高多了,会严重影响用户的体验。
-
第二个问题是“循环跳转”。如果重定向的策略设置欠考虑,可能会出现“A=>B=>C=>A”的无限循环,不停地在这个链路里转圈圈。所以 HTTP 协议特别规定,浏览器必须具有检测“循环跳转”的能力,在发现这种情况时应当停止发送请求并给出错误提示:重定向次数过多。
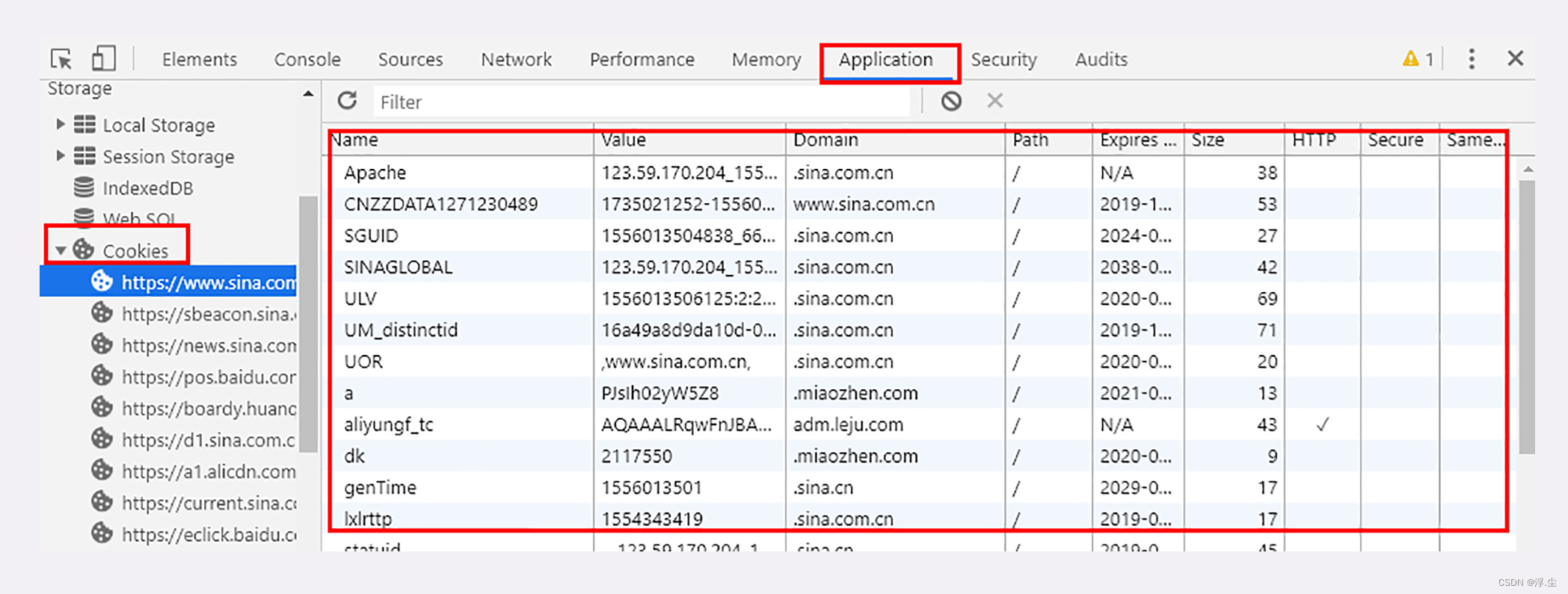
cookie
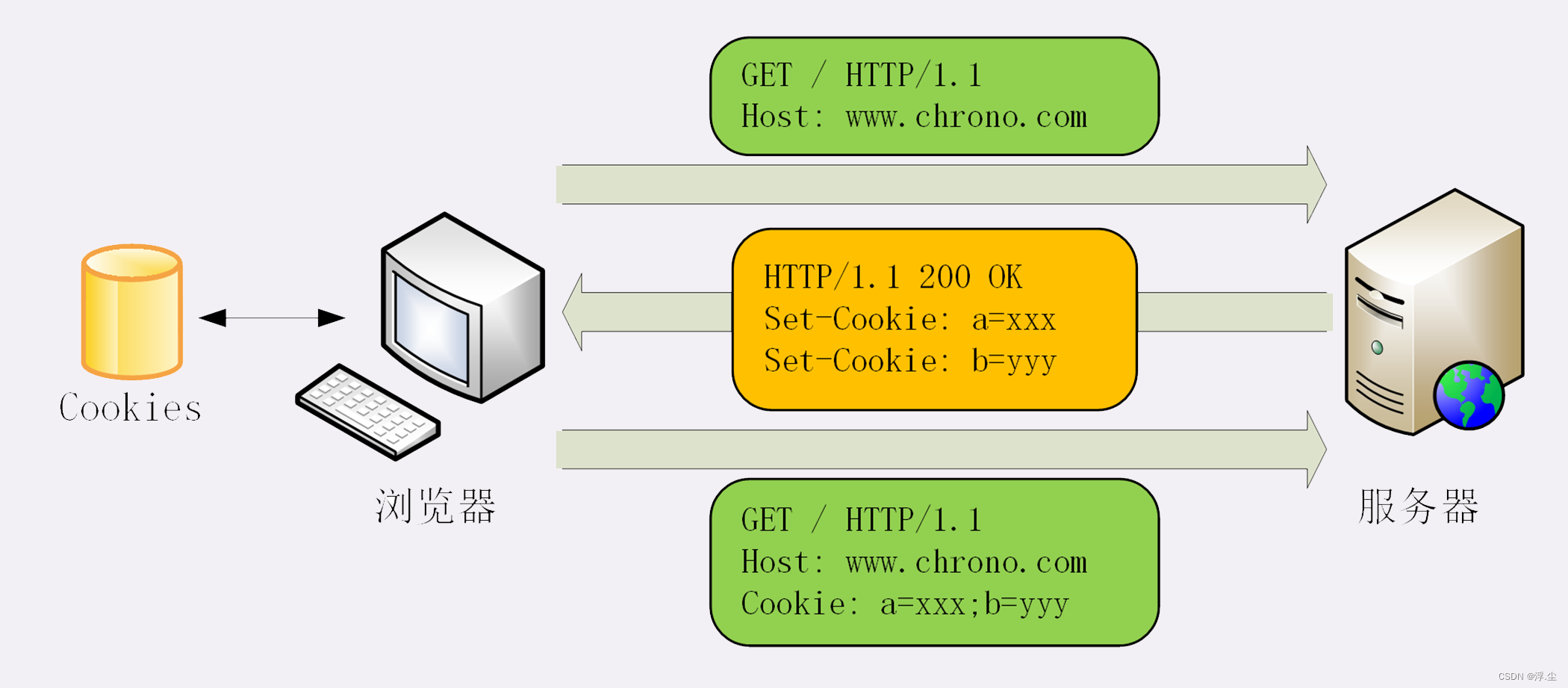
解决HTTP无状态的问题:使用cookie。要用到两个字段:响应头字段Set-Cookie和请求头字段Cookie。服务器有时会在响应头里添加多个 Set-Cookie,存储多个“key=value”。但浏览器这边发送时不需要用多个 Cookie 字段,只要在一行里用“;”隔开就行。Cookie 是由浏览器负责存储的,而不是操作系统。所以,它是“浏览器绑定”的,只能在本浏览器内生效。
【Cookie 的属性】
1、应该设置 Cookie 的生存周期,也就是它的有效期,可以使用 Expires 和 Max-Age 两个属性来设置。
“Expires”俗称“过期时间”,用的是绝对时间点,可以理解为“截止日期”(deadline)。
“Max-Age”用的是相对时间,单位是秒,浏览器用收到报文的时间点再加上 Max-Age,就可以得到失效的绝对时间。
Expires 和 Max-Age 可以同时出现,两者的失效时间可以一致,也可以不一致,但浏览器会优先采用 Max-Age 计算失效期。
如果Max-Age 属性设置为 0,服务器0秒就让Cookie失效,即立即失效,服务器不存Cookie。
2、需要设置 Cookie 的作用域,让浏览器仅发送给特定的服务器和 URI,避免被其他网站盗用。“Domain”和“Path”指定了 Cookie 所属的域名和路径,使用这两个属性可以为不同的域名和路径分别设置各自的 Cookie。
比如“xxx.com/19-1”用一个 Cookie,“xxx.com/19-2”再用另外一个 Cookie,两者互不干扰。
不过现实中为了省事,通常 Path 就用一个“/”或者直接省略,表示域名下的任意路径都允许使用 Cookie,让服务器自己去挑。
3、设置Cookie 的安全性,尽量不要让服务器以外的人看到。
* 在JS脚本里可以用document.cookie来读写Cookie数据,有可能会导致“跨站脚本”(XSS)攻击窃取数据。
* 属性“HttpOnly”会告诉浏览器,此 Cookie 只能通过浏览器 HTTP 协议传输,禁止其他方式访问,浏览器的 JS 引擎就会禁用 document.cookie 等一切相关的 API,脚本攻击也就无从谈起了。
* 另一个属性“SameSite”可以防范“跨站请求伪造”(XSRF)攻击,设置成“SameSite=Strict”可以严格限定 Cookie 不能随着跳转链接跨站发送,而“SameSite=Lax”则略宽松一点,允许 GET/HEAD 等安全方法,但禁止 POST 跨站发送。
* 还有一个属性叫“Secure”,表示这个 Cookie 仅能用 HTTPS 协议加密传输,明文的 HTTP 协议会禁止发送。但 Cookie 本身不是加密的,浏览器里还是以明文的形式存在。
【cookie的应用场景】
1、身份识别,保存用户的登录信息,实现会话事务。
2、广告跟踪。
很多的广告图片,这些图片背后都是广告商网站(例如 Google),它会“偷偷地”给你贴上 Cookie 小纸条,这样你上其他的网站,别的广告就能用 Cookie 读出你的身份,然后做行为分析,再推给你广告。这种 Cookie 不是由访问的主站存储的,所以又叫“第三方 Cookie”(third-party cookie)。
缓存控制
HTTP 传输的每一个环节基本上都会有缓存,非常复杂:
-
浏览器发现缓存无数据,于是发送请求,向服务器获取资源;
-
服务器响应请求,返回资源,同时标记资源的有效期;
-
浏览器缓存资源,等待下次重用。
【服务器缓存的字段说明】
-
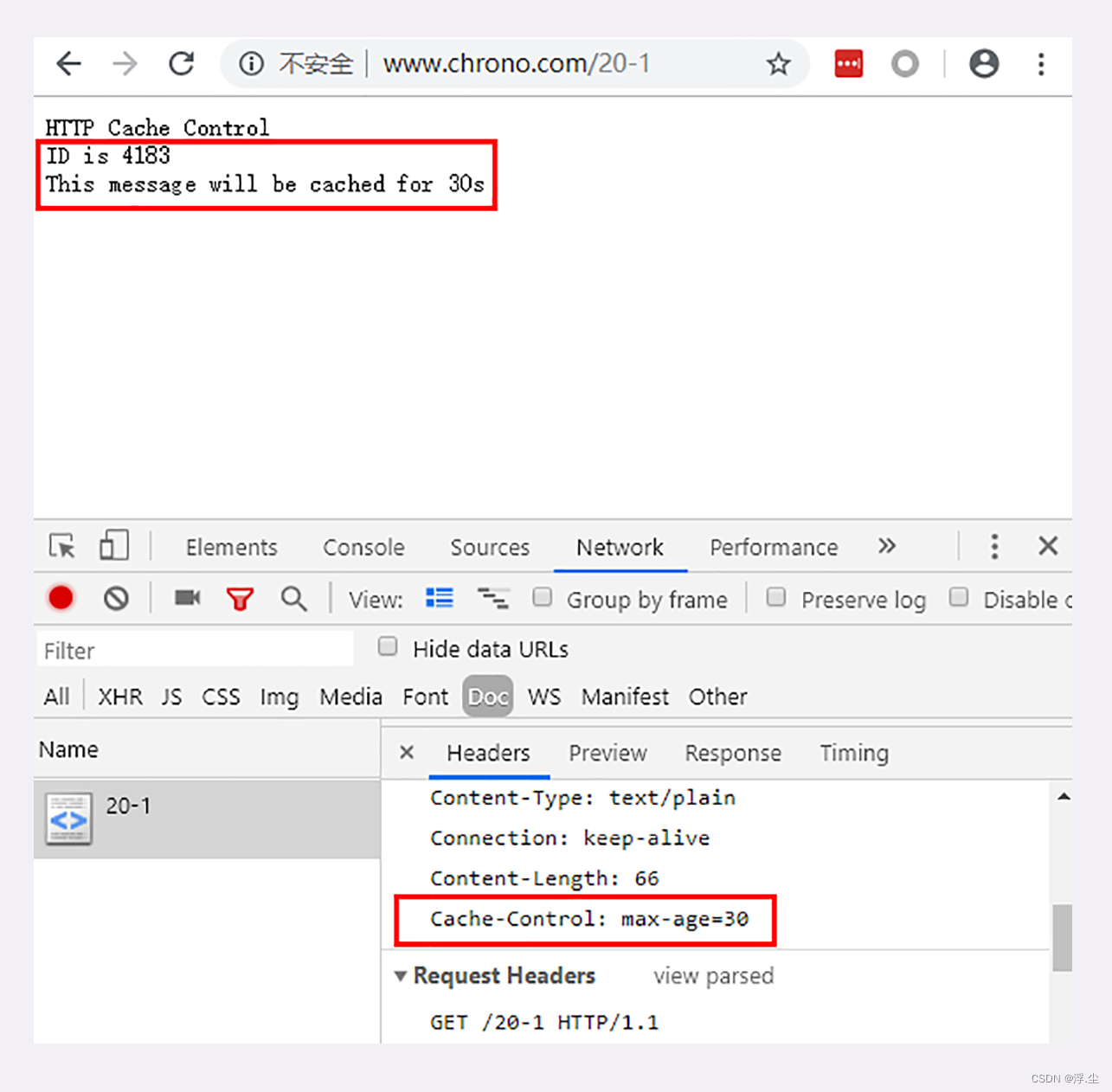
服务器标记资源有效期使用的头字段是“Cache-Control”,里面的值“max-age=30”就是资源的有效时间,相当于告诉浏览器,“这个页面只能缓存 30 秒,之后就算是过期,不能用。”,这个时间的计算起点是响应报文的创建时刻(即 Date 字段,也就是离开服务器的时刻),而不是客户端收到报文的时刻。
-
no_store:不允许缓存,用于某些变化非常频繁的数据,例如秒杀页面;
-
no_cache:它的字面含义容易与 no_store 搞混,实际的意思并不是不允许缓存,而是可以缓存,但在使用之前必须要去服务器验证是否过期,是否有最新的版本;
-
must-revalidate:又是一个和 no_cache 相似的词,它的意思是如果缓存不过期就可以继续使用,但过期了如果还想用就必须去服务器验证。
【客户端的缓存控制】
其实不止服务器可以发“Cache-Control”头,浏览器也可以发“Cache-Control”,也就是说请求 - 应答的双方都可以用这个字段进行缓存控制,互相协商缓存的使用策略。
当你点“刷新”按钮的时候,浏览器会在请求头里加一个“Cache-Control: max-age=0”。因为 max-age 是“生存时间”,本地缓存里的数据至少保存了几秒钟,所以浏览器就不会使用缓存,而是向服务器发请求。服务器看到 max-age=0,也就会用一个最新生成的报文回应浏览器。
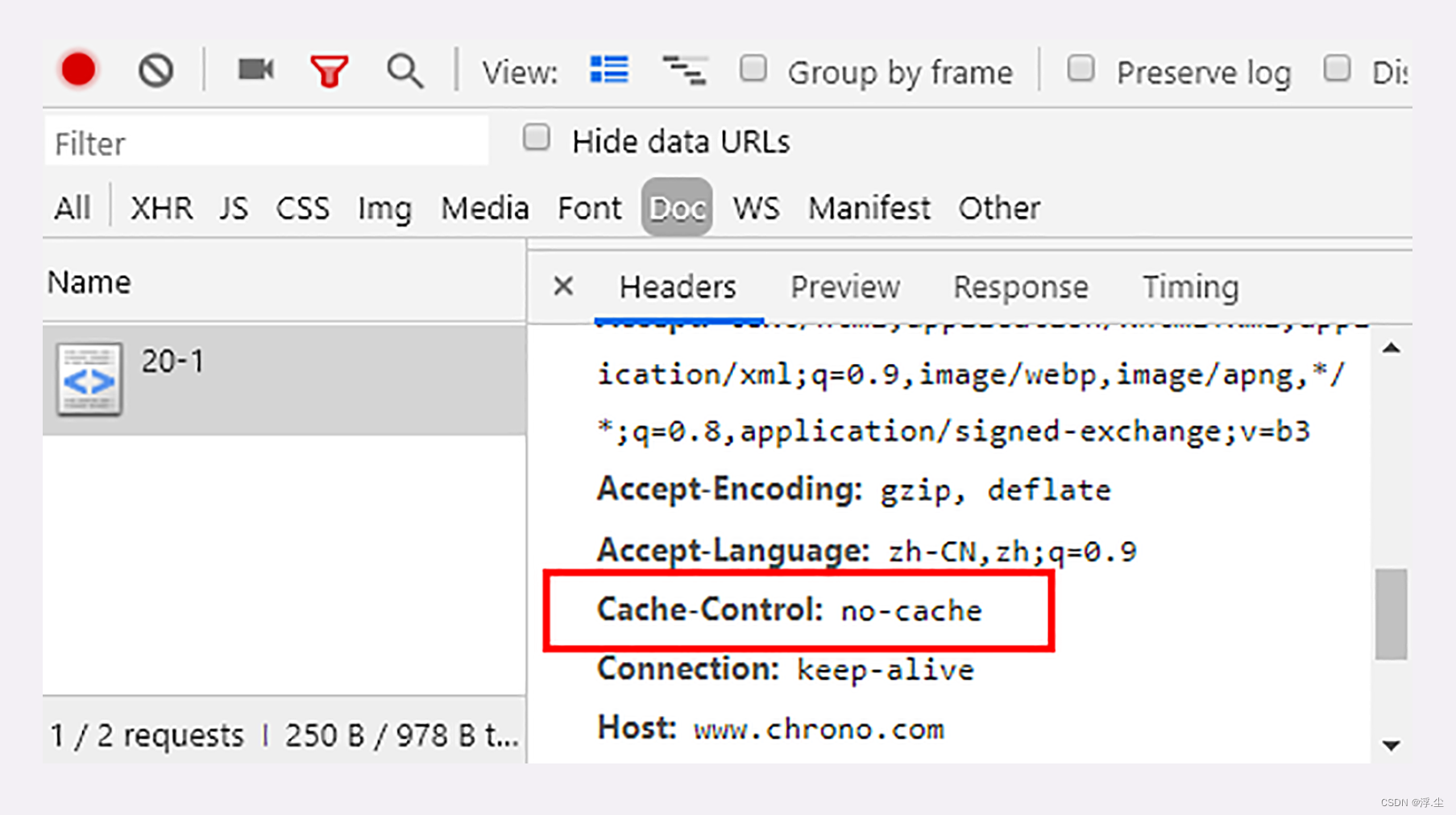
Ctrl+F5 的“强制刷新”又是什么样的呢? 它其实是发了一个“Cache-Control: no-cache”,含义和“max-age=0”基本一样,就看后台的服务器怎么理解,通常两者的效果是相同的。
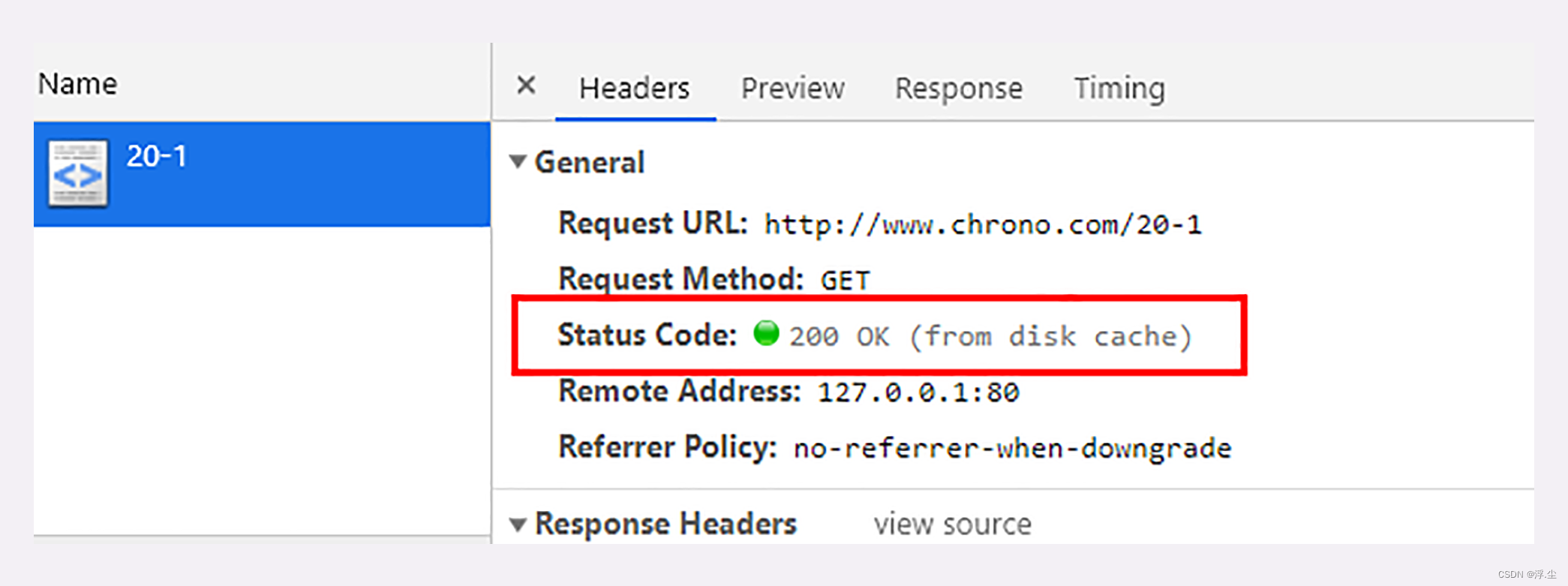
点一下浏览器的“前进”“后退”按钮,再看开发者工具,你就会发现 “from disk cache” 的字样,意思是没有发送网络请求,而是读取的磁盘上的缓存。
在“前进”“后退”“跳转”这些重定向动作中浏览器只用最基本的请求头,没有“Cache-Control”,所以就会检查缓存,直接利用之前的资源,不再进行网络通信。
浏览器用“Cache-Control”做缓存控制只能是刷新数据,不能很好地利用缓存数据,又因为缓存会失效,使用前还必须要去服务器验证是否是最新版。那么该怎么做呢?
浏览器可以用两个连续的请求组成“验证动作”:先是一个 HEAD,获取资源的修改时间等元信息,然后与缓存数据比较,如果没有改动就使用缓存,节省网络流量,否则就再发一个 GET 请求,获取最新的版本。但这样的两个请求网络成本太高了,所以 HTTP 协议就定义了一系列“If”开头的“条件请求”字段,专门用来检查验证资源是否过期,把两个请求才能完成的工作合并在一个请求里做。而且,验证的责任也交给服务器。
条件请求一共有 5 个头字段:最常用的是“if-Modified-Since”和“If-None-Match”这两个;另外还有三个不常用的头字段是“If-Unmodified-Since”、“If-Match”、“If-Range”。
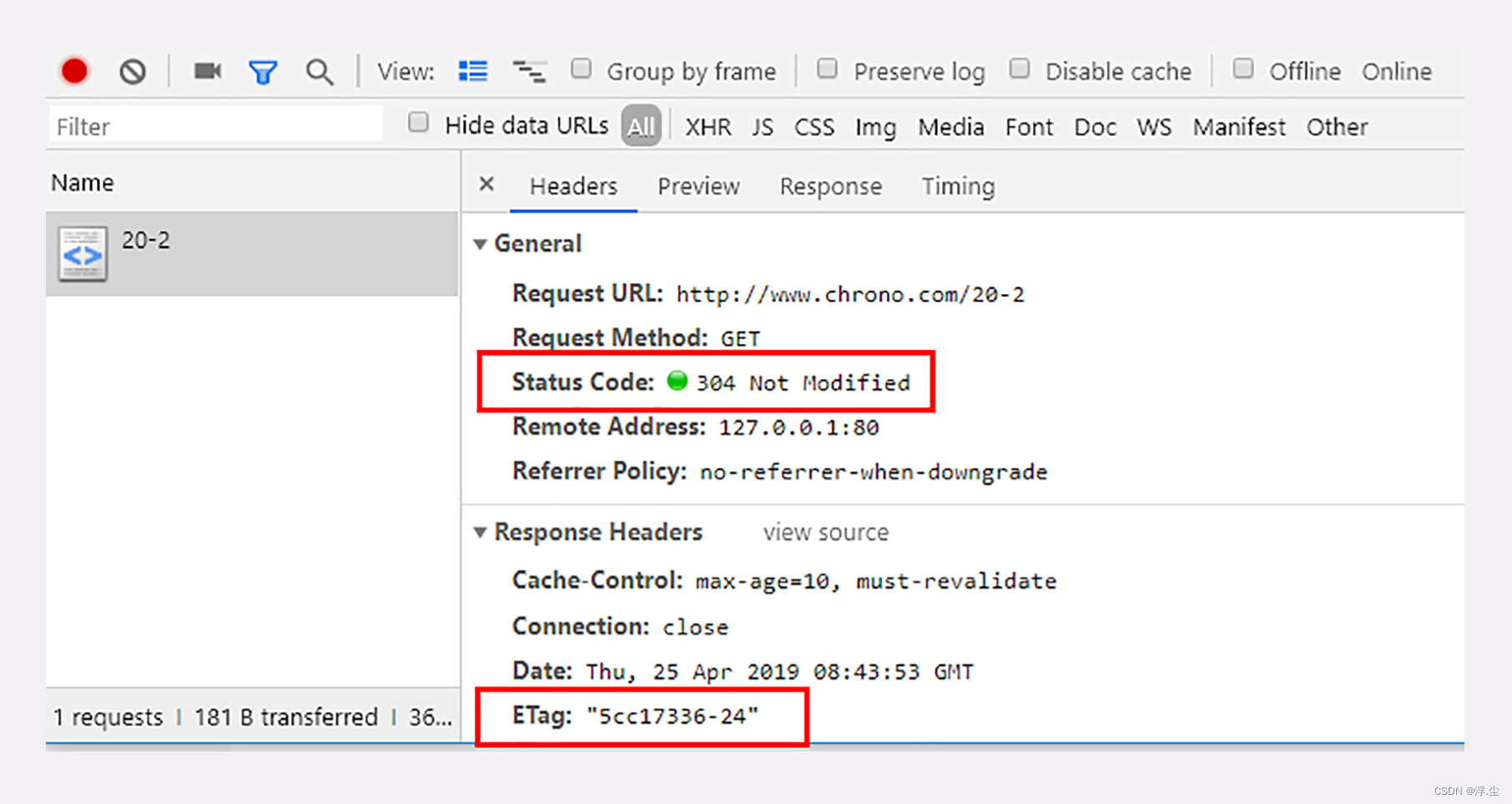
需要第一次的响应报文预先提供“Last-modified”和“ETag”,然后第二次请求时就可以带上缓存里的原值,验证资源是否是最新的。如果资源没有变,服务器就回应一个“304 Not Modified”,表示缓存依然有效,浏览器就可以更新一下有效期,然后放心大胆地使用缓存了。
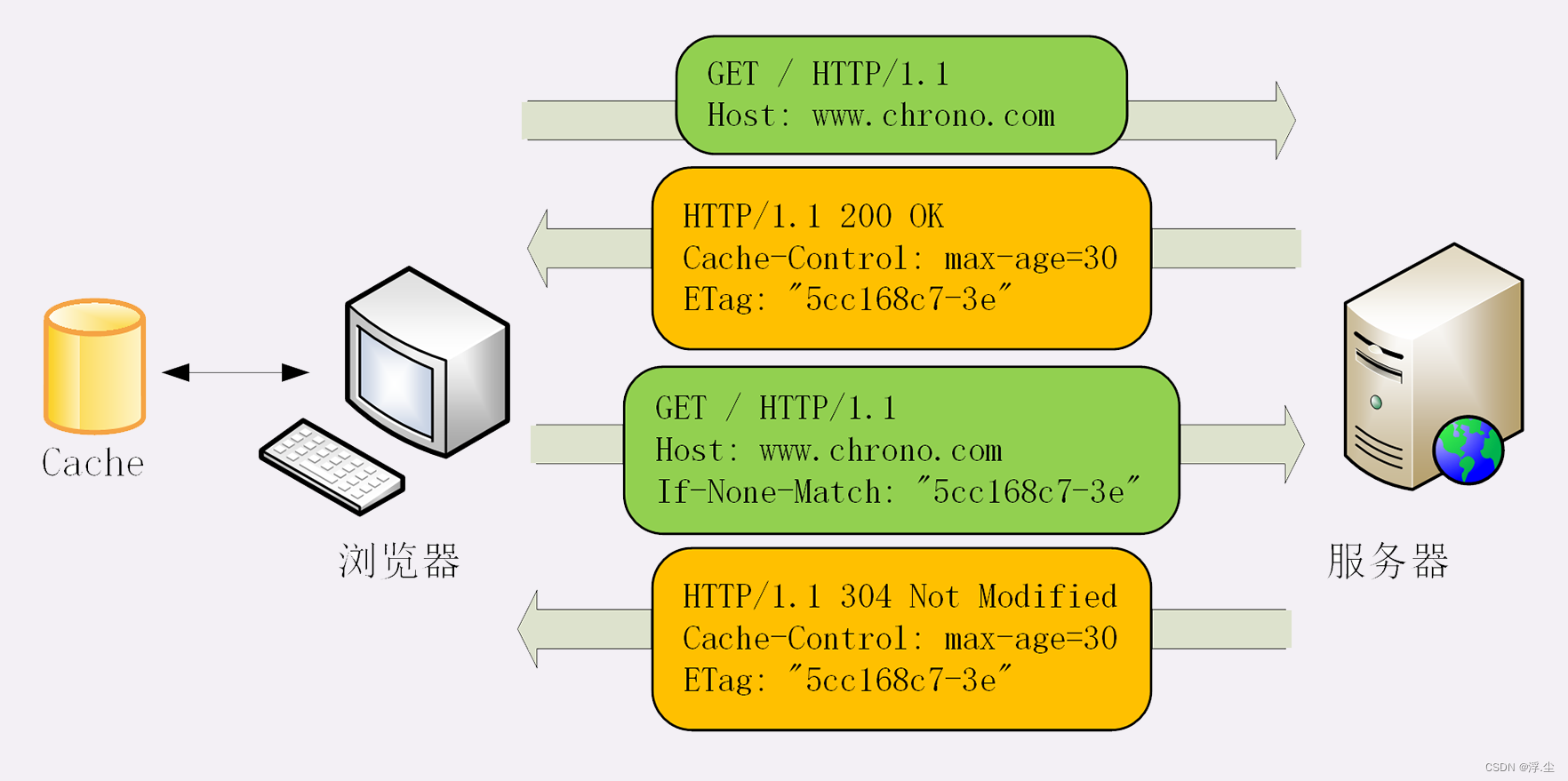
ETag
实体标签(Entity Tag)的缩写,是资源的一个唯一标识,主要用来解决修改时间无法准确区分文件变化的问题。
* 比如,一个文件在一秒内修改了多次,但因为修改时间是秒级,所以这一秒内的新版本无法区分。
* 比如,一个文件定期更新,但有时会是同样的内容,实际上没有变化,用修改时间就会误以为发生了变化,传送给浏览器就会浪费带宽。使用 ETag 就可以精确地识别资源的变动情况,让浏览器能够更有效地利用缓存。
* 强 ETag 要求资源在字节级别必须完全相符,弱 ETag 在值前有个“W/”标记,只要求资源在语义上没有变化,但内部可能会有部分发生了改变(例如 HTML 里的标签顺序调整,或者多了几个空格)。
HTTP的代理
“代理服务”就是指服务本身不生产内容,而是处于中间位置转发上下游的请求和响应,具有双重身份。代理最基本的一个功能是负载均衡。因为在面向客户端时屏蔽了源服务器,客户端看到的只是代理服务器,源服务器究竟有多少台、是哪些 IP 地址都不知道。于是代理服务器就可以决定由后面的哪台服务器来响应请求。代理中常用的负载均衡算法比如轮询、一致性哈希等等,这些算法的目标都是尽量把外部的流量合理地分散到多台源服务器,提高系统的整体资源利用率和性能。
代理服务还可以执行更多的功能,比如:
-
健康检查:使用“心跳”等机制监控后端服务器,发现有故障就及时“踢出”集群,保证服务高可用;
-
安全防护:保护被代理的后端服务器,限制 IP 地址或流量,抵御网络攻击和过载;
-
加密卸载:对外网使用 SSL/TLS 加密通信认证,而在安全的内网不加密,消除加解密成本;
-
数据过滤:拦截上下行的数据,任意指定策略修改请求或者响应;
-
内容缓存:暂存、复用服务器响应。
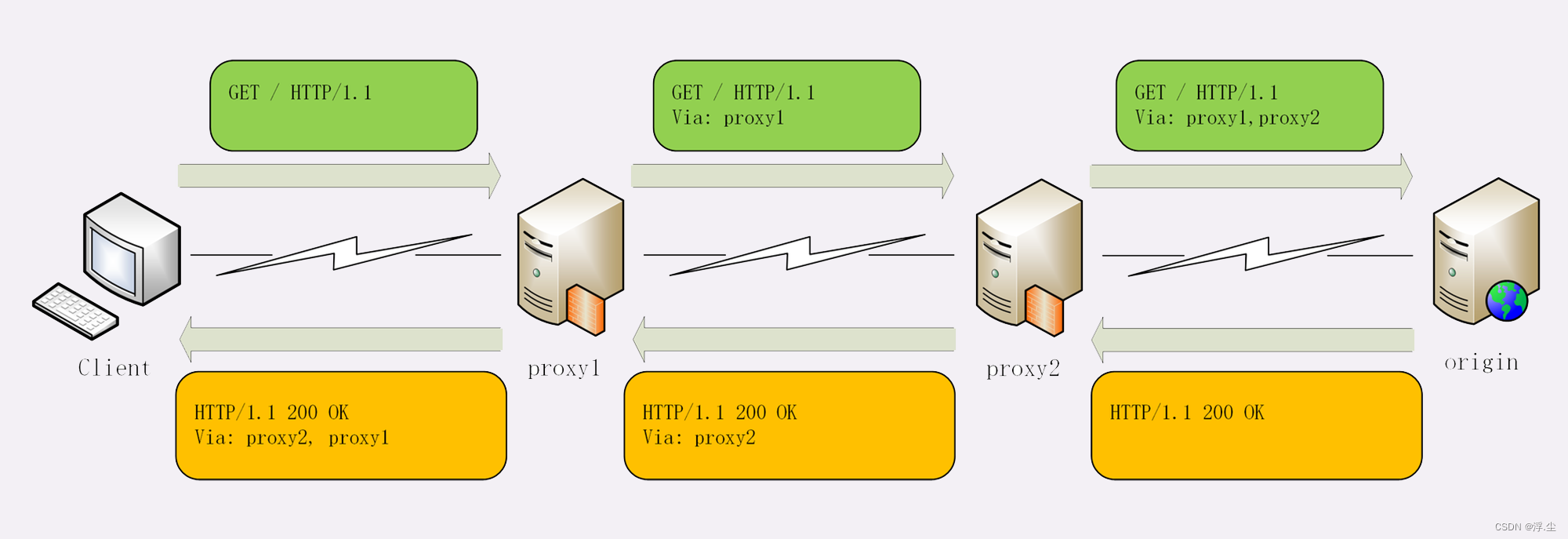
代理服务器需要用字段“Via”标明代理的身份,请求头或响应头里都可以出现。每当报文经过一个代理节点,代理服务器就会把自身的信息追加到字段的末尾,就像是经手人盖了一个章。
例如下图中有两个代理:proxy1 和 proxy2,客户端发送请求会经过这两个代理,依次添加就是“Via: proxy1, proxy2”,等到服务器返回响应报文的时候就要反过来走,头字段就是“Via: proxy2, proxy1”。
“X-Forwarded-For”的字面意思是“为谁而转发”,形式上和“Via”差不多,也是每经过一个代理节点就会在字段里追加一个信息,因为HTTP是明文传输的,因此X-Forwarded-For”不可信。
“X-Real-IP”是另一种获取客户端真实 IP 的手段,它的作用很简单,就是记录客户端 IP 地址,没有中间的代理信息,相当于是“X-Forwarded-For”的简化版。
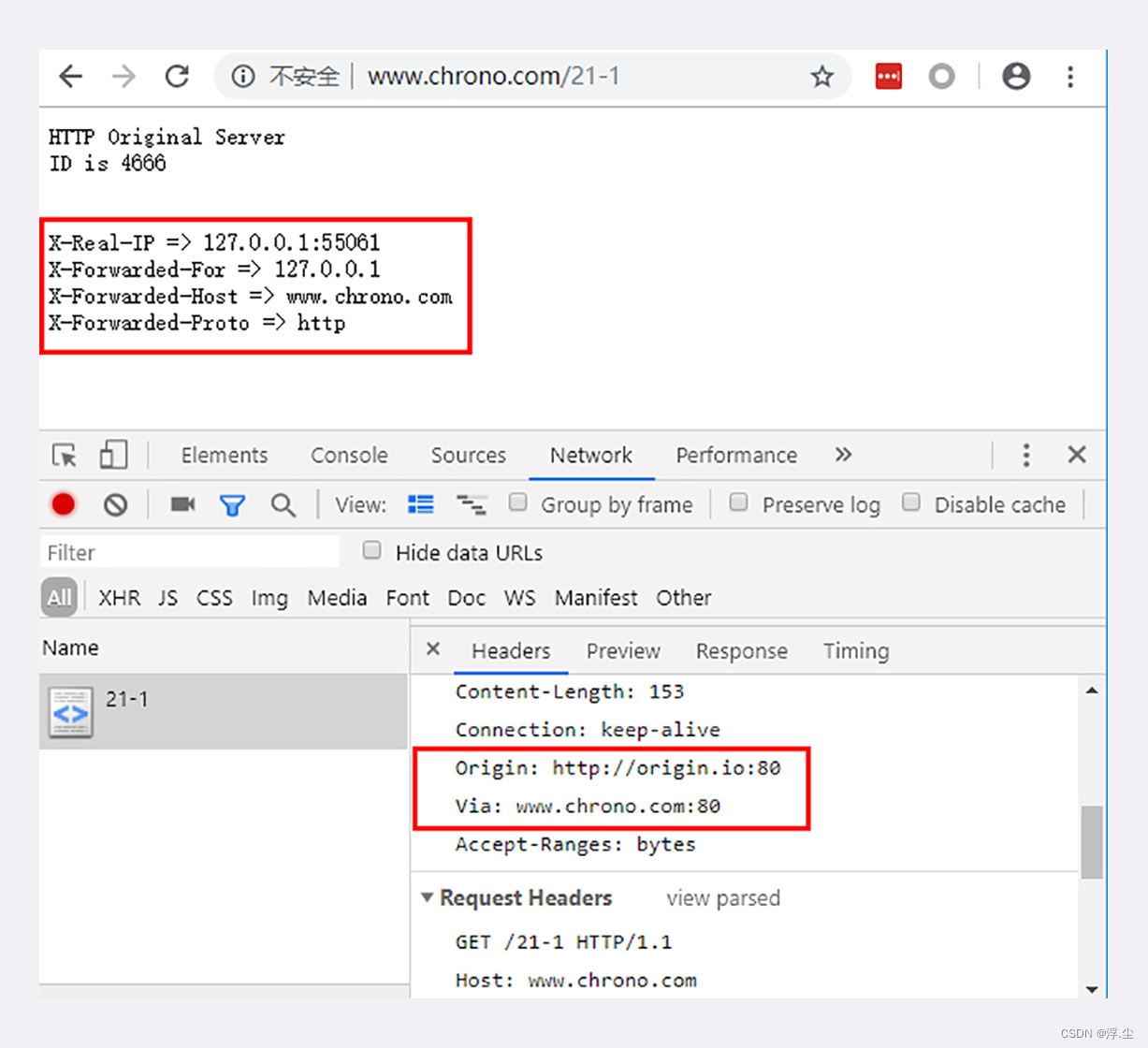
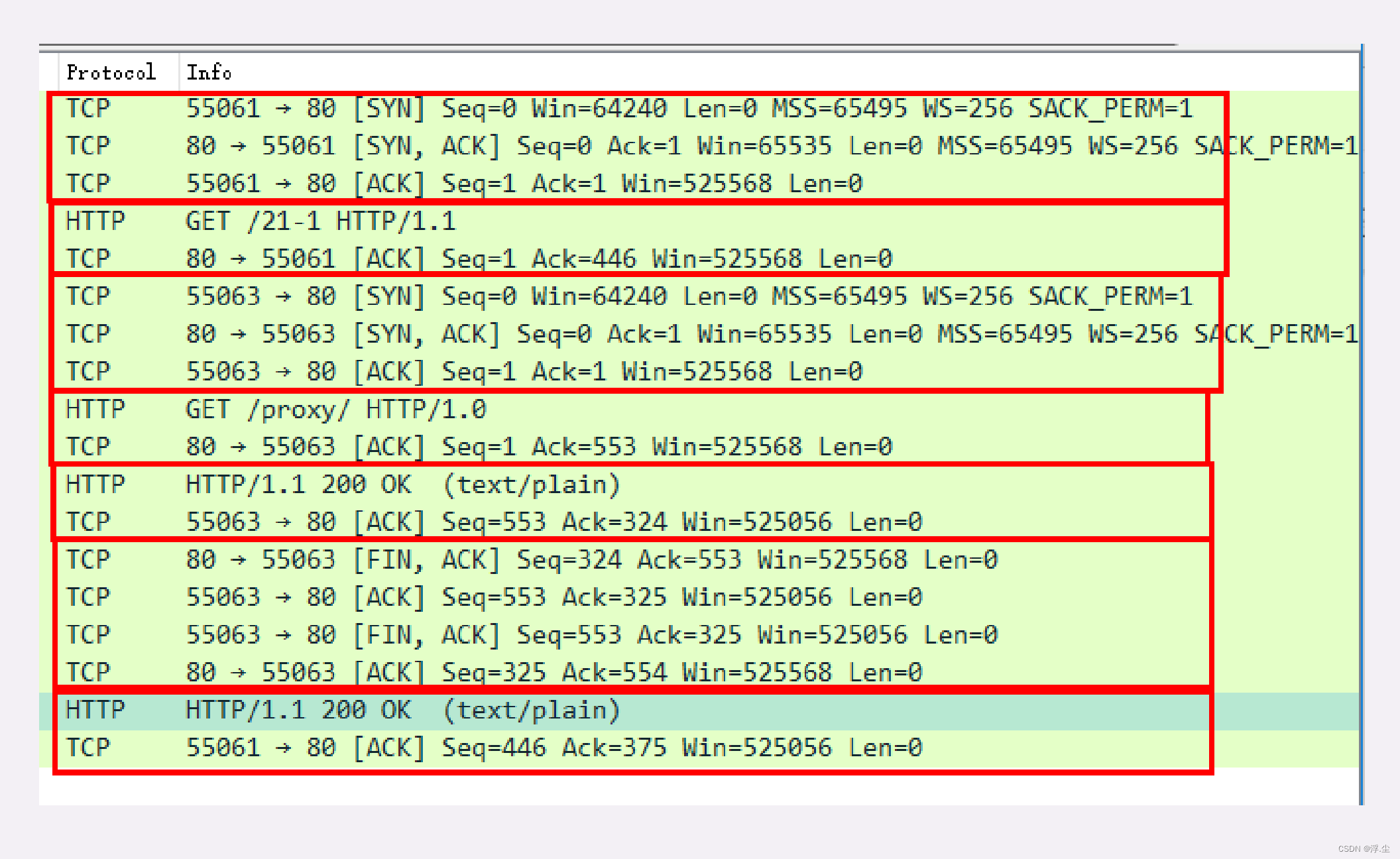
代理与客户端、源服务器的通信过程:
1. 客户端 55061 先用三次握手连接到代理的 80 端口,然后发送 GET 请求;
2. 代理不直接生产内容,所以就代表客户端,用 55063 端口连接到源服务器,也是三次握手;
3. 代理成功连接源服务器后,发出了一个 HTTP/1.0 的 GET 请求;
4. 因为 HTTP/1.0 默认是短连接,所以源服务器发送响应报文后立即用四次挥手关闭连接;
5. 代理拿到响应报文后再发回给客户端,完成了一次代理服务。
一个专门的“代理协议”(The PROXY protocol),它由知名的代理软件 HAProxy 所定义,也是一个“事实标准”,被广泛采用:开头必须是“PROXY”五个大写字母,然后是“TCP4”或者“TCP6”,表示客户端的 IP 地址类型,再后面是请求方地址、应答方地址、请求方端口号、应答方端口号,最后用一个回车换行(\r\n)结束。专门的“代理协议”可以在不改动原始报文的情况下传递客户端的真实 IP。


















 1971
1971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











