爬取去哪儿酒店信息及评论
第一步,获取城市列表
import requests
import json
import codecs
url = "https://touch.qunar.com/h-api/hotel/hotelcity/en"
s = requests.get(url)
file = codecs.open('./city.json','w','utf-8')
file.write(s.text)
file.close()
运行结果:

第二步 根据城市列表爬取酒店信息(以汉庭酒店为例)
需要注意两点:
1.请求时需要带数据
当前时间必须在fromDate--toDate之前
"b":{"bizVersion":"17",
"cityUrl":cityid,
"fromDate":fromDate,
"toDate":toDate,
"q":"汉庭酒店",
"qFrom":3,
"start":start,
"num":20,
"minPrice":0,
"maxPrice":-1,
"level":"",
"sort":0,
"cityType":1,
"fromForLog":1,
"uuid":"",
"userName":"",
"userId":"",
"fromAction":"",
"searchType":0,
"hourlyRoom":False,
"locationAreaFilter":[],
"comprehensiveFilter":[],
"channelId":1},
"qrt":"h_hlist",
"source":"website"}
2.以这个headers进行访问,cookie填你自己的cookie
headers = {
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"content-length": "389",
"content-type": "application/json;charset=UTF-8",
"cookie":"你的cookie",
"origin": "https://hotel.qunar.com",
"referer": r_url,
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
上代码
import json
import requests
import datetime
import urllib.parse as p
import time
import codecs
import csv
import re
def get_session(cityid,city):
fromDate = datetime.date.today().strftime("%Y-%m-%d")
toDate = (datetime.date.today() + datetime.timedelta(days=1)).strftime("%Y-%m-%d")
url = "https://hotel.qunar.com/cn/{}/?fromDate={}&toDate={}&cityName={}&from=qunarindex&cityurl=".format(
cityid,fromDate,toDate,p.quote(city))
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"referer": "https://www.qunar.com/"
}
session = requests.session()
res = session.get(url=url,headers = headers)
return session,url,fromDate,toDate
def get_data(session,cityid,fromDate,toDate,start,url,headers):
payload = {"b":
{"bizVersion":"17","cityUrl":cityid,"fromDate":fromDate,
"toDate":toDate,"q":"汉庭酒店","qFrom":3,"start":start,"num":20,
"minPrice":0,"maxPrice":-1,"level":"","sort":0,"cityType":1,
"fromForLog":1,"uuid":"","userName":"","userId":"",
"fromAction":"","searchType":0,"hourlyRoom":False,
"locationAreaFilter":[],"comprehensiveFilter":[],
"channelId":1},
"qrt":"h_hlist","source":"website"}
data = json.dumps(payload)
res = session.post(url=url,data=data,headers=headers)
if start == 0:
print (json.loads(res.text))
return res,session,json.loads(res.text)["data"]["tcount"]
else:
return res,session
def get_pages(cityid,city):
session,r_url,fromDate,toDate = get_session(cityid,city)
url = "https://hotel.qunar.com/napi/list"
headers = {
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"content-length": "389",
"content-type": "application/json;charset=UTF-8",
"cookie":"你的cookie",
"origin": "https://hotel.qunar.com",
"referer": r_url,
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
start=0
res,session,end_num = get_data(session,cityid,fromDate,toDate,start,url,headers)
with open("{}.csv".format(city),'a+',encoding="utf-8") as f:
f.write("name,url,city,seqno\n")
for start in range(20,end_num,20):
res,session = get_data(session,cityid,fromDate,toDate,start,url,headers)
if res.status_code == 200:
with open("{}.csv".format(city),'a+',encoding="utf-8") as f:
time.sleep(2)
hotels = json.loads(res.text)['data']['hotels']
for i in range(0,len(hotels)):
print(hotels[i]['seqNo'])
seqNo = re.findall(cityid+'_(.*)',str(hotels[i]['seqNo']))
print(seqNo)
f.write(hotels[i]['name']+','+'https://hotel.qunar.com/cn/'+cityid+'/dt-'+seqNo[0]+','+city+','+hotels[i]['seqNo']+'\n')
else:
print("获取数据失败")
time.sleep(2)
def get_city():
f = codecs.open('./city.json','r','utf-8')
return json.loads(f.read())
if __name__=="__main__":
d1 = get_city()
for k in range(len(d1['data'])):
items = d1['data'][k].items()
for key,value in items:
for j in range(10,len(value)):
cityid = value[j]['cityUrl']
city = value[j]['cityName']
print(cityid)
get_pages(cityid,city)
运行结果
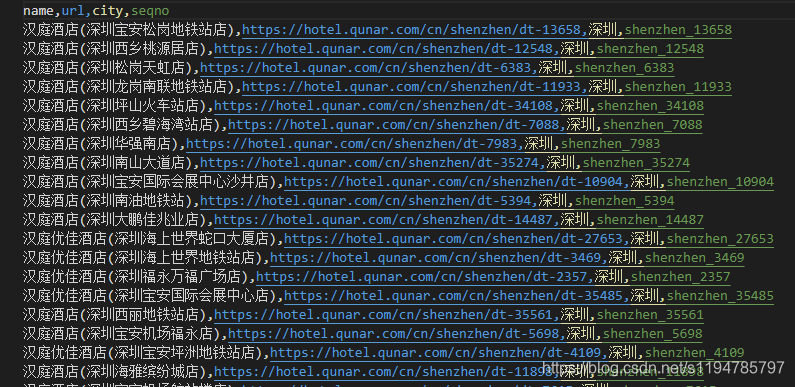
第三步爬取酒店评论
import requests
import csv
import json
f= open(r'new.csv','r',encoding='gbk')
with open('remark1.csv','a+',encoding='utf-8') as f_remark:
f_remark.write("name,star,feed,time\n")
reader = csv.reader(f)
for item in reader:
print(reader.line_num)
if reader.line_num == 1:
continue
if reader.line_num == 361:
break
if reader.line_num <236:
continue
print("当前内容:",item)
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cookie":"你的cookje",
"referer": item[1],
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
for i in range(100):
try:
url =" https://hotel.qunar.com/napi/ugcCmtList?hotelSeq={}&page={}&size=10".format(item[3],i+1)
response = requests.get(url=url,headers=headers)
res = json.loads(response.text)
for j in range(len(res['data']['list'])):
content = json.loads(res['data']['list'][j]['content'])
star = content['evaluation']
feed = content['feedContent'].replace('\n','').replace('\r', '').replace(',',',')
time = content['modtime']
if(star=='' or feed=='' or str(time)==''):
continue
with open('remark1.csv','a+',encoding='utf-8') as f_remark:
f_remark.write(item[0]+','+str(star)+','+str(feed)+','+str(time)+'\n')
print(feed)
except:
break
f_remark.close()
f.close()
运行结果
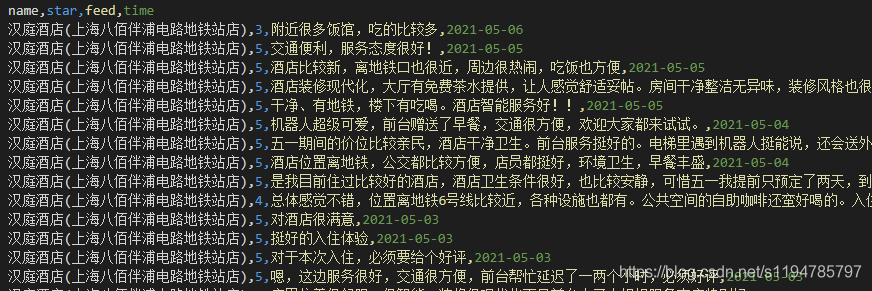
























 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









