







 本文探讨了一种多条件组合查询的SQL优化案例。原始查询在查询学生作业状态(如待批改、已批改)及按学号、姓名、题目等条件时,执行时间长达20秒。通过将查询条件优化到FROM子句的ON条件中,查询时间显著降低至0.04秒,展示了SQL优化的重要性。
本文探讨了一种多条件组合查询的SQL优化案例。原始查询在查询学生作业状态(如待批改、已批改)及按学号、姓名、题目等条件时,执行时间长达20秒。通过将查询条件优化到FROM子句的ON条件中,查询时间显著降低至0.04秒,展示了SQL优化的重要性。
应用场景
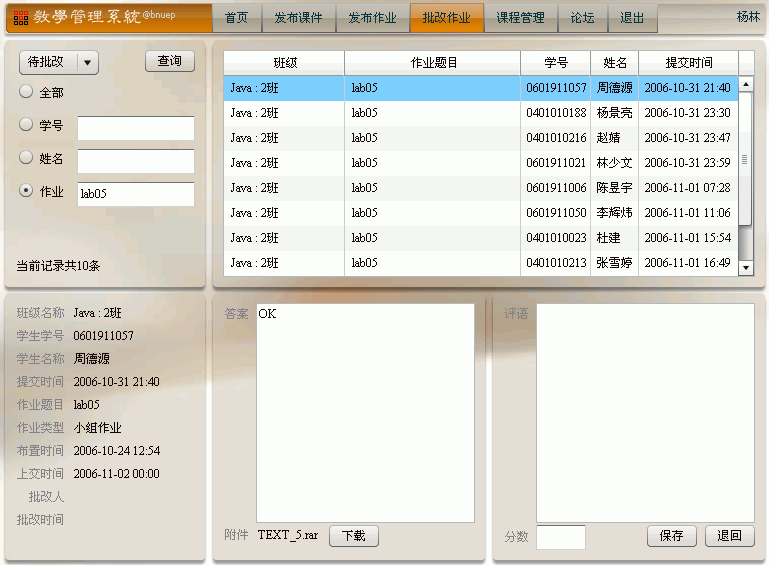
上图中要求按以下条件查询学生作业:
1、按学生作业的状态:全部 / 待批改 / 已批改
2、按学生学号 / 学生姓名 / 作业题目 / 全部
其中1和2是“并”的关系。
原始查询
 ALTER
PROCEDURE
[
dbo
]
.
[
QueryStudentHomework
]
@teacherId
int
,
@state
int
,
--
0:全部,1:已提交,2:已批改,3:已退回
@queryType
int
,
@queryArg
varchar
(
500
)
AS
BEGIN
SET
NOCOUNT
ON
;
DECLARE
@queryIntArg
int
,
@queryStringArg
varchar
(
502
)
IF
(
@queryType
=
1
)
SET
@queryIntArg
=
Convert
(
int
,
@queryArg
);
ELSE IF(@queryType = 2 OR @queryType = 3)
SET
@queryStringArg
=
'
%
'
+
@queryArg
+
'
%
'
SELECT
教学.学生作业.学生作业Id
as
'
@id
'
, 教学.课程.课程简称
+
'
:
'
+
教学.课程班.课程班名称
AS
'
@classname
'
, 教学.作业.作业题目
as
'
@title
'
, 教学.作业.发布时间
as
'
@publishTime
'
, 教学.课程作业.上交时间
as
'
@commitTime
'
,
ALTER
PROCEDURE
[
dbo
]
.
[
QueryStudentHomework
]
@teacherId
int
,
@state
int
,
--
0:全部,1:已提交,2:已批改,3:已退回
@queryType
int
,
@queryArg
varchar
(
500
)
AS
BEGIN
SET
NOCOUNT
ON
;
DECLARE
@queryIntArg
int
,
@queryStringArg
varchar
(
502
)
IF
(
@queryType
=
1
)
SET
@queryIntArg
=
Convert
(
int
,
@queryArg
);
ELSE IF(@queryType = 2 OR @queryType = 3)
SET
@queryStringArg
=
'
%
'
+
@queryArg
+
'
%
'
SELECT
教学.学生作业.学生作业Id
as
'
@id
'
, 教学.课程.课程简称
+
'
:
'
+
教学.课程班.课程班名称
AS
'
@classname
'
, 教学.作业.作业题目
as
'
@title
'
, 教学.作业.发布时间
as
'
@publishTime
'
, 教学.课程作业.上交时间
as
'
@commitTime
'
,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









