









c语言编码–优化tips
对于cpu密集型进程来说,语言层面有下面一些tips可供参考和借鉴
1.减少指令数
1.1 简单函数使用宏或者内联函数
非内联函数会有入栈、出栈的操作,
int min(int a, int b)
{
return a < b ? a b;
}
改成使用
#define min(a,b) ((a) < (b) ? (a) : (b))
1.2、少用乘法
定点乘需要花费n个指令周期,移位只需要一个指令周期,若乘以一个2的N次方数
可以使用移位
len = len * 4;
改为
len <<= 2;
1.3、慎用除/求余
除法需要耗费许多周期,可以将除法转化为乘法
f = f / 5.0
转化为:
f = f * 0.2
1.4、精度允许情况将浮点转化为定点运算
Pixel_C = (int) (Pixel_A * Alpha + Pixel_B(1 -Alpha)) alpha范围(0,1)浮点
转化为
Pixel_C = (int) (Pixel_A * Alpha + Pixel_B *(32 - ALpha) + 16) >> 5 alpha 取值范围(0,32) 定点整数
2、减少跳转
2.1 减少分支
cpu是流水执行,if switch等指令会带来跳转,跳转会影响水流执行效率
for (i=0; i<100; i++) {
if (i % 2) {
a[i] = x;
} else {
a[i] = y;
}
}
转化为
for (i=0;i<100;i+=2) {
a[i] = x;
a[i + 1] = y;
}
2.2 最可能的路径放到if 中
int a = -5;
int b = 0;
if (a > 0) {
b = 1;
} else {
b = 2;
}
由于没有历史信息可参考,Static Predictor 静态预测器 预测不跳转,a = 5预测错分支,错误取了b = 1指令,又要重新取指令
代码关键路径,可以借助 likely unlikely指定分支转移信息(GCC 版本需>= 2.96),将有利于分支预测的整体效率
#define likely(x) __builtin_expect((x),1)
#define unlikely(x) __builtin_expect((x),0)
3.尽量避免访内
访问一级cache只需要消耗几个指令周期, 访问二级缓存也只要十几个指令周期,访问内存需要消耗上百个指令周期,也要尽量避免 cache miss
3.1 减少使用数组、指针
大块内存会被放在存储器中,局部变量才会放到寄存器中,全局变量可能被多个模块和函数使用,编译器也不会放入寄存器中
c = a[i] * b[i];
d = a[i] + b[i];
以上语句会访问四次内存,改为
x = a[i];
y = b[i];
c = x * y;
d = x + y;
只访问两次内存
3.2 少用全局变量
int x;
int func()
{
int y, z;
y = x;
z = x + 1;
}
最好改为
int x;
int func()
{
int y, z,tmp;
tmp = x;
y = tmp;
z = tmp + 1;
}
3.3、对齐访问
不对齐访问cpu将会做多余的拼接操作,使执行效率变低
3.4、大数据结构时cache line对齐
cpu 取指令和数据时,先从一级和二级的LD/LP中查找数据,Intel 大多cache line 为64 bytes,对大结构分配内存时,尽量保持64byte对齐,减少cache miss
一个64byte 的数据如果非64byte对齐时,将占用两个cache line,会产生两次cache miss
多核情况也更容易一致性问题,cache line变脏。
举例:经常使用的struct sockaddr_storage
#define _K_SS_MAXSIZE 128 /* Implementation specific max size */
#define _K_SS_ALIGNSIZE (__alignof__ (struct sockaddr *))
/* Implementation specific desired alignment */
struct __kernel_sockaddr_storage {
unsigned short ss_family; /* address family */
/* Following field(s) are implementation specific */
char __data[_K_SS_MAXSIZE - sizeof(unsigned short)];
/* space to achieve desired size, */
/* _SS_MAXSIZE value minus size of ss_family */
} __attribute__ ((aligned(_K_SS_ALIGNSIZE))); /* force desired alignment */
3.5 程序、数据访问符合cache空间、时间局部性
for (j=0;j<500;j++) {
for (i=0;i<5000;i++){
sum += a[i][j];
}
}
应该采用,cache的命中率才高
for (i=0;i<500;i++) {
for (j=0;j<5000;j++){
sum += a[i][j];
}
}
a[i][j]在Cache中,a[i][j+1]也在cache中,而a[i+1][j]不一定在cache中
3.6 多线程尽量避免访内 false sharing**
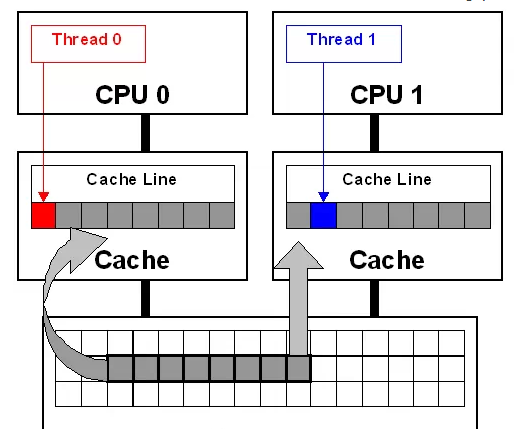
cache line是cache从内存取数据的最小单位,程序开辟了一个数组Arr,Arr[0]给线程0使用,Arr[1]给线程1使用,线程0在0核上运行,线程1在1核上允许,数组Arra既被cache到核0上,又被cache到核1上,如果线程0修改了Arr[0],那么cache一致性就使核1的这行cache line无效,导致线程1发生 cache miss,同样的过程发生在核1上修改Arr[1];
false sharing 会导致大量的cache 冲突,应该尽量避免,将多个线程范文的数据放置在不同的cache line 上
3.7 自己管理内存动态分配
避免频繁 malloc/free,内存碎片、降低内存泄露风险,频繁申请内存导致内存分散,加大cache miss概率,动态申请内存后,不做无用初始化,操作系统为了提高性能也使用COW(copy-on-write)策略,在fork子进程的时候不会立即复制进程的所有页表,只有代码段或者数据段改写才重新创建新空间















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









