






点击蓝字 关注我们
作者:董彬
校对/文章优化:刘轶民
排版:Rani
视频地址:
https://www.bilibili.com/video/BV1NK4y1p7Ys
与世界周旋的程序员
大家好,我叫董彬 ,现就职于野村信息, Title 是 Senior Developer。回头看看过去,我觉得还蛮神奇的。虽然我已经 30 岁了,但作为一名全职的软件工程师也仅有一年的时间。有的人会有一些疑问。为什么这么晚才开始做软件工程师?主要是因为我从 2018 年开始才以边工作边读书的方式,通过远程教育的方法拿到了我人生中的第二个硕士学位,也就是 UIUC 的 Master Ofcomputer Science。
在我上学的这段期间发生过一个非常有趣的事情,在我上学的这段时间发生过一个非常有趣的事情:我的老师曾经在一个期末的时候单独表扬了我,说我们的董斌同学每次期末作业,每次的作业都会提前很早就交上来。这让我感到非常的奇怪。
因为我分别记得我迟交了很多次,后来在和老师核对了之后,才发现事情的原因。因为老师每次在留作业的时候,他都会说我们的截止时间是 2018年10月1号 CST,那我就想当然的以为 CST 和网站上的时间一样,被自动转换成了东 8 区的时间,也就是 China Standard Time。但实际上老师用的是当地的时间,也就是美国的中部标准时间(CST)。所以我以为的截止时间要比老师真正上留的这个时间要早上到 14 个小时,这也就是为什么我每次交作业都要比真正的截止时间要提前很久,不知道有没有其他的同学产生了同样的错误(笑)。

CST 同样还有其他的意思,包括澳大利亚中部时间 (Central Standard Time) 和古巴标准时间(Cuba StandardTime-AUS),时间是一个很美妙的东西,人类为了描述它,引入了很多工具,时区就是其中之一,时区是很复杂的,当大家在一个跨国公司工作需要和不同的国家的员工一起协作,或者是公司本身的产品就服务于世界各地不同的用户的话,那么时区通常情况下都是一个非常令人头疼的问题,时区不是以精度进行完美的划分,它有很多种情况。
它既有可能像中国一样横跨好几个时区,但使用的是统一的时区。也有可能像美国一样,在同一个国家使用不同的时区。甚至有可能在印度一样,虽然只有同一样的时区,但是它是一个非整数的时区,而且还有一些国家现在在使用夏令时。这些所有的可能性让时间的转换变得尤为复杂。
我所在公司曾经有这样一个 RestfullAPI,它以 Json 的数据格式来返回日期,但它返回的日期比数据库中存储的时间要早上一天。这种情况让我们感到非常奇怪。在我们调试的过程中,我们找到了错误的原因:首先这个日期是 Java 中的 Date 数据类型,当它使用 Jdbc 从 Sql Server 中取出这个数据的时候,它会被初始化成为一个本地的时间,然后在序列化的时候,他调用 getTime 方法,得到的是 UTC(1970年1月1日到现在的毫秒数),所以错误产生的原因就是这个本地时间。
虽然他这个服务器真的就在英国,但是它的时区是 BST,也就是 Britain Summer Time,它比 UTC 要早上一个小时,所以当数据库中的2020年10月1号被 Jdbc 取出来之后,它就变成了2020年9月30号的晚上11点。然而作为 API 消费者的我并不知道这个 API 真正的服务器的时区在哪里,所以在对其反序列化后就成了2020年9月30号。错误就是这样产生的。为了解决这个问题,我们应该怎么办呢?
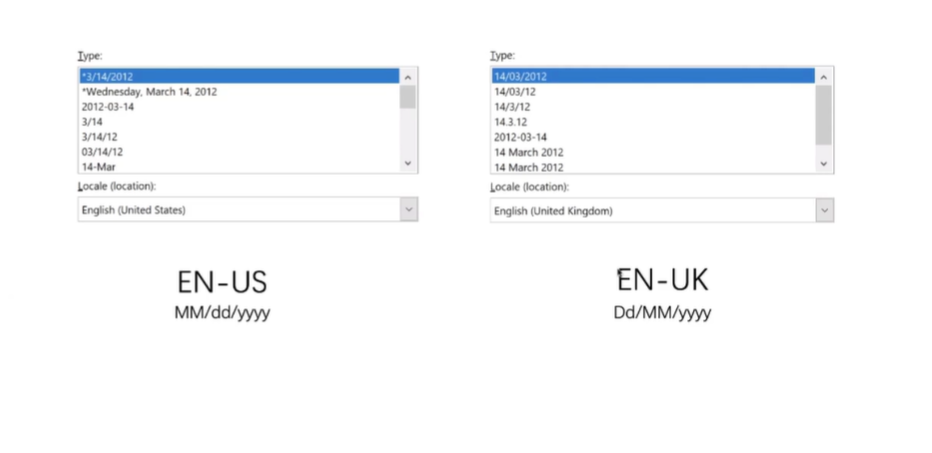
一个最普遍的方法当然就是把日期以一个格式化的字符串的方式来传输出来,那么以格式化的字符串来传输,究竟是不是一个很好的选择呢?在有些情况下其实也不是。因为我们还有另外一个服务,它需要用户上传一个 Excel 模板,在这个 Excel 模板里面,我们规定日期要以 mm/dd/yyyy 的格式来进行传输,我们在本地调试的时候是完全没有问题的,但是交付给用户的时候,我们就发现有些用户总是把日和月写反,无论怎么样告诉他他都是写反。
后来我们仔细研究了一下,才发现这个问题出现在 Excel 上面,因为 Excel 它的日期的默认时间格式是与你本机的语言有关的,我们在用美式英语来进行调试的时候,mm/dd/yyyy 是完全没有问题的,但是我们有相当一部分内部的用户用的是英式英语,对他们来说,他们的短日期格式就是 dd/mm/yyyy,像这种与语言非常相关的日期格式,我们在软件当中被称为 Global Realization 或者是 Internal Realization。我们作为程序员,能力非常有限,不可能了解全世界每一种语言文化的使用习惯,所以我们是非常依赖于软件的基础库的。

在2020年11月发布的 .Net5 当中,就有一个与之相关的破坏性更新。我之所以对这个东西非常有印象,是因为我在开日历控件的时候,遇到了这样一个问题,就是当我们在用 Server Side 模式托管我们的控件库的时候,我们发现它的日期格式与我们以 WebAssernbly 来托管的时间格式不同。为什么我们同样的代码放在不同的托管模式下,会出现这样的不同。
在请教了 .Net 的官方的工作人员后,他们给我的回复是这样的:因为当我们在本机调试的时候以Server Side 端渲染,我们使用的是 Windows 上的 .Net Run Time,它所使用的 i18n 跟 API 是 NLS (National Language Support)。
而当我们以 Webassernbly 进行托管的时候,他所使用的 Run Time 是 Mono。Mono 作为 .Net 最初的开源实现,它所使用的 i18n 的 API 就是 ICU。ICU是 International Component for Unicode。它是一个被广泛使用的国际化组件库,它可以为软件提供非常好的国际化支持和 Unicode 的支持。
作为中国的用户,我们可能对于编码这件事情有非常深刻的理解。比如说我们经常打开一些很古老的软件,它的界面上会有很多乱码,而且我们也听说过“烫烫烫”或者是“锟斤拷”,这样的笑话对吧?那这样编码和解码的错误究竟是怎么样产生的呢?

我们就以“锟斤拷”这个例子来说一下,在 Unicode 中有很多字符是没有办法被显示或者没有办法被定义的。在这种情况下,Unicode 的官方为我们提供了一个专门的字符用来解决这种问题,大家可能现在看不到这个字符。这个字符它在 Unicode 中它的编码是 U+FFD,然后变成二进制之后就是下面的这一串。
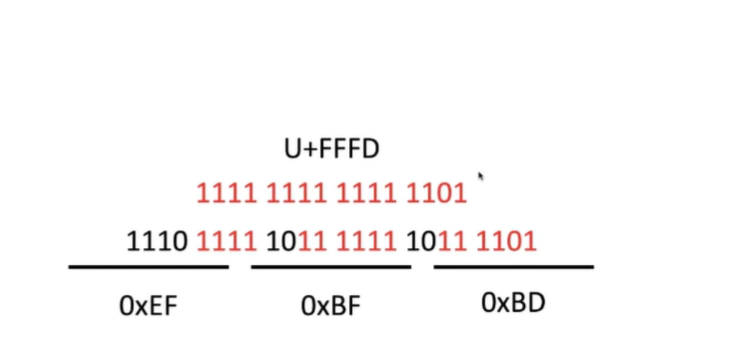
当我们以 UTF8 来进行传输的时候,它就变成第三行的样子。它的16进制格式表示就是下划线下我们看到的样子。当我们有一连串这样的字符传输过来的时候,如果我们以 GB2312 或者是 GBK 来进行反解析的话,我们就会得到"锟斤拷"三个字。
Unicode 是从1990年开始研发到1994年正式发布的,而 GB2312 是从1980年就已经开始使用了,我们不能说 GB2312 没有很好的兼容 Unicode,对吧?事实上的情况就是在 Unicode 正式出现之前,各个国家都有属于自己的不同的编码方案,导致各个国家之间的计算机系统相互交流有非常大的阻碍。所以 Unicode 的出现很方便的解决了大家的这种跨平台跨语言之间的通信和交流。

而且中文是受益非常多的,因为在 Unicode 中差不多有9万个中文字符。包括在日本、韩文以及越南正在使用的一些和中国大陆简体不一样的字形。而且 Unicode 本身也是在不断发展的,它在不断的吸纳新的字符进来。比如2019年为了响应日本新的年号,他就加入了“令和”,到 Unicode 中。在2020年3月发布的 Unicode13 当中,他收录了 4000 多个生僻字,其中也包括我们万众期待的 “biangbiang面” 的 “biang” 字。

而在随着互联网时代的发展,由于后者的更新,还有一个更加大的驱动力,那就是 emoji,又叫绘文字,他起源自日本,在 iPhone 上大放异彩之后迅速的风靡全球,之后就被 Unicode 的官方所接纳,成为了它的一个标准之一。emoji 的出现让大家认识到 Unicode 还有非常多的技术可以挖掘,比如说在人物的 emoji 后面加上 face pattern 的标志,我们就可以让人物呈现不同的肤色????????????????????????????????????????????。
比如说我们可以在嗯嗯,emoji 之间通过零宽连接符进行连接,就可以让不同的人物,不同的性别、不同肤色的人一起组成一个完全不一样的家庭????????????????????????????????????????????????????????????????????,而这些全部都是 Unicode 本身就能实现的,emoji 可以说是互联网时代人们交流方式改变的一个缩影,通过 emoji 一些语言毫不相通的人也能够进行互相的交流,它也算是一种全新的表意文字了,现在大家可能已经习惯在自己的平常的微信交流中夹杂着几个 emoji 。这完全没有问题,对不对?

像这种文化的融合,其实从新文化运动开始,对于中文改革创新来就从来没有停止过,我们不断的吸纳白话文,简体字,标点。但其实这些都对中文本身的固有认知产生了极大的挑战。其中一个最大的挑战就是排版。
对于古人来说,每一个字都是方块字,从上到下书写非常的齐整。但是到了现在,我们的中文之间可以夹杂着半宽的数字,可以夹杂着不等宽的英文字母,还可以带着标点,虽然国标认为标点应该和字符同宽,但是我们对于标点的排版就有额外的要求。比如说我们要避开头尾、点号不能出现在一行的首部、标号的开始不能出现在一行的尾,结束不能出现在一行的头。

这些综合起来看,就对我们软件的排版产生了一个巨大的挑战。这里我给大家举一个微信的例子,这是我自己在微信上进行的测试,大家如果看第一行和第二行的话,我会发现这两行的字符数量并不相等,但是他们视觉上看起来长度是一样的,原因在于为了实现标点的挤压,微信自动的缩短了每个字之间的间隙。
如果大家看到第二行和第三行的话,就会发现这种挤压是因为标点而引起的,他们拥有相同的字符数,但是因为句号因为第三行它不是以标点结尾,所以他就可以换行,但是第二行并不可以换行。而第4行就说明这个句号,如果不是出现在行尾的话,它真的就是一个完整的字符串,而不是一个短短的字符。
那么对于英文来说,排版同样不是轻松的事情,虽然没有标准悬挂这样的问题,但是比如说较长的字单词可能需要按音节来阶段,或者是字母之间,因为不能有太大间隙,所以我们只能调节单词之间的间隙。大家可以意识到仅仅是对于显示一段文字这样简单的一个任务,对于不同的语言来说,就已经有如此复杂的问题出现了,那么其实还有更多的语言,它在固有认知上就已经在挑战我们对于排版,对于软件界面的这种固有的认知。
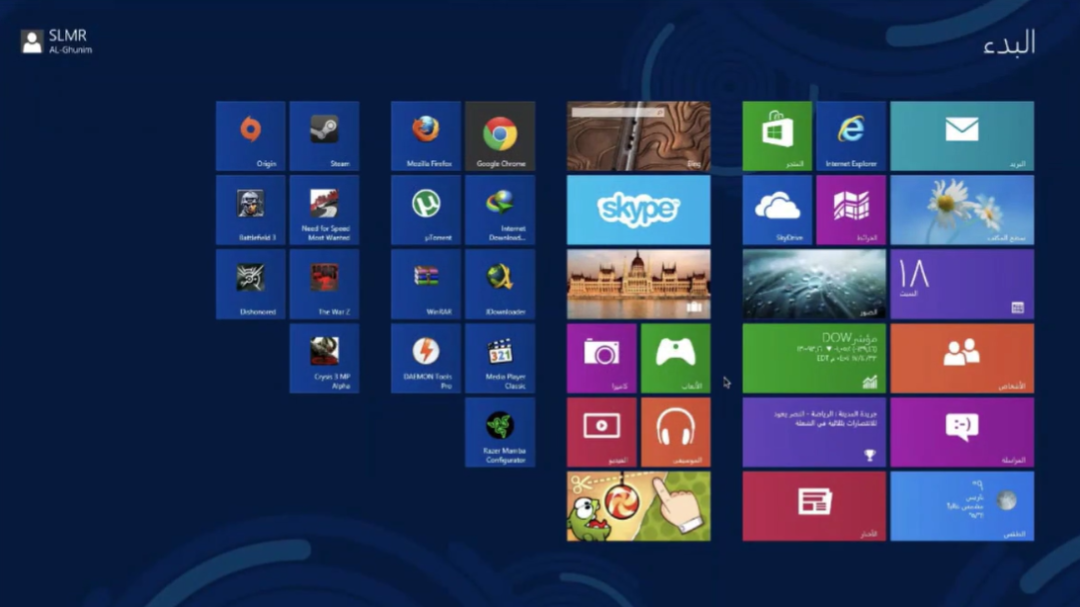
比如说阿拉伯文,它是从右向左书写的,那么这就要求很多软件的界面都要适这种模式。现在大家看到的就是阿拉伯文的 Windows8 的开始界面,大家可以看到与我们常用的 WindowsOS 是完全镜像的。但由于伊斯兰教是目前世界上的三大宗教之一,所以对于阿拉伯文的排版依然有非常巨大的市场。那么对于一些非常小众的语言,我们又该怎么办呢?

我是一名内蒙古呼伦贝尔人,所以我这里要不得不提一下,我们的回鹘式蒙古文。大家看到这段论文是我在网上随便看到的,他的意思我并不明白,所以它不代表我的立场,也不代表 MSReactor 的立场。回鹘式蒙古文是从上到下书写,每个单词都有不同的长度,那么对于我们现在的这种 UI 的架构,它就是完全不适用的。至今为止内蒙古自治区依然使用回鹘式蒙古文作为我们的官方语言之一,对于蒙古国而言,他们也将在 2025 年之前完全恢复使用回鹘式蒙古文。
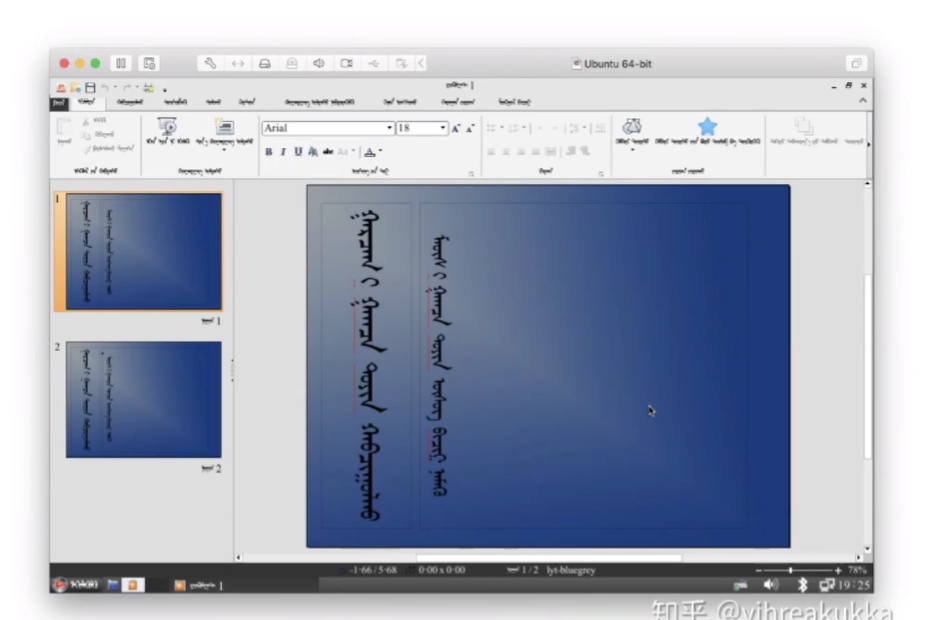
但是对于现在的各大操作系统软件来说,回鹘式蒙古文的显示依然是一个巨大的问题,至今各大操作系统都没有一个完美的解决方案,只能退而求其次使用西里尔蒙文。
我今天的演讲差不多也就到这里结束了,在故事的最后我想讲圣经上的一个小故事。在大洪水之后,人们其实是讲着同样的语言的,大家想齐心协力建造了无与伦比的巴比伦城,想去建造了一座高塔直通云霄。
这让上帝感到非常的震惊,所以他就来到了人间,教会了人们使用不同的语言,把人们分散在世界各地。所以这个伟大的巴别塔也就无疾而终了。直到今日我们依然分散在世界的各地,说着不同的语言,用着不同的文字、传承着不同的文化。但是作为程序员的我们其实是在通过另一种方式打破这种屏障,与“上帝”进行周旋。
我们一方面试图打破屏障,把世界各地不同的人们联系在一起,另一方面我们又在极力的竭尽所能的维护着这个世界的多样性。最后我也感谢这个互相连接的世界,能够给我这个机会,让我在远14个小时时区之外的中国能够完成这个学业,一起参与到这个伟大的事业当中。

球分享

球点赞

球在看














 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









