







 本文探讨了生成模型和判别模型的区别与联系,详细解释了两类模型的学习目标、适用场景及优缺点,并通过实例说明如何选择合适的模型。
本文探讨了生成模型和判别模型的区别与联系,详细解释了两类模型的学习目标、适用场景及优缺点,并通过实例说明如何选择合适的模型。
车载音频调试,DSP模块(Car Audio Tuning: DSP Modules and Their Use)
MiniDSP关于车载声学的测试一共有四篇文章,本文是对第三第四篇的总结。主要阐述了车载音频调试的基本步骤,均衡器设置技巧以及对各频带的分析。原文链接放在最后。
极性和灵敏度检测(Polarity and sensitivity)
安装扬声器、DSP、放大器、电缆、麦克风和分析系统后,首先要做的是检查扬声器的灵敏度和极性。
要检查灵敏度,请在汽车中间放置一个麦克风。测量具有相同输出(例如 2.83V)的每个扬声器,并将它们成对比较才有意义,即左门低音扬声器与右门低音扬声器;左高音扬声器与右高音扬声器等。频率响应和电平应该相似,因此必须使用扫频测量。这样您就可以排除安装中的问题,例如声学短路或接线错误。
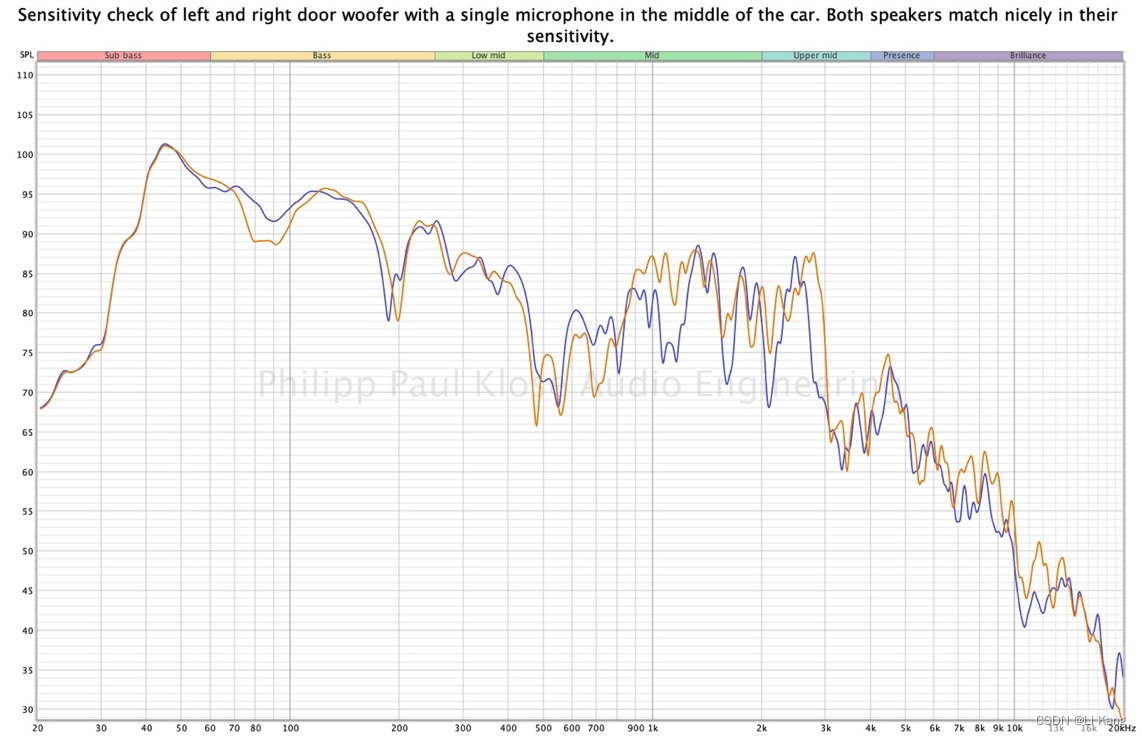
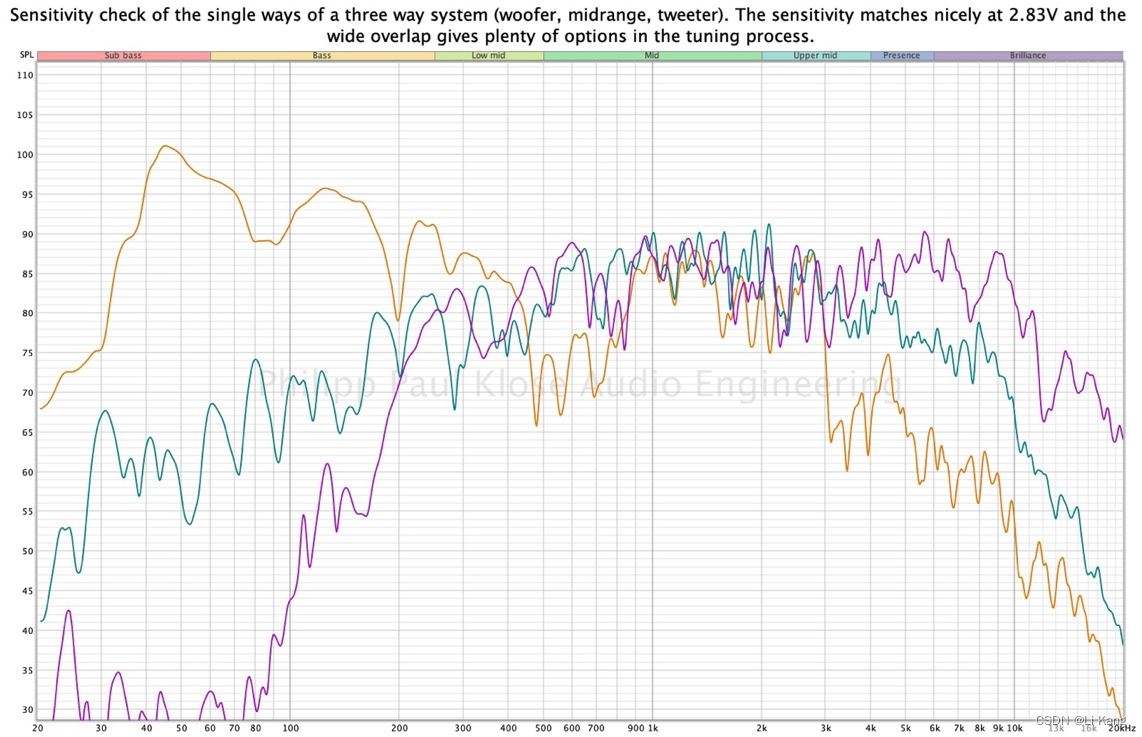
还要检查扬声器之间的灵敏度(低音扬声器与中音扬声器与高音扬声器)是否匹配并相应地进行调整。
要检查正确的极性,可以使用极性测试仪。请注意,滤波器或播放链路中的问题(使用 OEM 音响主机接入 DSP 时可能会发生)可能会导致极性问题(详细信息请参阅 https://www.audiofrog.com/how-to-test-for-polarity/)。
我个人喜欢使用一个简单的 1.5V 电池来检查是否一切正常。在将扬声器接线连接到放大器之前,将电池的 (+) 连接到扬声器线的 (+),将 (-) 连接到扬声器的接地,然后听听是否按预期触发。观察扬声器的纸盆是否朝向正确的方向。这种测试方法简单但有效,几乎不会出现false negative/positive。
扬声器保护(Speaker protection through output level and crossover)
输出功率限制
如果在错误的频段使用和/或功率过大,扬声器可能会损坏。这通过机械或热应力发生。为了从一开始就安全起见和在校准阶段(很容易发生过载错误),应在调音期间尽早解决扬声器保护问题。
扬声器的数据表在这里可以派上用场。查看有关您的扬声器可以使用的频段的信息。测量放大器的输出电压并计算输送到扬声器的功率。当您的系统调至最大并且所有其他信号处理(EQ、交叉等)关闭时,可以使用 RMS 万用表。请注意,每个扬声器都是不同的!
例如将一个能够处理 20 瓦的中音扬声器连接到 Harmony DSP 8x12。由于放大器可以驱动高达 40 瓦的功率,因此必须将输出设置为 -6 dB FS 以使输出功率减半。
如果您的 DSP 有限制器或压缩器(当比率调到 20:1 或更高时,压缩器变成限制器),可以通过电压限制为扬声器添加第二道防线。
分频器(Crossover)
分频器的设置可以通过C-DSP调试工具的 Output 标签下的 “Xover”.
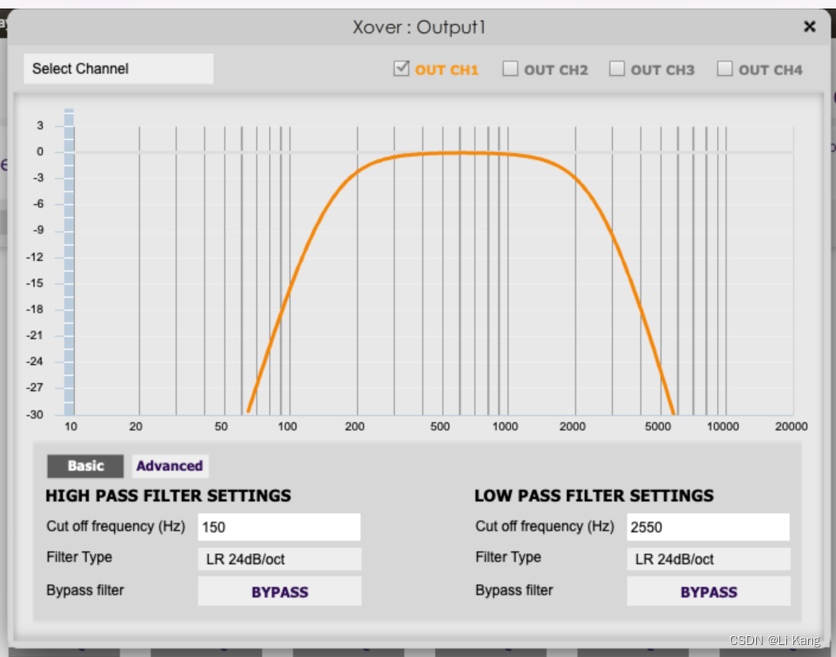
在车载音频中,需要查看频带重叠部分。可以通过对具有相同电压(当它们具有相同阻抗)的扬声器驱动器进行单独测量来找到重叠频带,然后在重叠视图中进行比较。将重叠频带移动到所有扬声器都在其合适区域的点。
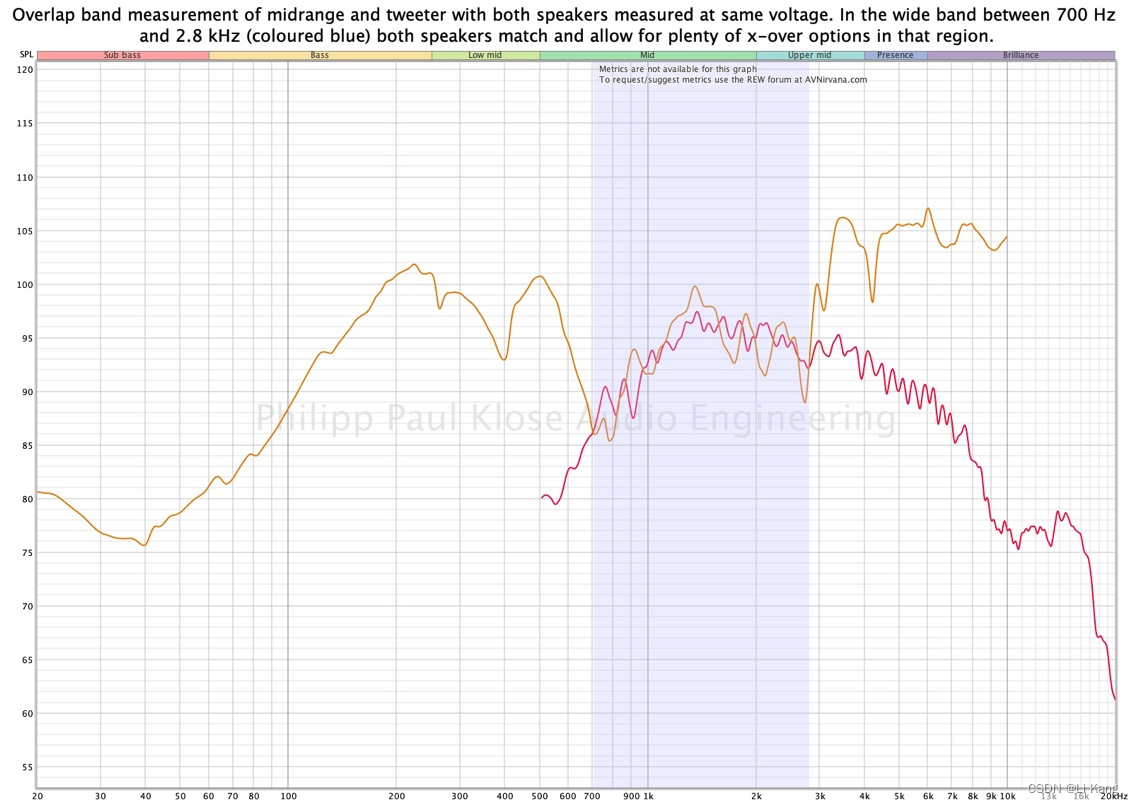
最佳做法是从 24dB/oct Linkwitz-Riley (LR) 分频器开始。当两个扬声器都交叉时,将检查它们的配合,同时两个扬声器都在测量中处于活动状态。此示例显示在扬声器之间应用时间延迟之前的结果。
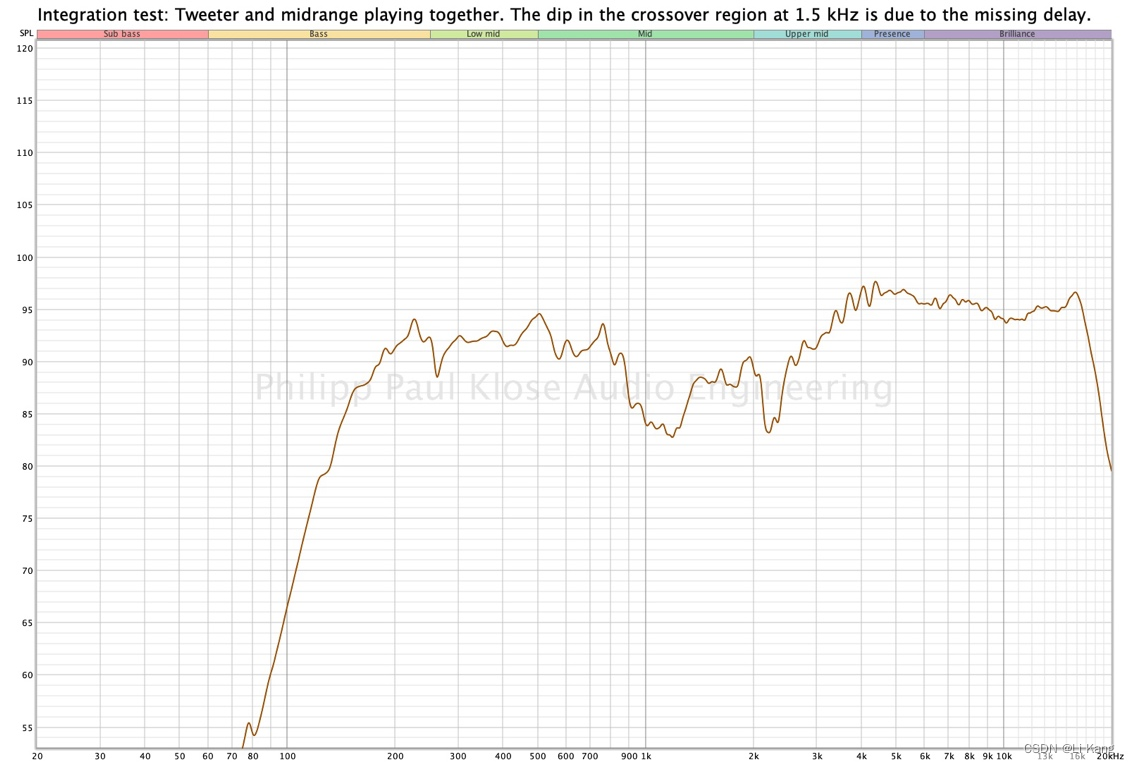
为获得最佳性能,必须在更正时序时再次检查交叉的完整性。
关于分频器的详细解释和教程可以参考: https://www.audiofrog.com/crossovers-how-they-work-and-how-to-choose-them/.
延迟校准相位Timing and phase correction with delays
在车厢内,每个扬声器与听众的距离不同。必须应用时间延迟来改善整体脉冲响应、声像质量并提高分频效率。
这里的想法是找到与收听者物理距离最大的扬声器,并相应地延迟其他扬声器到相同的距离。目标是平均每个扬声器的所有声音事件的到达时间,即使扬声器位于不同的位置。这将大大提高系统的整体脉冲响应和总体成像质量。
要找出必须延迟多少扬声器,您可以通过用卷尺测量与扬声器的距离来实现,或者您可以使用灵敏度测量中的数据。在这张图片中,您可以看到这将如何应用于现实世界的场景:
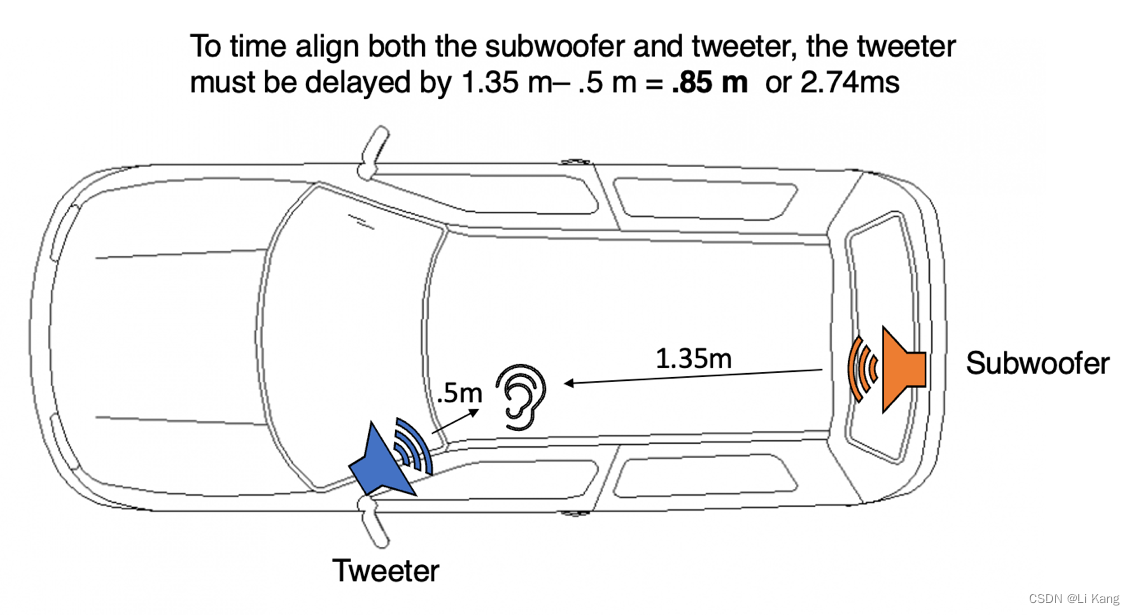
关于使用REW和UMIK的时间对齐的详细教程可以参考: https://www.minidsp.com/applications/auto-eq-with-rew/speaker-time-alignment.
延迟和分频器完成后,需要检查它们对扬声器对之间的叠加效应。确保比较对中的两个扬声器通道都已对其分频器和延迟进行了校准,并且能正常播放。当交叉频带平坦时,时序和交叉频率很好。一旦发现有看到叠加的频带有衰减或梳状滤波器现象,则必须调整交叉频率和/或延迟
布局布线Routing
布局布线可能是调优过程中最容易的任务之一。有关如何使用路由矩阵的信息,请参阅您设备的 miniDSP 用户手册。
路由通常以一种简单的方式实现:左信号到汽车的左侧,右信号到汽车的右侧。然而,路由可以是创建适当声场的重要工具。
扬声器在汽车中的极端放置通常会产生极端的声学成像。尝试将来自源的信号分配到多个扬声器。 miniDSP C-DSP 8x12、C-DSP 8x12 DL 和 Harmony DSP 8x12 提供了这种绝佳的可能性。这创造了一种更加身临其境的体验,让扬声器更像一个“团队”,而不是一堆单独的扬声器。
一般来说,可以说,您的音源拥有的输入通道越多(立体声,5.1声道,杜比全景声等等),到扬声器的路由就越离散,以实现艺术化的声学成像。
Routing is setup in the “Routing” tab in the C-DSP tuning tool. With fader and the invert tool, back-fill signals for the rear doors, synthesized center signals and overlapping distributions can be created in the car.
低音管理和低音单元优化(Bass management and mono bass optimization with MSO)
尽管车厢体积相对较小(在 2.5 到 4 立方米之间),但 Praxis 已经证明,使用多个低频源可以获得更好的整体效果。负载分配给多个扬声器,减少了位置依赖性(在座位上移动头部时变化较小)并提高了所有座位的一致性。这个概念被称为“单声道低音”。由于超低音扬声器/低音扬声器附近的装饰件和底盘部件的机械应力较小,因此可以减少摩擦/嗡嗡声和失真。车内整体能量分布更加均匀。
可以通过长时间的反复试验或借助算法帮助找到最佳结果。对于基于计算机的帮助,我推荐工具 Multi-Sub Optimizer (https://www.andyc.diy-audio-engineering.org/mso/html/)。有关如何使用 MSO 的介绍可在此处找到:https://www.minidsp.com/applications/subwoofer-tuning/dual-sub-with-mso。
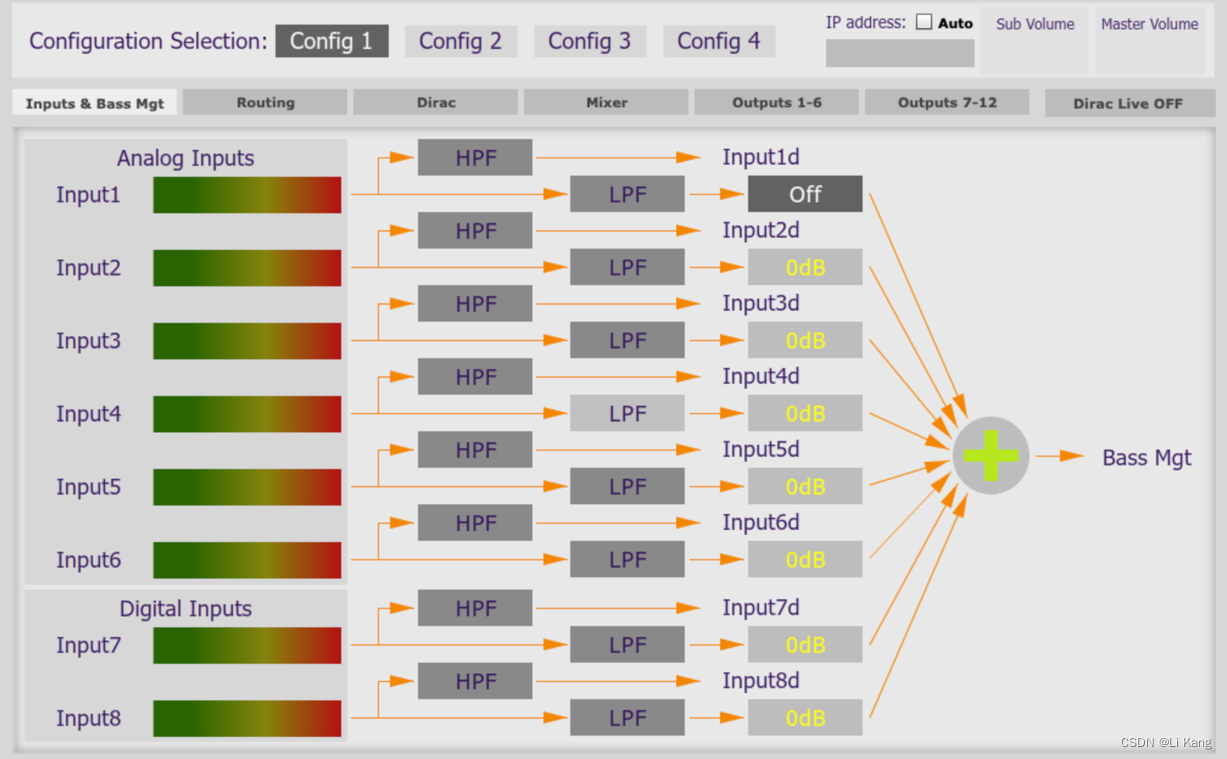
在 C-DSP 调谐工具中,低音管理是在“输入和低音管理”选项卡上校准的。如果您不仅让 MSO 优化 HPF 和 LPF,而且还使用 MSO 的“输出 1-6”和“输出 7-12”选项卡中的一个或两个 PEQ 频段以达到最佳结果,您将获得最佳结果。
均衡技巧(Equalization techniques)
设计方向(从高音还是低音开始)
我们既可以从高音扬声器开始,然后下降到中音、中低音和低音炮(自上而下)。也可以从低音炮开始,然后上升到中低音、中音和高音扬声器(自下而上)。
我建议从自下而上的方法开始,这样就更容易整合所有通道,因为低音为音乐奠定了基础。超低音扬声器和低音扬声器将最多的声能传递到机舱内,许多人使用低频信息来集中他们的声学判断。
少即是多(Less is sometimes more)
虽然拥有足够的 DSP 能力,但并不意味着我们必须使用每个 EQ 频段的功能。
在实现滤波器时,我们需要从填补最大的波谷或者衰减最大的波峰开始,通过测试后再开始处理下一个滤波器频带。如果从一开始就试图通过最大化所有 EQ 频段来消除频谱缺陷,即使对于经验丰富的调音师来说也是困难的,因为很难同时评估如此多的变化。我们需要一个接一个逐步地添加滤波器。
宁衰勿增(Better negative than positive)
在调音时,当某个频段似乎缺乏足够地幅频响应时,提高一些增益时似乎是自然而然的。但最好换个角度思考,与其增加本来不存在的响应,不如衰减“过多”的响应。
数字源往往只留下非常小的动态余量,不推荐使用 EQ 提高增益,因为数字信号链路很可能过载。这并非是绝对禁止的,也不一定会导致音质变差,但应该三思而后行。如果您确实想要通过滤波器提供正增益,则可能需要在滤波器的输入级进行衰减。
窄带(高Q值带来的问题)
较窄的频带调整通常作用不大。虽然试图平衡最小的波峰和波谷很诱人,但当质量系数 Q > 9时,滤波器通常没有帮助。我们耳朵的频谱分辨率(大约略高于 1/3 个八度音阶)是有限的,窄带滤波器的空间效应可能会产生负面作用,甚至当您的头部稍微从最佳听音位置(sweet spot)稍稍移动时产生零点。
零点Null points
有些频率点是无法通过EQ进行调节的,这些点被称为零点。在这些频率下,提升或削减都产生不了什么作用。对于这些零点,有必要围绕他们重新调整通道的调谐,以保持系统内部的频谱平衡和完整。
全通滤波器Allpass
全通可能是最被低估的滤波器,可以成为车载声音的救星。尽管它们不影响幅频响应,但它们会影响相位。它们能够在特定频段提供延迟,以帮助在中音和中低音通道上实现完美的层次感和整体性。
各频带分析
极低频0: Subbass
车厢内的最低可再现频率取决于您的低音炮/低音扬声器的直径和偏移能力。高级工厂可提供低至 25 赫兹 (f3),标准级别的声音可低至约 38 赫兹。越低越好。
低音感知是 - 对于外行和音效迷 - 感知质量的重要指标。因此,您想在这里获得良好的调谐响应。除了中低音之外,这可能是整个音频频谱中第二大 EQ 频率范围。
事实证明,将多个低频源放置在汽车的不同位置可提供最佳的整体性能。也就是说,拥有两个 8" 低音扬声器和一个 10" 低音炮并进行适当的单声道低音调谐,而不是让后备箱中的一个 12" 低音炮处理所有低于 150 Hz 的频率。
低频 1: Bass
- 车厢和低音本来就不是很搭配,车厢内狭小的空间使得很难获得均匀的低音响应:房间模式共同使得未经过优化的频率响应看起来像一幅山脉图片。压力室效应像shelving 滤波器一样提升整个低音区域,因此需要大量的 EQ 来降低峰值并平衡低谷。
- 在这个区域内,可能需要从低音到中低音的的分频器。
中低频2: Midbass and low mids
- 这是最难调整的范围,因为这里需要大多数 EQ 频段。我们的耳朵从 50 Hz 到 150 Hz 的频率范围内提取大量信息,因为许多乐器的基频都在该区域。(很多情况100Hz以下的声音能量并不大)
- 扬声器之间清晰的时间和相位关系对于声学抵消是必要的。
- 请注意此频率区域中可能存在的零点!
https://youtube.com/channel/UCKJUj746WOIUNjv5imYs6yA.
中频3: Low-mids and mids
在中低频中,可以发现汽车声学措施的副作用。用于将道路噪音挡在车外的声学阻尼材料也会影响车内娱乐声音。这可以在上图中看到 350 和 600 Hz 之间的衰减。下降的深度也可能时因为被测汽车中的中音扬声器数量不足。三路系统是汽车中获得良好声音所必需的。除此之外,零点很可能在这个频段出现。
中高频4: Upper mids
在中高频,我们远高于 Schroeder 频率(这里的房间模式是随机的)。大多数汽车都可以在这个区域进行调整。但是,由于测量的高度位置依赖性,多点测量和阵列测量是做出良好调整决策的必要条件。在这个区域内,您可能需要从中音扬声器到高音扬声器的分频器。
高频和现场感5: Presence and high ear sensitivity area
人耳在这个频段最为敏感。由于耳廓和耳道的大小不同,每个人在该频率范围内的频率响应、耳内共振和感知都略有不同。如果您为自己的汽车进行调音,那么根据个人喜好进行调整是有意义的。
注意保护您的听力,尤其是在该区域调音和收听时。我们的身体可以通过镫骨肌反射来保护自己。肌肉在听力中抽搐并发出咔嗒声,听力立即受到约20分贝的减弱。如果您听到咔嗒声,请小心并调低音量。镫骨肌反射只保护我们在神经系统中的感知,并不保护听觉系统!
通常可以在该区域找到某个“商标”频率响应。由于每个音频品牌都试图将自己与彼此区分开来,因此这里就是他们这样做的频段之一。如果您测量该频段区域的不规则情况,请不要感到惊讶。
高频6: Highs
5 kHz以上的高频会带来高音扬声器共振和扬声器偏离中心使用的挑战。如果您使用的是硬球顶高音扬声器或宽带扬声器,很可能会遇到使声音刺耳和尖锐的共振。这可以通过调音来解决。
高音扬声器通常不能在汽车的中心位置使用,而是在反射面附近。高频的损失必须通过高频提升来解决,而广泛组合效应(broad combing effects)可以通过轻微的提升来抵消。
参考
https://www.minidsp.com/applications/car-audio/3-car-audio-tuning-dsp
https://www.minidsp.com/applications/car-audio/4-car-audio-philosophy-challenges

















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









