







一.设计内容
1.程序题目:种领域特定脚本语言的解释器的设计与实现
2.描述:
领域特定语言(Domain Specific Language,DSL)可以提供一种相对简单的文法,用于特定领域的业务流程定制。本作业要求定义一个领域特定脚本语言,这个语言能够描述在线客服机器人(机器人客服是目前提升客服效率的重要技术,在银行、通信和商务等领域的复杂信息系统中有广泛的应用)的自动应答逻辑,并设计实现一个解释器解释执行这个脚本,可以根据用户的不同输入,根据脚本的逻辑设计给出相应的应答。
二.基本要求
- 脚本语言的语法可以自由定义,只要语义上满足描述客服机器人自动应答逻辑的要求。
- 程序输入输出形式不限,可以简化为纯命令行界面。
- 应该给出几种不同的脚本范例,对不同脚本范例解释器执行之后会有不同的行为表现。
三.开发环境
1.运行环境:Windows10
2.开发语言:Java
3.开发环境:eclipse(4.18.0),JavaSE-1.8
四.脚本语言设计
1.语言简介:
此脚本语言类似于面向对象的语言,编写过程只需要声明不同的状态阶段,为了简化编写脚本语言的压力,所有状态阶段均继承同一个父类,都有一些共同的内置参数可供使用该脚本的人员使用。
脚本语言整体实现类似于自动机,从编写的第一个状态阶段开始运行,根据不同的输入转移到不同的状态阶段的特定动作,直至完成用户要求并退出。
2.定义脚本语言关键字:
(1)variable (2)state (3)speak (4)input (5)wait_input
(6)if - then - (7)default - (8)goto: …… end (9)access_database
(10)update_database (11)exit_all
3.语义动作:
(1)variable:声明所要使用的变量。
(2)state:完整表示一个步骤的所有动作。
(3)speak:将表达式中的变量转换为相应的值后输出整个语句。
(4)input:读取输入内容,并调用自然语言分析,确定出客户的意愿。
(5)wait_input:在指定时间段内读取输入内容,并调用自然语言分析,确定出客户的意愿。若超出该时间段则向程序返回”timeout“这一状态信息。
(6)if - then -:条件判断。
(7)default -:对不匹配的判断条件做补充。
(8)goto: …… end:对客户的意愿进行分支处理,根据意愿跳转至不同state。
(9)access_database:根据用户信息以及要求,从数据库或本地记录中读取指定信息。
(10)update_database:根据用户信息以及要求,更新数据库或本地记录中指定的信息。
(11)exit_all:结束对话,关闭窗口。
4.脚本含义:
脚本中第一个声明的state为程序执行入口,然后根据不同的输入或其他信息进行state间的转移,从而完成不同的功能。
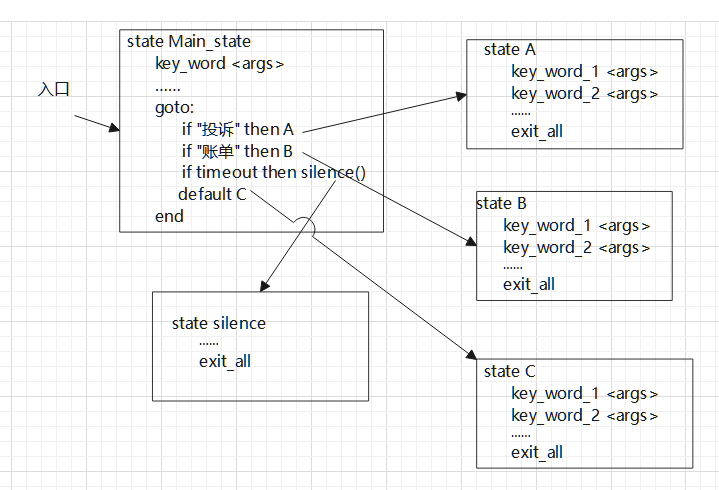
5.脚本使用说明:
5.1.简介:
此脚本语言类似于面向对象的语言,编写过程只需要声明不同的状态阶段,为了简化编写脚本语言的压力,所有状态阶段均继承同一个父类,都有一些共同的内置参数可供使用该脚本的人员使用。
脚本语言整体实现类似于自动机,从编写的第一个状态阶段开始运行,根据不同的输入转移到不同的状态阶段的特定动作,直至完成用户要求并退出。
5.2.关键字使用(语义动作):
|
关键字 |
作用 |
参数 |
|
variable |
声明脚本中所使用的所有变量,通常在脚本最开始处声明。 |
必须用&符号进行标识,且以字母开头,又字母数字下划线组成,不同变量间必须采用空格分隔 |
|
state |
声明一个状态阶段,从该语句开始直到下一个state语句前的所有语句均属于本状态阶段的内容。表示一个完整步骤的所有行为。 |
只能字符开头,包含字母数字下划线,该参数即为此状态阶段的标识符。 |
|
speak |
打印所传入的用双引号引用的字符串。字符串中可出现变量,但变量必须由%包围,如:%&name%,同时变量必须已赋值。 |
由双引号引用的字符串以及由%包围的变量。 |
|
input |
等待读取用户的输入,并将其保存至参数中。 |
1.默认参数:将用户输入保存至当前state的“input”中以便后续使用。 |
|
wait_input |
在指定时间内等待读取用户的输入,并将其保存至参数中,若该时间段内用户未输入,则停止等待,并向正在执行的脚本程序传入一个“等待输入超时”的信息。 |
参数一(必须):阿拉伯数字表示等待时间,单位是秒 |
|
if - then - |
用于条件判断,符合判断条件就执行then后面的内容。只能在goto: …… end模块中使用。 |
参数一:判断条件 |
|
default - |
在if - then - 后面使用,作用于除上述if - then - 中的判断条件外的其他判断条件的情况。 |
参数:跳转到的状态 |
|
goto: |
根据当前状态的input信息(有输入或是等待输入超时)进行状态转移,运行脚本声明的其他状态阶段的某一特定动作语句。注意goto后的冒号,且default不是必须要写的。 |
例如: |
|
access_database |
从后台数据库或本地文件获取想要查询的信息,如账单,余额,业务单号等。 |
参数一:指定要访问的数据库或本地文件,使用双引号包围 |
|
update_database |
更新本地记录或是数据库中指定的内容。可用于充值余额,缴费等功能。 |
参数一:指定要更新的数据库或本地文件,使用双引号包围 |
|
exit_all |
退出程序,结束脚本程序的运行 |
无 |
5.3.state内置参数说明:
state内置参数:state_id,state_input,action。(不可在脚本语言中直接调用)
- state_id:即该状态阶段的标识符,对应于脚本语言中state关键字后的参数,编译脚本后的运行程中通过state_id查找状态阶段并完成转移。
- state_input:
接受执行当前状态时的用户输入(如果该输入没有指定变量参数),多用于goto模块中的if条件判断。state_input有三种情况:
(1)未接受到输入时:state_input未空。
(2)接受到输入时:state_input中为用户所输入的字符串。
(3)等待用户输入超时时:state_input置为timeout状态,表示等待输入超时。
由此,goto模块中的if的判断条件通常为三种,分别对应state_input的三种装填:
(1)if “” then A :判断条件为空,即无条件转移。
(2)if "投诉" then A :如果用户输入“投诉”,则执行A。
(3)if timeout then A:如果输入超时,则执行A。 - action:
该状态的动作表,根据编写的脚本语言,依次存储着脚本语言中所声明的动作以及相应的参数。用于顺序执行,或是得到该状态下的指定动作。
5.4.语法定义:
- 状态阶段的声明:
variable &var1 ……
state state_id
key_word_1 <args>
key_word_2 <args>
……
variable &var2 ……
state state_id
key_word_3 <args>
key_word_4 <args>
……
在不同的状态阶段中,声明该state中所需要的不同的执行动作,而对于关键字state 的参数state_id,以及其余执行动作对应的关键字的参数要求均参考关键字定义表。
同时请务必在每个变量使用前对其声明,当然也可以在脚本一开始就声明所有的变量,因为在此脚本语言中,所有变量均为全局变量。
- 主state:所编写的脚本语言中第一个声明的state为主state,即程序运行的第一个状态阶段,其他state均由主state条件转移后才能被执行。
- 该脚本语言没有明显的缩进要求,但为了语言层次级别清晰,建议使用合理缩进。
- 该脚本语言有换行要求,每行能且只能声明一个语言动作(一个关键字加相应参数为一个完整的动作),且必须使用空格分隔关键字与参数,对于多个参数的情况,也是用空格来分隔参数。同时请勿在一行中声明多个动作或是使用多行声明一个动作,否则编译错误。
(正确)key_word <args>
(错误)key_word<args>
(错误)key_word_1 <args> key_word_2 <args>
(错误)key_word
<args>
- 对于goto:…… end模块,此模块是由多个动作构成,所以应注意换行,具体用法参考关键字表。
goto:
if <Judgment_conditions> then <state_id>
default <state_id>
end
- 请确保脚本语言中所有状态阶段最后都能够转移到结束状态,并执行exit_all这一动作。否则程序无法正常结束。
- 关键词和参数之间,参数和参数之间务必使用空格分隔。
key_word <arg1> <arg2> <arg3>
5.5.错误信息:
当脚本语言编译遇到错误时,会抛出相对应的异常以及相关的debug信息,可以从中得知出错的行数以及相关错误。
例如:“第29行: &name,变量未声明”
“第1行: 变量名构造错误”
五.脚本语言编译执行过程
1.编译执行过程:
首先读取编写好的脚本文件,对其进行语法分析,边检错边编译,识别出不同的语义动作存入语法树的存储结构中,若在此过程中遇到语法错误,如无法识别的记号,命名错误,变量不存在等情况,抛出相关异常并输出debug信息,表示错误类型以及出现错误的地方。若整个过程成功执行,则可得到该脚本文件的整个执行过程,存放在语法树存储结构中。
执行时,首先从存储结构中取程序入口的state,按照编译所得的动作依次执行,并根据所输入的用户意愿,跳转到下一个相应的state,并按照编译所得的该state的动作依次执行,直至程序结束。示意图如下:
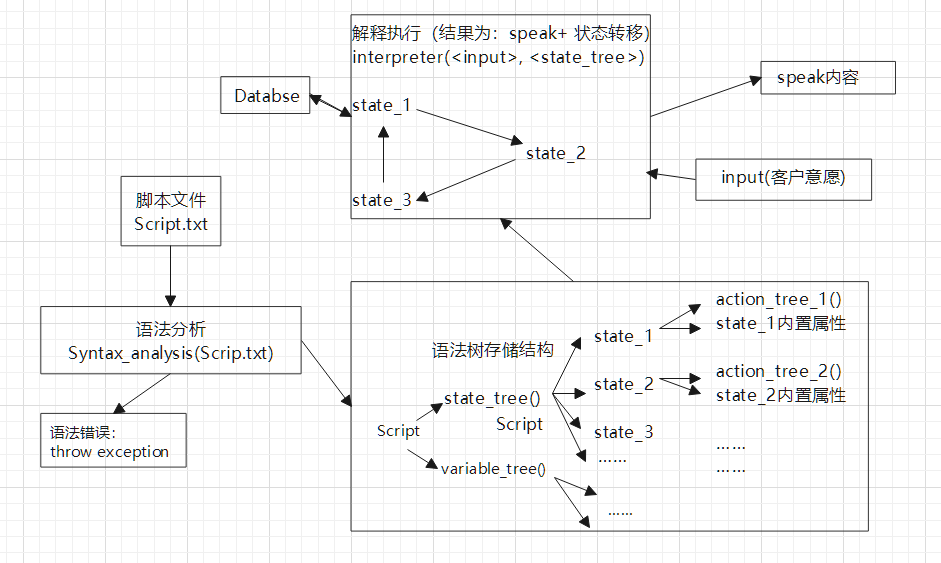
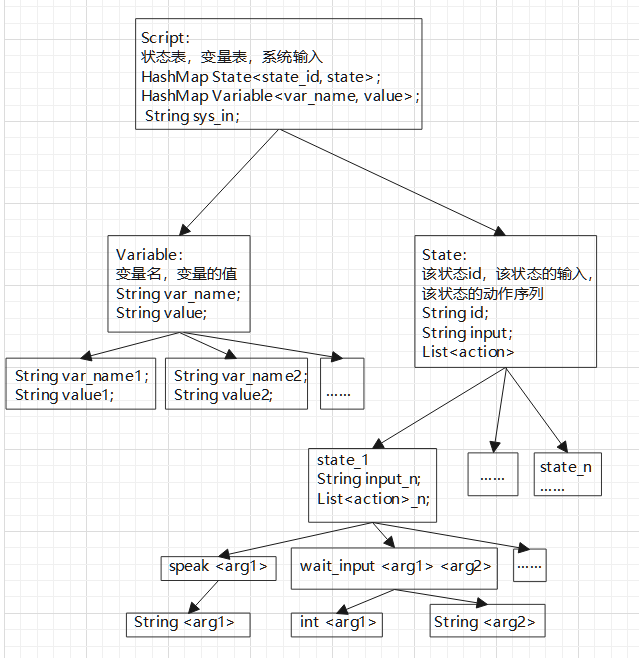
2.语法树详细存储结构:
六.程序实现
1.模块划分:
|
类 |
说明 |
|
analysis |
主要的语法分析过程, 通过正则表达式匹配来确定从脚本文件中读取到的每一行的语义,并在此基础上提取相应的关键词和参数,将其编译为解释器可以识别执行的数据结构, 并存入相应状态的动作表中,同时也是语法树存储结构的第一层。 |
|
State |
状态阶段(关键字:state)对应的类声明。有state的内置属性(即所有state共有的必须的数据类型,但不同的state中值可能不一样)。 还包含着state中可能出现的所有动作的具体方法,因为大部分方法都需要访问该当前state中的内置属性,所以将这些与动作相关的方法声明为类方法,减少不必要的传参。 |
|
interpreter |
解释器,用于解释脚本执行程序,因为是根据存储好的语法树进行分析,为了便于灵活访问所需要的内容,所以该类继承analysis。 |
|
swing |
图形界面,实现对话框,检测enter键,按下enter键即为输入。 |
|
log |
日志模块,记录每次执行程序时的交互信息,以及出现的错误信息。 |
|
database |
预留接口,功能尚未完善,可以根据需求完善对数据库的连接或是对本地记录的访问。 |
|
my_exception |
语法分析过程中出错则抛出相应异常,对不同的错误传入不同的参数,构造函数会构造不同的debug信息,继承 RuntimeException 类,只在analysis中使用。 |
|
textarea |
对话框,显示输入输出的内容。带滚动条,所以继承JScrollPane,只在swing中使用。 |
|
TEST |
对程序进行测试的部分,包括对不同功能模块的单元测试以及相应的测试桩,还有对整个程序的自动测试部分。 |
2.模块分析:
(1) Class analysis :
字段概要:
|
修饰符和类型 |
字段 |
说明 |
|
|
|
ac_id记录当前动作标号,即此处为该状态第几个动作,类似于PC寄存器。 |
|
|
|
记录当前正在分析的state。 |
|
|
|
记录当前正在分析的state的id。 |
|
|
|
人机接口:图形界面。 |
|
|
|
ac_id记录当前动作标号,即此处为该状态第几个动作,类似于PC寄存器。 |
|
|
|
分析到的行数,从第一行开始。 |
|
|
|
状态栈,记录状态转的前后关系,存入的是状态id。 |
|
|
|
状态表,状态id与状态实例的哈希索引, 连接语法树存储结构的第二,三层。 |
|
|
|
记录系统输入。 |
|
|
|
变量表,变量与值之间的哈希索引, 连接语法树存储结构的第二,三层。 |
方法概要:
- Syntax_analysis:
public static void Syntax_analysis(String line, BufferedReader br) throws IOException
语法分析函数,识别每个token,并根据不同的token的用法,识别出相应的语义动作以及动作所需参数。
-
- 参数:
line- 从脚本语言中读取的行的内容(String)
br- 文件的BufferedReader,用于读取文件。 - 抛出:
java.io.IOException- 该方法中会有文件I/0异常,自定义编译错误异常的抛出
- 参数:
- compile_ac:
public static void compile_ac(String[] pattern,int i,String line,BufferedReader br) throws IOException
获取该行脚本语言的参数,并将其编译为解释器可以识别的数据结构并储存。
-
- 参数:
pattern- 匹配模式的集合
i- 匹配模式集合的下标
line- 待分析编译的句子
br- 用于读取脚本文件 - 抛出:
IOException- 分析或编译出错时,抛出异常。
- 参数:
- readfile:
public static void readfile(String file_path)
打开并读取脚本语言文件,对读取到的每一行均做语法分析。
-
- 参数:
file_path- 脚本文件所在的路径(String)
- 参数:
(2) Class State :
字段概要:
|
修饰符和类型 |
字段 |
说明 |
|
|
|
所有state的共同属性,为当前state的动作表,里面顺序存储着当前state中要执行的动作。连接着语法树存储结构中的第三和四层,即每个状态中的所有动作。 |
|
|
|
所有state的共同属性,是state的标识符。 |
|
|
input |
所有state的共同属性。保存当前state所读取到的系统输入,因为不同的state在运行时可能会读取到不同的系统输入,所以对每个state都需要有该变量。 |
方法概要:
- Speak:
public void Speak(String s)
方法Speak(……)对应于关键字speak的语义动作
-
- 参数:
s- speak动作所附加的参数,即speak要输出的字符串
- 参数:
- wait_Input:
public void wait_Input(Boolean no_timeout, String var_temp, String sys_in)
对应于关键字wait_input的语义动作,在指定时间长度内等待输入。
-
- 参数:
no_timeout- true表示输入没超时,false表示等待输入超时。
var_temp- 表示当前输入要传给哪一个变量,如果为空则表示由当前state中的input接收。
sys_in- 用户的输入。
- 参数:
- Input:
public void Input(String var_temp, String sys_in)
不需要计时的输入
-
- 参数:
var_temp- 同上
sys_in- 同上
- 参数:
- Goto:
public String[] Goto(ArrayList arr)
用于执行goto模块中状态跳转
-
- 参数:
arr- 所有包含其中的if-then-语句的参数,表示输入情况和状态转移的对应。 - 返回:
返回结果为长度为2的字符串数组,第一个值是要转移至的state的标识符(state_id),第二个是转移后所要执行的动作的标号(ac_id)
- 参数:
- Exit_all:
public void Exit_all(.Stack state_stack)
程序退出函数,会把程序的状态栈全部弹出。
-
- 参数:
state_stack- 程序运行的状态栈,只要状态栈为空,程序边会停止运行。
- 参数:
- get_db:
public void get_db(String name, String index, String result)
从后台数据库或是本地文件中查询相应的结果,并保存至result指向的变量中
-
- 参数:
name- 所要访问数据库中的属性
index- 查询的索引条件
result- 查询的结果
- 参数:
- update_db:
public void update_db(String name, String index, String value, String op)
更新数据库。
-
- 参数:
name- 所要更新的数据库中的属性
index- 索引条件
value- 更新的值
op- 更新动作
- 参数:
(3) Class interpreter :
字段概要:
没有额外的字段声明,继承 Class analysis,可参考 Class analysis 的字段概要。
方法概要:
- run:
public static void run()
分析已得到的语法树,执行脚本程序。 - main:
public static void main(String[] args)
两个二步骤: 编译 执行
-
- 参数:
args-
- 参数:
(4) Class swing :
字段概要:
|
修饰符和类型 |
字段 |
说明 |
|
Font |
font |
界面的字体 |
|
static JFrame |
frame |
窗口 |
|
JLayeredPane |
ip |
层级布局 |
|
JLabel |
lable |
标签 |
|
static textarea |
output |
输出框 |
|
static textarea |
input |
输入框 |
方法概要:
- set_output:
public static void set_output(String out_txet, int id)
界面与程序之间的接口,让程序通过该接口设置输出框中输出的内容。
-
- 参数:
out_txet- 输出的内容
id- 用于区分现输入的角色,0表示机器客服的输入,1表示用户的输入
- 参数:
- exit:
public static void exit()
界面与程序之间的接口,程序调用此接口来关闭界面的窗口。 - copy:
public static void copy(String temp)
界面与程序之间的接口,实现把输入框中的内容传递给后端程序中自定义的系统输入。因为匿名内部类中不支持赋值操作以及声明新变量,所以构造该方法用于将键盘监听的匿名内部类中所得的值传递出去。
-
- 参数:
temp- 输入框中的内容
- 参数:
(5) Class log :
字段概要:
无。
方法概要:
- write:
public static void write(String str, Boolean is_changeline)
写日志
-
- 参数:
str- 所要写入的信息
is_changeline- 是否换行
- 参数:
- clear:
public static void clear()
清空日志
(6) Class database :
字段概要:
|
修饰符和类型 |
字段 |
说明 |
|
|
|
模拟已经存储的数据 |
方法概要:
- get:
public static String get(String attribute, String index)
获取数据库信息
-
- 参数:
attribute- 访问数据库的属性
index- 数据库访问索引 - 返回:
查询所得的值
- 参数:
- set:
public static void set(String attribute, String index, String value, String op)
模拟更新数据库的值。
-
- 参数:
attribute- 所要修改的属性
index- 数据库访问索引
value- 所要更新的值
op- 执行的更新操作,如加,减,重置等。
- 参数:
(7) Class my_exception :
字段概要:
无。
方法概要:
- my_exception:
构造函数
public my_exception(int line,String error_inf)
-
- 参数:
line- 错误出现的行号
error_inf- 错误信息
- 参数:
- my_exception:
构造函数
public my_exception(int line, String var, String error_inf)
-
- 参数:
line- 错误出现的行号
var- 错误出现的变量名
error_inf- 错误信息
- 参数:
- my_exception:
构造函数
public my_exception(String state, String var, String error_inf)
-
- 参数:
state- 错误出现的state的标识符
var- 错误出现的变量名
error_inf- 错误信息
- 参数:
(8) Class textarea :
字段概要:
|
修饰符和类型 |
字段 |
说明 |
|
|
|
JTextArea组件,在构造函数中可以用于自定义JTextArea。 |
方法概要:
- textarea:
public textarea(int x, int y, int len, int wid, Boolean is_edit)
构造函数
-
- 参数:
x- 组件所在的位置的x坐标
y- 组件所在的位置的y坐标
len- 组件的长度
wid- 组件的宽度
is_edit- 组件是否可以编辑
- 参数:
(9) Class TEST :
字段概要:
无
方法概要:
- init_file:
public static void init_file()
清空测试结果文件 - write:
public static void write(String str)
测试结果写回
-
- 参数:
str- 所要写入的测试结果
- 参数:
- test_Syntax_analysis:
public static void test_Syntax_analysis(String file_path)
对语法分析部分的单元测试。
测试目的:确保语法分析部分能够正确的对脚本语言中的动作完成分析,并提取出相关的关键字和参数,以便编译。
-
- 参数:
file_path- 测试集文件的路径
- 参数:
- test_State_method:
public static void test_State_method()
对state中类方法的单元测试,通过日志查看结果。
测试目的:为了确保程序中的每个类方法都能返回正确的结果供解释器使用。 - test_Interpreter:
public static void test_Interpreter()
测试解释器,通过日志查看结果。
测试目的:测试在提供给解释器相对于state_table和state_stack后,解释器能否正常运行。 - TEST_STUB:
public TEST_STUB()
构造函数。
在测试桩构建一个state以及state_table,variable_table,state_stack供单元测试使用。 - get_goto_args:
public ArrayList get_goto_args()
获取一个可以共goto函数使用的参数。
3.语法分析以及编译过程实现:
首先调用模块analysis中的readfile(……)方法打开并读取脚本文件,依次对读取的每一行做语法分析,即调用Syntax_analysis(……)方法。
readfile(String file_path)
{
try
{
BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream(file_path),"UTF-8"));
String line;
while((line=br.readLine())!=null)
{
//对读取的每一行进行语法分析。
//因为会有需要读取多行才能分析的情况,所以把BufferedReader也传入。
Syntax_analysis(line,br);
//记录当前读到行数,便于输出debug信息。
line_num++;
}
} catch (IOException e)
{
e.printStackTrace();
}
}
对于Syntax_analysis(……)方法,根据已经定义好的关键字,设计对应于每个关键字的正则表达式,通过正则表示式来确定正在分析的行的语义动作。
//token匹配模式:
String is_new_state="^\\s*state.*";
String is_speak="^\\s*speak.*";
String is_w_input="^\\s*wait_input.*";
String is_goto="^\\s*goto:.*";
String is_condition1="^\\s*if.*";
String is_condition2="^\\s*default.*";
String is_exit="^\\s*exit_all.*";
String is_variable="^\\s*variable.*";
String is_input="^\\s*input.*";
String is_access_db="^\\s*access_database.*";
String is_update_db="^\\s*update_database.*";
//模式的集合。
String[] pattern={is_new_state,is_speak,is_w_input,is_goto,is_condition1,is_condition2,is_exit,is_variable,is_input,is_access_db,is_update_db};
在模式集合中逐个匹配分析,如果无法与上述正则表达式中任意模式匹配,则意味着遇到了非关键字的token,抛出异常并停止语法分析。
Boolean no_match=true;
for(int i=0;i<pattern.length;i++)
{
//语义动作分析
if(Pattern.matches(pattern[i],line))
{
no_match=false;
//获取该行脚本语言的参数,并将其编译为解释器可以识别的数据结构并储存。
compile_ac(pattern, i, line,br);
……
}
}
if(no_match) throw new my_exception(line_num,"非本语言定义关键字");
如果存在某一模式与所输入行匹配,则可进一步分析该行的语义动作并从中分离关键字以及参数,语义动作分析完成后,即可把分析所得的关键字和参数编译为解释器可以识别的数据结构并储存。
//语义动作分析
compile_ac(pattern, i, line,br)
{
//正则匹配获取参数串
Matcher matcher=Pattern.compile(pattern[i].substring(0,pattern[i].length()-2)).matcher(line);
String arg=matcher.replaceAll("").trim();
//通过匹配到的模式的下标来识别对应的关键字
switch (i) {
//对state的声明,创建一个新的state
case 0:
State s=new State();
//状态标识符只能字符开头,包含字母数字下划线
//进一步对参数进行分析,判断参数组成是否正确,不正确则抛出异常
if(!Pattern.matches("[a-zA-Z]+(_|[a-zA-Z]|\\d)*", arg) )
throw new my_exception(line_num, "状态标识符错误");
s.id=arg;
//记录当前状态,便于把后续动作存入该状态动作表
cur_state=s;
state_table.put(arg, s); //加入状态表
//第一个状态为入口状态
if(is_first_state==1)
{
state_stack.add(arg); //入口状态需要放入状态栈中,因为程序需要从此处开始运行
is_first_state=0;
}
break;
//除了case 0外,以下情况均为所要执行的动作,均需要把分析所得的关键字和参数编译为解释器可以识别的数据结构并储存。
//存储结构:ArrayList<String> ac,表示某一具体动作以及所需参数。
//ArrayList<String> ac 构成语法树存储结构第四,五层之间的联系,每个具体的动作以及其对应的各个参数。
//例如:
//解析到关键字speak
case 1:
//判断参数是否被双引号所包围
if(Pattern.matches("^\".*\"$",arg))
{
//去除双引号
arg=arg.substring(1, arg.length()-1);
//判断speak的参数中是否存在变量。
Matcher matcher_speak_arg=Pattern.compile("%&.+?%").matcher(arg);
while(matcher.find())
{
//从变量表查找变量值
String var_temp= matcher_speak_arg.group().replaceAll("%", "");
//如果该变量为未声明的变量,则抛出异常。
if((analysis.variable_table.get(var_temp))==null)
throw new my_exception(line_num,var_temp,"该变量未声明。");
}
//编译构建语义动作,写入当前state(即该语句所属state)的动作表。
ArrayList<String> ac1=new ArrayList<>(Arrays.asList("speak",arg));
cur_state.action.add(ac1);
}
else //参数不符合情况,抛出异常
{
throw new my_exception(line_num,"speak 参数错误");
}
break;
case 2:
……
break;
case 3:
……
break;
……
default:
//无法解析的语义动作,抛出异常
throw new my_exception(line_num,"无法解析的语义动作");
break;
}
}
经过逐层深入的语法分析与编译,语法树的存储也被逐渐完善。当对脚本编译完成后,即可得到完整的语法树存储结构。而语法树存储结构上各层各个结点的接口均被声明为public类型的成员变量,所以解释器只需要继承存储着语法树的类便能灵活便捷的访问这些接口。
4.解释执行过程实现:
解释执行过程由interpreter模块完成,Class interpreter通过对Class analysis的继承,从而实现对编译后所得到的语法树的灵活访问。
脚本中声明的第一个state即为程序入口,在语法分析和编译过程中会将入口的state放入程序执行栈中(state_stack),每次调用run()方法从栈顶读取所要执行的state,而goto: …… end中的状态转移会将新的状态放入栈中,循环往复,直到栈空即代表程序执行完毕。
而对于从栈顶获取到每个state,都需要获取其动作表,里面顺序存放在该state所要执行的所有动作。
run()
{
while(state_stack.size()!=0)
{
String id=state_stack.peek();//获得栈顶状态id
State state_temp=state_table.get(id); //根据标识符查询对应state实例
ArrayList< ArrayList<String>> ac_table= state_temp.action; //获取当前state的动作表
……
}
}
动作表中每一个表项都是一个具体的语义动作,对于run()方法中获取到的动作表只需要顺序执行里面的语义动作即可,对于识别的具体的语义动作,执行相应的方法即可。
动作表结构如下(对应于语法树结构的最下面三层):
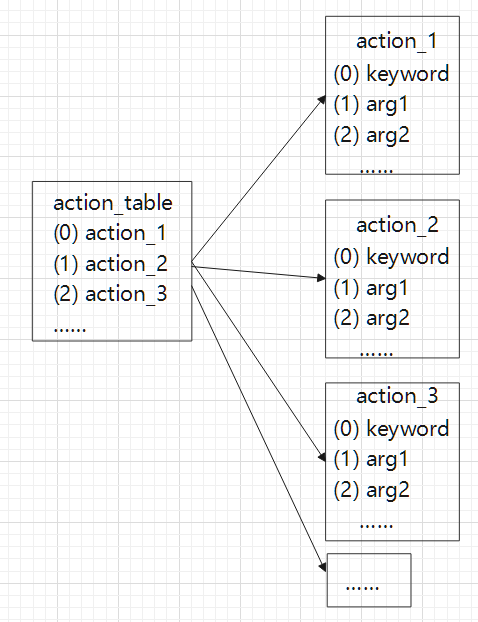
/*
* 接上部分run()的内部
*/
ArrayList< ArrayList<String>> ac_table= state_temp.action; //获取当前state的动作表
//ac_id表示当前状态执行到的动作的标号,从0开始(类似于pc寄存器)。
while(ac_id<ac_table.size())
{
boolean is_goto=false;//表示是否跳转
//顺序读取该状态的具体语义动作。
ArrayList<String> action= ac_table.get(ac_id);
//每个action都是由“关键字”和“参数”两部分构成,第一个单位存放的是关键字,后面存放的是所要用到的所有参数,具体参数格式以及顺序请参考“用户说明pdf”。
switch (action.get(0)) //获取action中的关键字
{
case "wait_input":
Boolean no_timeout=true; //超时标志
//计时器,以100ms为单位
int timer=Integer.parseInt(action.get(1))*10;
//每间隔100ms查看一次界面是否有向后端程序的输入,有则停止,否则直到超时
while(sys_in.equals(""))
{
try
{
Thread.sleep(100);
} catch (InterruptedException e)
{
e.printStackTrace();
}
timer--;
if(timer==0)
{
no_timeout=false;
break;
}
}
//调用wait_input相关方法
state_temp.wait_Input(no_timeout,action.get(2),sys_in);
sys_in="";
ac_id++;
break;
case "speak":
……
break;
case "goto":
……
break;
……
//此处不需要default,如果出现不匹配的状态,在语法分析阶段便会报错。
}
//如果执行了装态转移函数,则不能继续顺序执行该状态的动作,需要跳转至新的状态。
if(is_goto) break;
}
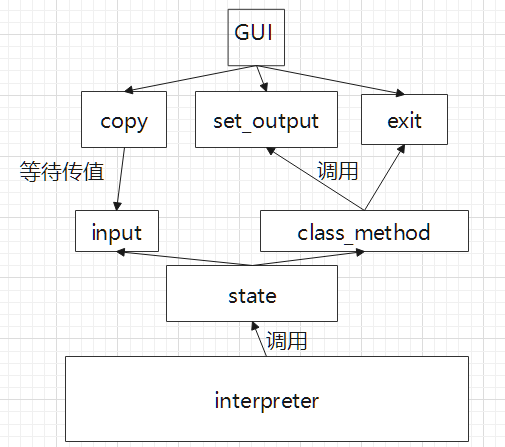
5.程序与界面间的交互:
在界面所属的模块 Class swing 中,声明了三个界面与后台程序的交互方法:
(1) copy(……) : 实现把输入框中的内容传递给后端程序中自定义的系统输入。
(2) set_output(……) : 让程序通过该接口设置输出框中输出的内容。
(3) exit(……) : 程序调用此接口来关闭界面的窗口。
关系图如下:
七.程序测试
1.单元测试以及测试桩:
根据程序的功能划分,主要有负责语法分析以及编译的模块,负责解释执行编译结果的模块,负责对解释结果提供相应的功能函数的模块。对于这三个模块分别设计了相应的单元测试以及其所需要的测试桩,以便对这三个不同功能的单元模块进行测试。
(1)对语法分析以及编译模块的单元测试:
读取测试集文件,对测试集里面脚本语言进行分析,将程序所认为的正确的分析结果输入至指定文件中,对于分析中遇到的程序可以识别的错误,程序会抛出相应的异常,所以只需要判断测试程序输出文件中的分析内容是否符合预期,即可发现程序相应的bug,以便作出修改。
//对语法分析部分的单元测试
//测试目的:确保语法分析部分能够正确的对脚本语言中的动作完成分析,并提取出相关的关键字和参数,以便编译。
public static void test_Syntax_analysis(String file_path)
{
try
{
BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream(file_path),"UTF-8"));
String line;
while((line=br.readLine())!=null)
{
//对读取的每一行进行语法分析
analysis.Syntax_analysis(line,br);
analysis.line_num++;
}
} catch (IOException e)
{
e.printStackTrace();
}
}
举例:
测试集如下:
variable &balan%#ce &number &amount
state wle**come
wait_input &amount 30
speak "账号:%&number%,当前余额为%&balance%元,请问您还需要哪些帮助?"
测试结果:

![]()
可知第一行变量&balan%#ce命名错误,将其修改正确。
![]()
可知第三行state命名错误,将其修改正确。
![]()
可知第四行错误,将其修改正确,即wait_input 30 &amount。
根据测试结果对将测试集修改正确后继续测试,结果如下:
测试集:
variable &balance &number &amount
state wlecome
wait_input 30 &amount
speak "账号:%&number%,当前余额为%&balance%元,请问您还需要哪些帮助?"
测试结果:
variable &balance &number &amount -> ^\svariable\s.
arg: &balance -> [a-zA-Z]+(|[a-zA-Z]|\d)*
arg: &number -> [a-zA-Z]+(|[a-zA-Z] |\d)*
arg: &amount -> [a-zA-Z]+(|[a-zA-Z]|\d)*
-> 空白符或空行
state wlecome -> ^\sstate\s.
arg: wlecome -> [a-zA-Z]+(|[a-zA-Z]|\d)
wait_input 30 &amount -> ^\swait_input\s.
arg: 30 &amount -> ^\d+(\s+&.+\s*)?
speak "账号:%&number%,当前余额为%&balance%元,请问您还需要哪些帮助?" -> ^\sspeak\s.
arg: 账号:%&number%,当前余额为%&balance%元,请问您还需要哪些帮助? -> ^".*"$
-> 空白符或空行
查看测试结果发现语法分析均符合预期。
(2)对负责解释执行编译结果模块(interpreter)的单元测试:
//测试解释器,通过日志查看结果
//测试目的:测试在提供给解释器相对于state_table和state_stack后,解释器能否正常运行。
public static void test_Interpreter()
{
//清空日志,便于查看测试结果
log.clear();
TEST_STUB stub=new TEST_STUB(); //测试桩辅助测试
stub.test_in.run(true); //true代表现在是运行在测试模式下
}
测试桩提供的动作表:
//构造具有活动表的state,并压入state_stack用于对解释器的测试
State ac_1= new State();
State ac_2= new State();
ac_1.id="ac_1";
ac_2.id="ac_2";
ArrayList<String> action_1=new ArrayList<>(Arrays.asList("speak","arg"));
ArrayList<String> action_2=new ArrayList<>(Arrays.asList("wait_input","arg"));
ArrayList<String> action_3=new ArrayList<>(Arrays.asList("goto","arg"));
ArrayList<String> action_4=new ArrayList<>(Arrays.asList("exit_all","arg"));
ArrayList<String> action_6=new ArrayList<>(Arrays.asList("update_database","arg"));
ac_1.action.add(action_1);
ac_1.action.add(action_2);
ac_1.action.add(action_3);
ac_1.action.add(action_4);
ac_1.action.add(action_6);
ArrayList<String> action_5=new ArrayList<>(Arrays.asList("input","arg"));
ac_2.action.add(action_5);
//新构造的state放入state表与栈,测试解释器。
test_anlysis.state_table.put("ac_1", ac_1);
test_anlysis.state_table.put("ac_2", ac_2);
test_anlysis.state_stack.push("ac_2");
test_anlysis.state_stack.push("ac_1");
test_in=new interpreter();
测试结果:
12-21 17:10:35 开始执行。
12-21 17:10:36 获取新state,当前state为:ac_1
12-21 17:10:36 调用speak。
12-21 17:10:36 调用wait_input。
12-21 17:10:36 调用goto。
12-21 17:10:36 调用exit_all。
12-21 17:10:36 调用update_database。
12-21 17:10:36 获取新state,当前state为:ac_2
12-21 17:10:36 调用input。
12-21 17:10:36 程序结束。
查看测试结果,与测试桩提供的动作表相符。
(3)对解释结果提供相应的功能函数模块(State的各个类方法)的单元测试:
此次单元测试中需要使用到State模块中的内置属性input,所以建立测试桩来提供相应的参数与测试所需功能。
//对state中类方法的单元测试,通过日志查看结果
//测试目的:为了确保程序中的每个类方法都能返回正确的结果供解释器使用。
public static void test_State_method()
{
//清空日志,便于查看测试结果
log.clear();
TEST_STUB stub=new TEST_STUB(); //测试桩辅助测试
//对类方法speak的测试
stub.test_state.Speak(""); //空输出
stub.test_state.Speak("dvsahbj"); //普通语句
stub.test_state.Speak("dvsahbj %不是变量% daj"); //不带变量
stub.test_state.Speak("dvsahbj %&var% sdaj"); //带变量&var 值为123
// stub.test_state.Speak("dvsahbj %&no_exist% sdaj"); //带变量,但此变量不存在,会抛出异常
//测试wait_input
stub.test_state.wait_Input(true, "", "1123"); //无超时,无变量,state内置input接收输入
stub.test_state.wait_Input(false, "&var", "1123"); //超时了
stub.test_state.wait_Input(true, "&var", "1123"); //输入给变量
//测试input
stub.test_state.Input( "", "1123"); //无超时,无变量,state内置input接收输入
stub.test_state.Input("&var", "1123"); //超时了
//测试不同输入条件下的goto
//"goto","timeout","0","state_1","2_1","1","state_2","default","0","default"
stub.test_state.set_input("dysajknl");
stub.test_state.Goto(stub.get_goto_args());
stub.test_state.set_input("2_1dysajknl");
stub.test_state.Goto(stub.get_goto_args());
stub.test_state.set_input("timeout");
stub.test_state.Goto(stub.get_goto_args());
//测试database
stub.test_state.get_db("balance", "&number", "&balance"); //查询账号为 &number(测试桩中已提供该变量) 的账户的余额,如果成功则&balance会写入变量表
System.out.println(stub.test_anlysis.variable_table.get("&balance"));//如果为null,则表示不成功。
// stub.test_state.get_db("balance", "&num", "&balance");//查询账号为 &num(变量不存在) 的账户的余额,由于变量不存在,正确情况会触发异常
//对数据库的更新,让刚才所查询的余额翻倍
stub.test_state.update_db("balance", "&number", "&balance","add");
//查询完后再访问一次,查看是否翻倍
stub.test_state.get_db("balance", "&number", "&balance");
System.out.println(stub.test_anlysis.variable_table.get("&balance"));
}
通过log文件查看测试结果:
12-21 17:00:35 speak:
12-21 17:00:35 speak:dvsahbj
12-21 17:00:35 speak:dvsahbj %不是变量% daj
12-21 17:00:35 speak:dvsahbj 123 sdaj
12-21 17:00:35 wait_input:1123
12-21 17:00:35 wait_input:timeout
12-21 17:00:35 wait_input:&var 1123
12-21 17:00:35 wait_input:
12-21 17:00:35 input:1123
12-21 17:00:35 input:&var 1123
12-21 17:00:35 input:
12-21 17:00:35 goto模块参数:state_default 0
12-21 17:00:35 goto模块参数:state_2 1
12-21 17:00:35 goto模块参数:state_1 0
12-21 17:00:35 access_database执行完成。
12-21 17:00:35 update_database执行完成。
12-21 17:00:35 access_database执行完成。

数据库中相应数据翻倍,更新数据库操作无误。
![]()
(4)测试桩集合:
单元测试调用该集合中不同的测试桩,从而获取一些所需的功能和数据,或是特定的数据结构。而在此Class中,可以声明各种所需要的测试桩供单元测试调用。
public class TEST_STUB
{
//在测试桩构建一个state以及state_table,variable_table,state_stack供单元测试使用
public State test_state;
public analysis test_anlysis;
public interpreter test_in;
public TEST_STUB()
{
test_state=new State();
……(定义测试桩所需要的提供的功能和数据,以及特定的数据结构)
test_anlysis=new analysis();
……(定义测试桩所需要的提供的功能和数据,以及特定的数据结构)
test_in=new interpreter();
……(定义测试桩所需要的提供的功能和数据,以及特定的数据结构)
}
//获取一个可以共goto函数使用的参数
public ArrayList<String> get_goto_args()
{
ArrayList<String> goto_action=new ArrayList<>();
……(定义所需要的一些参数,用于完成对指定功能的测试)
return goto_action;
}
}
2.自动测试:
脚本正常情况下被编译执行后是根据用户的输入信息做出判断并执行相应的动作作为回应,所以可以为自动测试程序提供一些交互信息集合,模拟用户的输入来进行自动测试。为了使得测试结果更加具有普适性,这些交互信息需要包含多种情况的输入,测试对于不同的输入信息(符合要求的,不符合要求的),脚本解释程序会做出什么样的反应。
因为正常情况下解释器是从键盘读取输入,而对于自动测试程序,为了使自动测试程序能够自动执行,需要将解释器读取输入的方式重定位至自动测试程序,从而可以做到自动输入自动执行。
对解释器获取输入的重定位,从自动测试程序中获取输入:
//输入的重定位后的解释器
public class auto_interpreter extends analysis
{
//正常情况下sys_in用于从键盘读取输入,为Class analysis的成员变量,但为了使得解释器可以从自动测试程序获取输入,为解释器单独声明属于自己的读取输入方式。
public static String sys_in="";
public auto_interpreter()
{ //语法分析并编译脚本文件
readfile("D:\\eclipse for java\\DSL\\script.txt");
}
//此处与正常解释器基本相同,用于执行编译后的脚本
public static void run()
{
……
}
}
public class TEST_AUTO
{
//交互信息,根据脚本功能情况不同,可以制定不同输入集合
private static String[] answer_1= {"账单","余额","充值","办理业务","投诉","退出","阿巴阿巴","对对对","我不理解","超时","需要","没有","不需要",""};
private static String[] number= {"12345","54321","55555","66666","77777"};
private static String[] name= {"班建龙","收手了","阿祖"};
//从交互信息中随机读取并将结果写入解释器的sys_in中,实现自动输入,但要保证大体流程正确。
public static String get_input()
{
……
}
//对话情况写入文本auto_test_res.txt中,每次测试结束即可查看文本,判断测试情况是否正确
public static void write
{
……
}
//每次运行前清空文本
public static void clear()
{ …… }
//自动测试执行过程。
public static void main(String[] args)
{
clear();
auto_interpreter in=new auto_interpreter();
in.run();
}
}
测试结果举例:
您好,请问需要哪些帮助?
(我可以查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
账单
您好,请问您的姓名是?
阿祖
未查询到当前账户
(如:查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
办理业务
您好,请问您具体想办理什么业务?
退出
您好,该业务请前往线下营业厅办理。请问您还需要哪些帮助?
(如:查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
没有
您好,这个问题我不太清楚,请问还有其他问题可以帮到您吗?
(如:查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
需要
您好,这个问题我不太清楚,请问还有其他问题可以帮到您吗?
(如:查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
我不理解
您好,这个问题我不太清楚,请问还有其他问题可以帮到您吗?
(如:查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
不需要
您好,这个问题我不太清楚,请问还有其他问题可以帮到您吗?
(如:查询当月账单,查询账号当前余额,充值余额,办理业务,投诉或者选择退出)
退出
祝您生活愉快,再见!
八.改进
- 当前设计中,脚本中语言中已经定义了对数据库或是本地记录文件的访问以及修改的接口,但是并没有实际连接到相应的数据库,同时语言中定义的接口只能访问一个数据库,从中获取或修改不同属性的数据,无法对多个数据库做出访问,所以对于实际的数据库访问功能还有待开发完善。
- 在对数据库的修改中,语言中所定义的关键字的使用(接口)中并没有对身份信息的验证,可以在连接了实际数据库后,加上密码验证,每次执行修改数据库动作的时候,不仅需要指定修改的属性,修改的值以及修改动作,还需要进行身份验证,使得当前用户只能修改本用户的信息。
- 当前设计中的自然语言分析所采用的时关键字匹配方法,对应的分析具有较高的局限性,可以对当前匹配算法做出改进,采用输入语言与关键字的最长公共子序列匹配或是采用较为专业的自然语言分析方法,或是多种语言分析方法共用等。
- 当前设计中的没有定义返回上一个state的关键字或方法,想要返回上一个state,必须采用goto: …… end关键字模块,较为不便,使得代码冗长,可以设计关键字:return,并设计ac_id栈,记录上一个state执行动作所到的位置,执行到关键字return后,state与ac_id自动弹栈,从而实现返回上一个state继续执行。通过此关键字可以较为方便地实现单层返回,这样就不用每次都返回机器客服功能的最上层,或是通过goto : …… end关键字模块繁琐的实现单层返回。
- 对于所定义的用于state间跳转关键之字goto: …… end,有些许繁琐,里面还需要嵌套if - then - 语句才能够实现跳转,编写起来不够简单灵活,可以尝试改为将外部goto以及end去掉,只留下内部的state跳转条件以及跳转结果。原来的goto: …… end只会被编译为一个语义动作,但是这样的改进会使得state的跳转动作被编译为多个语义动作。
九.总结
在程序编写过程中我逐渐有了代码风格的概念,对注释,命名等代码的编写也有了一定的规范。也注重了程序中模块的划分,将功能类似,结合紧密的代码划分为相应的模块。而对于不同的模块之间通过定义特定的接口实现不同模块间的信息传递,而对于不同模块以及给定的接口,通过相应的测试确保其正确性。对于所编写的脚本文件,可以通过自动测试来验证脚本的逻辑正确性。
本次设计实践结合了多方面的知识, 在对脚本语言的分析和编译中应用到了编译原理中语法分析以及正则表达式等相关知识。同时在对语法树的构造中也学习到了不同数据结构之间的嵌套结合,从而产生出新的数据结构。在设计的过程中为了解决如何合理地组织并执行编译后所得到的信息,也运用了之前在CSAPP课程中所学的相关知识,模拟程序运行中的栈结构,以及pc寄存器结构,从而使编译好的信息可以准确地执行。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











