






生成式AI的热度不减,大语言模型(LLM)不断进化层出不穷,而我却把眼光投向了小语言模型(SLM)。微软的Phi模型家族,就是SLM的佼佼者。那么SLM有着怎样的价值,而Phi为什么又能被称之为优异的SLM代表,其优秀的性能和多模态能力到底如何,又是怎么实现的?不妨花一盏茶的时间,和我一起来了解一下。

Satya发布支持运行在PC上的Windows Copilot和设备侧Phi模型
我将分几个部分介绍:1、为什么需要SLM。简短说明SLM的定义和用处;2、为什么Phi是优异的SLM。将对Phi模型家族的代系作说明,借以帮助理解SLM的研究进程,篇幅较长,不关注模型细节的也可以跳过;3、Phi模型使用的“黑科技”。简要分析Phi模型优异表现背后的一些技术因素。4、在最后有简短的个人理解,供大家探讨。您可以按照喜好自由选择阅读。
在文后提供了有关模型资料(M*的引用)和内容(L*的引用)的链接,可供进一步学习了解参考。
有LLM,还要SLM吗?
谈论SLM之前,首先聊聊为什么需要SLM。在大多数朋友的认识里,从GPT-3开始我们看到了LLM的威力,引领了生成式AI(genAI)时代的到来。随着GPT-3.5、GPT-4、GPT-4v到GPT-4o,甚至很快可能面世的下一个GPT版本,LLM的参数不断增加,训练的数据不断增长,能力也越来越强。在这样的背景下,为什么还要去研究SLM呢?难道小规模的SLM模型也能像LLM一样神通广大吗?
从模型的能力来说,SLM肯定是弱于LLM的,毕竟在工作原理相同的前提下,参数量也是模型性能的影响因素之一。如果仅从使用效果考虑,当然人人都恨不得使用最领先的LLM。但是,我们也要看到genAI使用场景的一些限制,例如,考虑到使用数据(包括我们和AI对话时输入的数据)的安全合规,考虑到需要离线或弱网条件下的使用(比如车载甚至航天领域),考虑到边缘设备的算力、内存限制(比如手机或电脑设备上运行模型)等场景,可能无法使用LLM来完成工作,这时候牺牲一部分性能使用SLM可能是更好的方案。
从模拟人脑模式工作来说,随着智能体概念和Agent/Assistant等工作模式的渐入人心,LLM越来越多的被定位用作沟通和指挥的角色。正如我在很久之前的AI活动中经常提到的一点看法:LLM的名字是大语言模型,但它的实质是面向表达的。所以当多模态能力开始支持图片、视频和语音的时候,甚至人们开始用LLM来研究蛋白质和化合物组成的时候,我一点都不惊讶,因为基于概率token生成的表达就是LLM的实质。因而LLM自然就可以充当起“传统”AI模型与人沟通之间的桥梁。我们也把这个称之为AI的新范式:LLM尝试理解你要什么,然后调用自己或其他AI模型或工具,完成上述需求。那么,从这样的一个定位来看,不正好就对应了人脑额叶的功能吗?
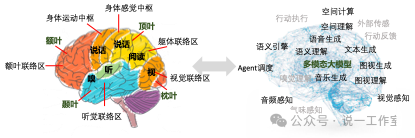
人脑功能区域和人工智能不同能力的粗略逻辑比较
基于上述的思考,我们也许就能理解SLM的用处了——我们当然希望所有的问题都由全知全能的LLM来帮助解答,但很多的时候考虑到成本、实际需求的复杂度,是不是表现良好的SLM就能够满足呢?一个不一定恰当的例子,好比我们需要一位前台接待帮助完成简单的询问协调工作,尽管可能工作在科技公司、需要了解公司的各种情况,但也没有必要在有限的薪酬预算里去找专业博士毕业的人选吧?SLM的用处正在于此,在特定受限的场景下可以利用SLM满足沟通需求并帮助规划调度需要的更高要求的模型或工具。我想这就是目前我们看到的SLM的巨大价值。这方面的例子,例如微软正在推广的AI PC,就可以使用PC能够运行的框架,例如CUDA或者更灵活的DirectML[L1](支持ONNX Runtime[L2])等来实现本地模型的运行。
Phi模型是SLM的优异代表?
其实在Phi模型之前,对于相对LLM更小规模语言模型的很多研究就已经进行(例如微软的另一个项目Orca),但完整的提出SLM并通过逐步的研究实践证实其能力,在我认知范围内Phi模型是更加显著并且一直持续至今的。尤其在今年,Phi-3和Phi-3.5两代模型带来了不小的惊喜。为了便于了解Phi模型的发展脉络,不妨对其发展(研究)历史简单回顾。
Mini | Small | Medium | Vision | |
Phi-1 | Phi-1 (1.3B) | - | - | - |
Phi-1.5 | Phi-1.5 (1.3B) | - | - | - |
Phi-2 | Phi-2 (2.7B) | - | - | - |
Phi-3 | Phi-3-mini (3.8B) 4K和128K上下文 | Phi-3-small (7B) 4K和128K上下文 | Phi-3-meduim (14B) 8K和128K上下文 | Phi-3-vision (4.2B) 128K上下文 |
Phi-3.5 | Phi-3.5-mini (3.8B) 128K上下文 | - | Phi-3.5-MoE (42B) 128K上下文 | Phi-3.5-vision (4.2B) 128K上下文 |
Phi模型家族略表(未对所有模型列举)
Phi模型至今已经发布了5个代系,从参数规模来看,有所增加,相应能力的提升就更加显著了。为了便于跟随了解这个发展历程,接下来我将把各代系的模型代表的简要说明以及训练情况罗列。为节省时间,如果已经比较了解这些模型的,您可以跳到下一节内容继续。
Phi-1
模型摘要
语言模型 Phi-1 [M1]是一个具有 13 亿参数的 Transformer模型,专门用于基本的 Python 编码。其培训涉及各种数据源,包括 The Stack v1.2 [L3] 中的 Python 代码子集、StackOverflow[L4] 中的问答内容、code_contests[L5] 中的竞赛代码以及 gpt-3.5-turbo-0301[L6] 生成的合成 Python 教科书和练习。尽管与当代大型语言模型 (LLM) 相比,该模型和数据集相对较小,但 Phi-1 在简单的 Python 编码基准 HumanEval 上表现出了令人印象深刻的超过 50% 的准确率。
- 架构:具有下一个token预测目标的基于 Transformer 的模型
- 数据:54B tokens(7B 唯一tokens)
- 精度:fp16
- 使用8个A100 GPU训练6天
发表论文
Phi-1发表了论文,说明在小规模参数下的研究:使用从网络上精选的 "教科书质量”数据(6B 词库)以及用 GPT-3.5 合成的教科书和练习(1B 词库),训练多遍(7B数据训练54B)达到了很好的效果。

Textbooks Are All You Need
(GUNASEKAR等, 2023) http://arxiv.org/abs/2306.11644
Phi-1.5
模型摘要
语言模型 Phi-1.5[M2]是一个具有 13 亿参数的 Transformer模型。它使用与 phi-1[M1] 相同的数据源进行训练,并通过由各种 NLP 合成文本组成的新数据源进行增强。当根据测试常识、语言理解和逻辑推理的基准进行评估时,Phi-1.5 在参数少于 100 亿个的模型中表现出近乎最先进的性能。Phi-1.5 没有进行微调。为了获得更安全的模型发布,从训练中排除了通用的 Web 爬虫数据源,例如 common-crawl。此策略可防止直接暴露于可能有害的在线内容,从而提高模型在没有 RLHF 的情况下的安全性。但是,该模型仍然容易受到生成有害内容的影响,希望该模型可以帮助研究界进一步研究语言模型的安全性。Phi-1.5 可以写诗、起草电子邮件、创建故事、总结文本、编写 Python 代码(例如下载 Hugging Face transformer 模型)等。
- 架构:具有下一个token预测目标的基于 Transformer 的模型
- 数据:数据集30B tokens,训练数据 150B tokens
- 精度:fp16
- 使用32个A100-40G GPU训练8天
发表论文
随Phi-1.5发表了一篇新的论文,重点放在加强自然语言常识推理,并且看到了接近LLM的特性。

Textbooks Are All You Need II: phi-1.5 technical report
(LI等, 2023) https://arxiv.org/abs/2309.05463
Phi-2
模型摘要
Phi-2[M3] 是一个具有 27 亿参数的 Transformer模型。它使用与 Phi-1.5[M2]相同的数据源进行训练,并增加了一个由各种 NLP 合成文本和过滤网站组成的新数据源(出于安全和教育价值)。当根据测试常识、语言理解和逻辑推理的基准进行评估时,Phi-2 在参数少于 130 亿个的模型中展示了近乎最先进的性能。
- 架构:具有下一个token预测目标的基于 Transformer 的模型
- 上下文长度:2048 tokens
- 数据:数据集250B tokens,由 AOAI GPT-3.5 创建的 NLP 合成数据与来自 Falcon RefinedWeb 和 SlimPajama 的过滤 Web 数据的组合,由 AOAI GPT-4 评估。训练数据1.4T tokens。
- 使用96个A100-80G GPU训练14 天
技术报告
Phi-2模型推出时并未发表论文,正值Ignite 2023时由Satya宣布发布,微软研究院提供了技术报告博客。模型参数增加到了2.7B,在少于13B规模的模型中有着优异的表现,这归功于模型扩展和训练数据管理方面的新创新。

Phi-2: The surprising power of small language models
https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models
Phi-3
从Phi-3代系开始,Phi模型按规格和多模态能力分为不同的系列,每个系列又提供不同的上下文长度能力。所以我们以其中几个代表来了解。
Phi-3模型使用的词汇表大小分别是:mini为32064 tokens、small为100352 tokens、medium为32064 tokens。
Phi-3-mini-128k-Instruct
模型摘要
Phi-3-Mini-128K-Instruct[M4]是一个使用 Phi-3 数据集训练的 38 亿个参数的轻量级先进开放模型。此数据集包括合成数据和经过筛选的公开可用网站数据,重点是高质量和推理密集的属性。该模型属于 Phi-3 系列,Mini 版本有两种变体,4K和 128K,这是它可以支持的上下文长度(以token为单位)。
在初始训练后,该模型经历了一个训练后过程,包括监督微调和直接偏好优化,以增强其遵循指示和遵守安全措施的能力。当根据测试常识、语言理解、数学、编码、长期上下文和逻辑推理的基准进行评估时,Phi-3 Mini-128K-Instruct 在参数少于 130 亿个的模型中表现出稳健和最先进的性能。
- 架构:Phi-3-Mini-128K-Instruct 具有 3.8B 参数,是一种密集的纯解码器 Transformer 模型。该模型通过监督微调 (SFT) 和直接偏好优化 (DPO) 进行微调,以确保与人类偏好和安全准则保持一致。
- 上下文长度:128K tokens (另有4K型号)
- 数据:4.9T tokens
- 使用512 个 H100-80G GPU训练了10 天
训练数据包含多种来源:
-
公开可用的文档经过严格的质量筛选,精选了高质量的教育数据和代码;
新创建的合成的“教科书式”数据,用于教授数学、编码、常识推理、世界常识(科学、日常活动、心智理论等);
涵盖各种主题的高质量聊天格式监督数据,以反映人类在不同方面的偏好,例如遵循指示、真实、诚实和乐于助人。
我们关注的数据质量可能会提高模型的推理能力,并且我们会筛选公开可用的文档以包含正确的知识水平。例如,某一天英超联赛的结果可能是 Frontier 模型的良好训练数据,但我们需要删除此类信息,以便为小尺寸模型留出更多模型推理能力。
Phi-3模型进行了微调,可参考使用 TRL 和 Accelerate 模块的多 GPU 监督微调 (SFT) 的基本示例[L7] 。可参考Phi-3技术报告(Phi-3模型系列最后的发表论文小结)。
Phi-3-small-128k-instruct
模型摘要
Phi-3-Small-128K-Instruct [M5]是一个 7B 参数、轻量级、最先进的开放模型,使用 Phi-3 数据集进行训练,其中包括合成数据和过滤的公开可用网站数据,专注于高质量和推理密集属性。该模型属于 Phi-3 系列,Small 版本有两种变体:8K和128K上下文长度。和Mini版本一样,也经过后训练过程调整。当根据测试常识、语言理解、数学、代码、长上下文和逻辑推理的基准进行评估时,Phi-3-Small-128K-Instruct 在相同尺寸和次长型号中展示了稳健和最先进的性能。
- 架构:Phi-3 Small-128K-Instruct 具有 7B 参数,是一个密集的仅解码器 Transformer 模型,具有交替的密集和块解析注意力。该模型通过监督微调 (SFT) 和直接偏好优化 (DPO) 进行微调,以确保与人类偏好和安全准则保持一致。
- 上下文长度:128K tokens(另有8K型号)
- 数据:4.8T tokens
- 使用1024个H100-80G GPU训练18 天
数据和优化说明与Mini相同,可参考Phi-3技术报告(Phi-3模型系列最后的发表论文小结)。
Phi-3-medium-128k-instruct
模型摘要
Phi-3-Medium-128K-Instruct[M6] 是一个 14B 参数、轻量级、最先进的开放模型,使用 Phi-3 数据集进行训练,其中包括合成数据和过滤后的公开可用网站数据,侧重于高质量和推理密集属性。该模型属于 Phi-3 系列,Medium 版本有两种变体,4k和 128K上下文长度。该模型经历了一个后训练过程,其中包括监督微调和指令遵循和安全措施的直接偏好优化。当根据测试常识、语言理解、数学、代码、长上下文和逻辑推理的基准进行评估时,Phi-3-Medium-128K-Instruct 在相同尺寸和次长的模型中展示了稳健和最先进的性能。
- 架构:Phi-3-Medium-128k-Instruct 具有 14B 参数,是种密集的纯解码器 Transformer 模型。该模型通过监督微调 (SFT) 和直接偏好优化 (DPO) 进行微调,以确保与人类偏好和安全准则保持一致。
- 上下文长度:128k tokens (另有4K型号)
- 数据:4.8T tokens
- 使用512 个 H100-80G GPU训练42 天
数据和优化说明与Mini相同,可参考Phi-3技术报告(Phi-3模型系列最后的发表论文小结)。
Phi-3-vision-128k-instruct
模型摘要
Phi-3-Vision-128K-Instruct[M7] 是一种轻量级、最先进的开放式多模态模型,建立在精选的数据集之上,其中包括:合成数据和过滤的公开可用网站,以及专注于非常高质量、推理的密集文本和视觉数据。
该模型属于 Phi-3 模型系列,多模态版本可支持 128K 上下文长度。该模型经过了严格的增强过程,结合了监督微调和直接偏好优化,以确保精确的指令遵守和稳健的安全措施。
- 架构:Phi-3-Vision-128K-Instruct 具有 4.2B 参数,包含图像编码器、连接器、投影仪和 Phi-3 Mini 语言模型。
- 上下文长度:128K tokens
- 数据:500B 视觉和文本 tokens
- 使用512 个 H100-80G GPU训练1.5 天
- 输入文本和图像,适合使用聊天格式的提示,输出文本。
训练数据包括多种来源,并且是:
-
公开可用的文档经过严格筛选的质量,精选的高质量教育数据和代码;
选定的高质量图像文本交错;
新创建的“教科书式”综合数据,用于数学教学、编码、常识推理、世界常识(科学、日常活动、心智理论等),新创建的图像数据,例如图表/表格/图表/幻灯片;
高质量的聊天格式监督数据涵盖各种主题,以反映人类在不同方面的偏好,例如遵循指示、真实、诚实和乐于助人。
数据收集过程涉及从公开可用的文档中获取信息,并采用细致的方法来过滤掉不需要的文档和图像。为了保护隐私,我们仔细筛选了各种图像和文本数据源,以从训练数据中删除或清除任何潜在的个人数据。更多详细信息可以参考Phi-3技术报告(Phi-3模型系列最后的发表论文小结)。
Phi-3-vision模型还支持微调,参考“Vision的Phi-3 CookBook微调配方”[L8]。
发表论文

Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
(ABDIN等, 2024) http://arxiv.org/abs/2404.14219
Phi-3.5
Phi-3.5模型支持最大 32064 tokens 的词汇表大小。分词器文件[L9]已经提供了可用于下游微调的占位符标记,但它们也可以扩展到模型的词汇表大小。词汇表的大小意味着模型能够识别和处理的不同词汇的数量。较大的词汇表可以处理更多的词汇和短语,从而提高模型在理解和生成复杂语言时的表现。然而,较大的词汇表也可能增加模型的计算复杂度和训练时间。
Phi-3.5-mini-instruct
模型摘要
Phi-3.5-mini[M8] 是一种轻量级、最先进的开放模型,建立在用于 Phi-3 的数据集(合成数据和过滤的公开可用网站)之上,专注于非常高质量、推理密集的数据。该模型属于 Phi-3 模型系列,支持 128K token上下文长度。该模型经历了严格的增强过程,结合了监督微调、近端策略优化和直接偏好优化,以确保精确的指令遵守和稳健的安全措施。
这是对 2024 年 6 月根据宝贵用户反馈进行的指令调整的 Phi-3 Mini 版本的更新。该模型使用了额外的训练后数据,从而在多语言、多轮次对话质量和推理能力方面取得了显著的进步。
- 架构:Phi-3.5-mini 具有 3.8B 参数,是一种密集的仅解码器 Transformer 模型,使用与 Phi-3 Mini 相同的分词器。
- 上下文长度:128K tokens
- 使用512 个 H100-80G GPU训练10 天
- 数据:3.4T tokens 训练数据
Phi-3.5-MoE-instruct
模型摘要
Phi-3.5-MoE[M9] 是一种轻量级、最先进的开放模型,建立在用于 Phi-3 的数据集(合成数据和过滤的公开可用文档)之上,专注于非常高质量、推理密集的数据。该模型支持多语言,并附带 128K 上下文长度(以令牌为单位)。该模型经历了严格的增强过程,结合了监督微调、近端策略优化和直接偏好优化,以确保精确的指令遵守和稳健的安全措施。该模型的MoE拥有16个专家,具有6.6x3.8B参数和2B有效参数(很奇怪吧?将在后文MoE加以解释) 。该模型推理能力优于更大的模型,仅次于GPT-4o-mini,但某些任务仍受限于模型大小限制,因为没有存储太多事实知识的能力。可以通过搜索增强生成(RAG)来解决此类问题。
- 架构:Phi-3.5-MoE包含16个Experts具有16x3.8B,42B参数,同时2个Experts具有6.6B 激活参数(数字不大对?后文MoE解释)。该模型是一个仅限专家解码器的 Transformer 模型,使用词汇量为 32,064 的分词器。
- 上下文长度:128K tokens
- 数据:训练数据4.9T tokens
- 使用512个 H100-80G GPU训练 23 天
Phi-3.5-vision-instruct
模型摘要
Phi-3.5-vision[M10] 是一种轻量级、最先进的开放多模态模型,建立在数据集之上,其中包括合成数据和过滤过的公开网站,专注于非常高质量、推理密集的文本和视觉数据。该模型属于 Phi-3 模型系列,多模态版本可以支持 128K 的上下文长度(以标记为单位)。该模型经过了严格的增强过程,结合了监督微调和直接偏好优化,以确保精确的指令遵守和强大的安全措施。
Phi-3.5的多模态模型支持多帧图像理解和推理。主要示例多帧能力包括详细的图片对比、多图片汇总/讲故事和视频汇总,这些能力在Office场景中有着广泛的应用。我们还观察到大多数单图像基准测试的性能改进,例如,将 MMMU 性能从 40.2 提高到 43.0,MMBench 性能从 80.5 提高到 81.9,文档理解基准 TextVQA 从 70.9 提高到 72.0。平均而言,Phi-3.5-vision模型在相同尺寸上优于竞争对手模型,并且在多帧功能和视频摘要方面与更大的模型具有竞争力。
- 架构:Phi-3.5-vision 有 4.2B 参数,包含图像编码器、连接器、投影仪和 Phi-3 Mini 语言模型。
- 上下文长度:128K Tokens
- 数据:500B tokens训练(视觉 + 文本)
- 使用256个 A100-80G GPU训练6天
- 输入文本和图像,适合使用聊天格式的提示,输出文本响应
Phi模型的“黑科技”?
Phi模型一代更比一代强,也比同期出现的相近甚至更大规模的其他模型强,那么到底使用了哪些“黑科技”来帮助Phi模型家族实现了这些性能的飞跃呢?
从4K到128K
在开始解释如何外扩上下文长度之前,我们首先了解一下Token化和位置编码。
Token化与位置编码
Token化是Transformer类模型输入输出的基础。不同模型对于文本等内容的向量转化(例如Embedding)也有所不同,例如:

GPT-3和GPT-3.5/GPT-4的token化以及token id
Token化矩阵
Token化矩阵由输入文本转换为token id的序列
每行一个token,每列一个token id特定维度(特定特征)
位置编码矩阵
将位置信息加入到token表示中的矩阵
每行一个位置(token在序列中的位置),每列一个特定维度(与token embedding维度相同)
主要区别
1. 生成方式:
- Token化矩阵:通过tokenizer生成,基于输入文本的内容。
- 位置编码矩阵:通过位置编码方法生成,基于token在序列中的位置。
2. 作用:
- Token化矩阵:将文本转换为模型可以处理的格式。
- 位置编码矩阵:提供位置信息,使模型能够捕捉到序列中token之间的关系。
3. 结合方式:
- Token化矩阵:直接作为模型的输入。
- 位置编码矩阵:与token embedding相加或结合,形成包含位置信息的token表示。
Token化产生的token由此产生位置信息,所以先Token化,再位置编码。一个token id可能会被映射到一个高维向量,例如1536维,文本输入通过嵌入模型后会匹配对应的token id,而一个token id对应了一个高维向量。token id的例子可以在OpenAI关于嵌入的页面看到,输入的文本会变成包含有token id的序列。
位置编码
Transformer模型之所以能够取得如此卓越的效果,其中的Attention机制功不可没,它的本质是计算输入序列中的每个token与整个序列的注意力权重。

Attention Is All You Need
(VASWANI等, 2017) http://arxiv.org/abs/1706.03762
这就不得不提到大语言模型的开山之作“Attention Is All You Need”。还记得我们介绍Phi模型的开篇论文“Textbooks Are All You Need”吗?我个人认为这是一种对Transformer开创研究的致敬。
如果没有加入位置信息,词向量之间的注意力权重和词向量的位置无关,这显然和人的语言直觉不符。为了实现较近词向量之间的注意力权重更大,较远的更小,就需要为模型引入位置编码,让词向量能够感知在输入序列中所处位置。
绝对位置编码
绝对位置编码(Absolute Positional Encoding)在训练阶段就让每个位置的位置向量随模型一起训练,例如模型最大输入长度为512,向量维度为768,在预训练时,就可以初始化一个512x768的位置编码矩阵,随输入一起参与训练,从而学习每个位置对应的向量特征。那么词向量如何获得这些位置信息呢?最简单的做法就是相加。这是因为两者矩阵的维度是相同的。训练式位置编码广泛用于早期Transformer模型,例如BERT、GPT、ALBERT等。但训练式位置编码不具备长度外延能力,因为位置编码矩阵大小是预定的,一旦模型扩展长度,新扩展的部分就缺乏对应的位置信息。
相对位置编码
相对位置编码(Relative Positional Encoding)通过调整Attention矩阵的计算方式来引入位置信息。常见的方法包括:
- XLNet:将绝对位置编码替换为相对位置编码,并引入可训练的向量
- T5:在Attention矩阵中添加一个可训练的偏置项
- DeBERTa:保留了相对位置向量,并在Attention计算中使用
ALiBi注意力线性偏置
ALiBi(Attention with Linear Biases)通过在Attention计算中引入线性偏置,使得模型能够处理更长的序列。它不需要额外的位置编码向量,而是直接在Attention分数中引入偏置。
Sinusoidal位置编码
这是Google在Transformer模型提出的一种绝对位置编码。使用正弦和余弦函数来计算位置向量的分量索引。
PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(100002i/dmodelpos)
由于这样的分量计算方式,每个分量的数值都具有周期性,并且越靠后的分量周期越长,波长越长,频率越低。因此该位置编码具有远程衰减的特点。即:两个相同的词向量,距离越近,内积分数越高,随着相对距离的增加,内积分数震荡衰减。基于这样的特点,所以该编码理论上具备一定长度外延的能力。
RoPE位置编码
RoPE位置编码(Rotary Position Embedding)从名字可以知道处理方式,就是将向量旋转一定角度,为其赋予位置信息。
在训练式位置编码中,模型只能感知每个词向量的绝对位置,无法感知例如两两词向量之间的相对位置。对于Sinusoidal位置编码来说,模型能够一定程度上感知相对位置。
RoPE的设计出发点:通过绝对位置编码方式实现相对位置编码。绝对位置编码函数的参数包括词向量和对应的绝对位置信息,而实现RoPE的设想,就需要计算两个词向量之间的点积时,能够带有相对位置信息。也就是找到一个函数,能够通过两个词向量和相对位置信息计算点积。
为了简化,我们和介绍Embedding的向量一样,先把词向量假设成二维的。RoPE的作者借助复数进行求解,我们直接给出作者的结果,位置编码函数是一个基于常数的正弦余弦旋转矩阵和词向量矩阵相乘。该函数在保留向量模长的同时,进行了常数角度的逆时针旋转。
基于该函数计算两个词向量的相对位置,就使用了不同的旋转弧度,而旋转的时候向量的模长始终不变。这样,通过对向量进行旋转,添加了向量的相对位置信息,也同时保留了绝对位置信息。如同角度的特点,旋转也是具有周期性的。
对于高维向量,其实就是两两一组分别进行旋转。对于提到的常数,当其为1时,随两个词向量距离增加,两者内积呈现震荡但缺乏衰减。当借鉴Sinusoidal位置编码的常数时,可以看到与其类似的远程衰减的性质。该常数不同取值会影响注意力远程衰减的程度。对于该数值性质的研究,与大模型的长度外推息息相关,如NTK-Aware Scaled RoPE、NTK-by-parts、Dynamic NTK等长度外推方法,本质上都是通过改变该数值,从而影响每个位置对应的旋转角度,进而影响模型的位置编码信息,最终达到长度外推的目的。目前大多长度外推工作都是通过放大该数值以提升模型的输入长度,例如Code LLaMA将base设为1000000,LLaMA2 Long设为500000,但更大的数值也将会使得注意力远程衰减的性质变弱,改变模型的注意力分布,导致模型的输出质量下降。
这一点从例如Phi-3-mini-4k和Phi-3-mini-128k的模型性能分数比较也可以看出端倪。尽管两个模型的架构参数一样,经过上下文外扩的128k版本模型性能要稍低于4k版本。
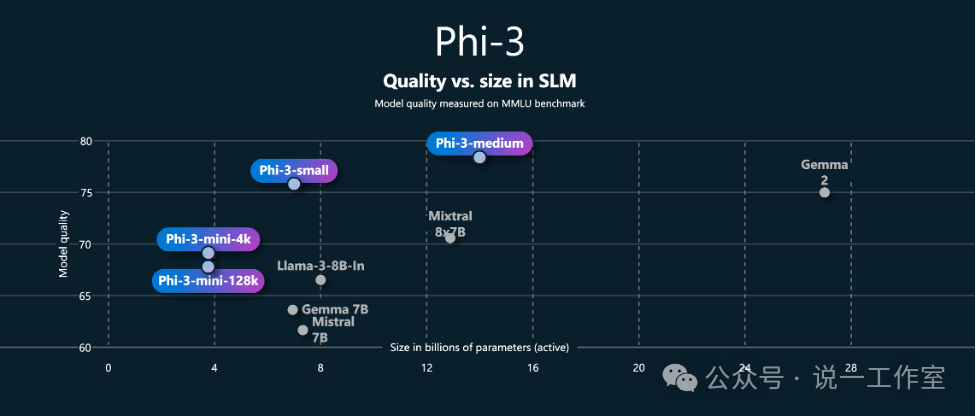
Phi-3代系模型性能与大小比较(注意mini规格不同上下文大小的性能差异)
LongRoPE
终于到Phi模型采用的独特位置编码了,这是外推支持128k上下文的关键。我们紧接着RoPE来介绍Phi长上下文模型使用的LongRoPE技术。
RoPE通过旋转向量的方式引入相对位置信息,在Attention机制中引入了相对位置编码,从而提高了模型处理长文本时的性能。我们也注意到远程衰减的作用,因此RoPE主要用于处理中等长度的文本,通常在几千个token的范围内会有不错的表现,例如原本4k的上下文外推到8k等。
然而,更长的上下文需要更多的模型微调,其成本和难度都会增加。而长文本的支持对于更多的生成式AI的应用,例如Agent的多轮对话不可或缺。最近的研究表明,通过在更长的文本上进行微调,预训练的大模型上下文窗口可以扩展到约128k。但进一步扩展上下文窗口则存在三个主要挑战:首先,未经训练的新位置索引引入了许多异常值,使得微调变得困难。例如,当从 4k tokens 扩展超过1000k时,会引入超过90%的新位置,这就使得现有的微调方法变得难以收敛。其次,微调通常需要相应长度的长文本,但当前训练数据中长文本数量有限。此外,随着上下文窗口的继续扩展,模型的计算量和内存需求将显著增加,带来极其昂贵的微调时间成本和 GPU 资源开销。最后,当扩展到超长的上下文窗口后,由于引入众多新位置信息,大模型的注意力会分散,从而降低了大模型在原始短上下文窗口上的性能。
所以LongRoPE在RoPE的基础上进行了扩展,得以处理超长文本,甚至可以扩展到200万token。其做法是,通过识别和利用位置编码中的非均匀性,LongRoPE在插值过程中最小化了信息损失。
LongRoPE论文中的三个创新关键步骤:
-
通过高效搜索识别并利用了位置插值中的两种非均匀性,为微调提供了更好的初始化,并在非微调情况下实现了8倍扩展
采用的渐进式扩展策略首先在256k长度上进行微调,然后在此基础上对模型进行二次位置插值,进一步扩展到2048k的上下文窗口
在8k的长度上重新调整LongRoPE,以恢复短上下文窗口性能
通过LongRoPE扩展的模型,只需对位置嵌入稍作修改,即可保留原有架构,并可重复使用已有的大部分优化功能,从而避免了直接在超长文本上微调的高昂成本和难度,同时保持在原始短上下文窗口的性能。通过调整RoPE的缩放因子,LongRoPE在不同长度的上下文都能保持较低的困惑度和高准确率。
LongRoPE 首次将预训练的大语言模型(LLMs)的上下文窗口扩展到了2048k(约210万)个 tokens,而其实现仅需在256k的训练长度内进行1k次微调步骤即可,同时仍能保持原始短上下文窗口的性能。在Phi模型家族中,其128k的模型就是通过LongRoPE外推了原有的4k上下文,实现了对长文本的支持。
参考微软研究院文章,“LongRoPE:超越极限,将大模型上下文窗口扩展超过200万tokens[L10]”。
CLIP模型组合
Phi-3和Phi-3.5代系都有支持视觉的多模态模型版本,那么这是如何实现的呢?
我曾经在Phi-3-vision发布的时候,尝试使用llama.cpp来转换模型文件到GGUF格式,由于当时llama.cpp模型转换暂不支持LongRoPE等技术,所以没有成功(奇怪的是,微软自己提供了Phi-3-mini 4k的GGUF模型文件)。但在这个过程中,我对模型的构成有了一些粗浅认识。如果我们看模型文件,其实是由Phi-3-mini,和一个视觉能力模型CLIP组成的。这也是Phi-3/Phi-3.5 vision模型4.2B参数的原因——3.8B文本加上CLIP模型参数。
没能在本地用上多模态的SLM我显然是不死心啊,于是找到了LLaVA系的模型。LLaVA模型比Phi-3-vision开发的更早,没想到的是也有微软研究院的工作参与其中,Phi-3-vision的开发应该也借鉴了LLaVA模型。有意思的是LLaVA家族也整合了一个llava-phi3的模型,并且通过GGUF的文件,支持在Ollama上直接获取和运行,LLaVA内置视觉的也是CLIP模型。
那么什么是CLIP模型呢?CLIP(Contrastive Language-Image Pretraining)模型是由OpenAI在研发GPT模型的同时开发的,旨在通过对比学习来理解图像和文本之间的关系。CLIP同时处理图像和文本数据,通过对比学习来训练模型,使其能够理解和关联这两种不同类型的数据。还记得我们前文说LLM的特性吗?面向表达,图片也是一种表达。CLIP可以用于图像分类、图像搜索、文本生成等多种任务,表现出色。CLIP使用了大量的图像-文本对进行训练,使其在各种任务中具有很强的泛化能力。
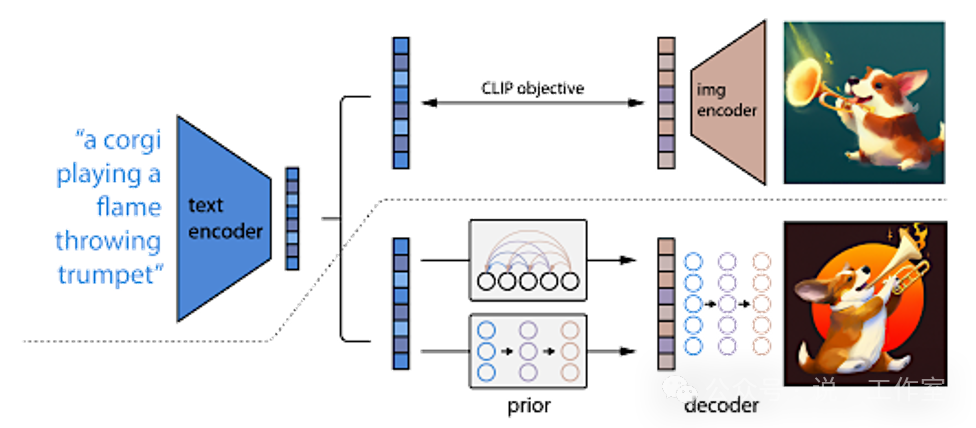
CLIP模型的编码解码示意
LLaVA-LLaMA-3-8B和Phi-3-Vision模型都使用了CLIP-ViT-Large-patch14-336版本的CLIP模型。这个版本的CLIP模型在视觉-语言任务中表现出色,能够有效地将图像和文本信息进行对齐和融合,从而提升模型的多模态处理能力。该模型具有以下特点:
- 架构:使用Vision Transformer(ViT-L/14)作为图像编码器,并使用掩码自注意力Transformer作为文本编码器。
- 对比学习:通过对比损失函数训练,最大化图像和文本对的相似性。
- 零样本性能:在各种计算机视觉任务中表现出色,包括细粒度图像分类、纹理识别和视频动作识别。
- 多模态处理:能够将图像内容与描述图像的文本标签紧密联系起来,适用于图像描述、物体识别等任务。
MoE混合专家
对MoE(Mixture of Experts)[L11]的了解,始于GPT-4新版本发布时,大家对其是否使用混合专家架构降低成本的猜测。其后我们看到Mistral发布了采用MoE的LLM——Mixtral 8x7B模型以及更大的8x22B模型。
混合专家模型(MoE)是一种稀疏模型,内部按照训练一定规律分为若干专家模块,不是所有的模型参数都参与推理。与稠密模型相比,MoE模型预训练速度更快;与具有相同参数数量的模型相比,其仅调用部分专家,具有更快的推理速度;MoE需要大量显存,因为所有专家系统都需要加载到内存中;由于其多专家结构,泛化能力在微调方面存在不少挑战,但近期的研究表明,对混合专家模型进行指令调优具有很大的潜力。
混合专家模型主要由两个关键部分组成:
稀疏MoE层:这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE层包含若干“专家”(例如8个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是MoE层本身,从而形成层级式的MoE结构。
门控网络或路由: 这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家,例如两个专家可以同时工作。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
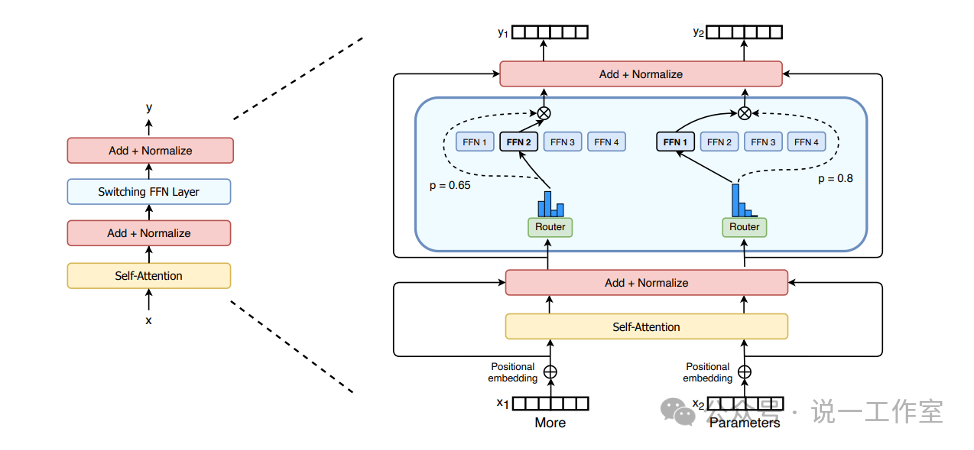
MoE模型的逻辑架构(FFN/专家和路由/门控网络)
我们再回顾Phi-3.5-MoE模型的架构:包含16个Expert具有 16x3.8B参数和2个激活Experts具有6.6B参数。已知Phi-3.5-mini参数是3.8B,整体参数为什么不是16x3.8B=60.8B而是42B呢?激活参数为什么不是2x3.8B=7.6B而是6.6B呢?因为在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的。
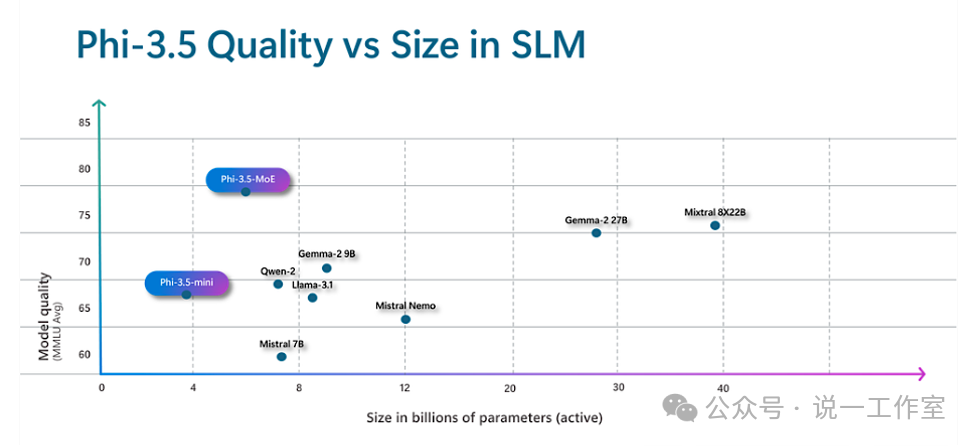
Phi-3.5-MoE模型的优异在于,仅以6.6B的激活参数,其性能就已傲视群雄,甚至高于近40B激活参数的Mixtral 8x22B模型。
在我看来,MoE模型的原理其实和人脑工作机制有着异曲同工之妙,人脑也不是任意时刻所有的神经元都参与到工作中吧。实际上人脑的神经元数量是远大于即使目前像GPT-4这么大规模模型的参数的,GPT-4类的大模型训练和推理需要消耗大量的电力,而人脑,只需要简单的一日三餐。虽然LLM已经比我“聪明”,想到这个我实在是忍不住骄傲了一下。
模型加速技术
DeepSpeed
DeepSpeed是由微软开发的一个开源深度学习优化库,旨在提高大规模模型训练和推理的效率和可扩展性。它通过一系列创新的算法和技术,解决了深度学习训练中的许多挑战。以下是DeepSpeed的主要特点和技术:
并行化策略-支持多种并行化方法,包括数据并行、模型并行和流水线并行。这些方法可以灵活组合,以适应不同规模和复杂度的深度学习模型。
内存优化-引入ZeRO(Zero Redundancy Optimizer)技术,通过将优化器的状态、梯度和参数在分布式环境中进行分割,减少了冗余的内存占用,使得在有限的内存资源下训练更大的模型成为可能。
混合精度训练-支持混合精度训练,即同时使用单精度(FP32)和半精度(FP16)浮点数进行训练。这种方法可以在保持模型性能的同时,减少内存占用和计算时间。
推理优化-Inference模块通过深度融合和新颖的内核调度,充分利用GPU资源,提高每个GPU的效率。它还支持量化后的模型推理,如INT8推理,进一步节省内存和减少延迟。
系统优化-通过优化硬件设备、操作系统和框架,提升大规模模型推理和训练的效率。例如,利用GPU的并行计算能力和优化内存管理机制。
这些技术使得DeepSpeed在处理大规模深度学习模型时,能够显著提高训练和推理的速度和效率。
Flash Attention
Flash Attention
论文:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (DAO等, 2022) http://arxiv.org/abs/2205.14135
特点:通过重新排序注意力计算并利用平铺和重新计算来加速计算和减少显存使用量。相同硬件资源下,可以处理更长的序列或更大的批次。该技术将注意力计算的复杂度从序列长度的平方减少到线性(复杂度从O(N2)降低到O(N),N为序列长度)。
应用:广泛用于大语言模型(如GPT-3、LLaMA等)以加速训练和推理。
Flash Attention 2
论文:FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (DAO, 2023) http://arxiv.org/abs/2307.08691
改进:进一步优化了内存读写和计算速度。优化了线程块和线程间工作分配,减少了不必要的共享内存读写。减少了非矩阵乘法的浮点运算次数,并在单个头部注意力计算实现更高并行。在A100 GPU上理论最大FLOPs/s利用率达到50-73%,接近矩阵乘法的效率。相比第一代,Flash Attention 2在前向传递中实现了约2倍的加速。训练GPT类模型时,每A100 GPU达到225 TFOPs/s的训练速度。
应用:集成到PyTorch 2.0中,并在多个开源框架(如Triton、xformer)中实现。
Flash Attention 3
论文:FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision (SHAH等, 2024) http://arxiv.org/abs/2407.08608
改进:在异步低精度计算利用Tensor Cores和TMA的异步性,通过warp specialization重叠总体计算和数据移动。支持FP8低精度硬件,显著提高了计算效率。在H100 GPU上,使用FP16时比Flash Attention 2快1.5-2倍,最高可达740 TFLOPS;使用FP8时接近1.2 PFLOPS。
顺便提一下,Ollama现在已经可以通过参数启用flash attention,但该功能目前仅在A100/H100等型号GPU上支持。
Phi模型的一点理解
写这篇文着实是花了些时间和精力的,一方面需要整理模型卡,一方面需要查找阅读相应的论文和资料。以下简略地把自己一些看法思考写一写,和大家一起讨论学习,也欢迎批评指教。
1、高质量的语料和训练方法很重要。从开篇的“Textbooks are all you need”开始,教科书质量的语料和多次训练是Phi模型小而强的秘诀。对照人脑,基础教育构筑的基本知识体系和“学而时习之”学习方法是不是对人的智能也同样重要?
2、多语言能力开始提高。早期Phi模型的训练数据以英文为主,加上词表大小有限,中文能力相当有限,不如同期Llama模型。因此我还在各种渠道例如MVP的PGI进行了反馈,希望提升多语言能力。在Phi-3的时候,也看到Phi模型尝试了Llama模型的100k词表,想兼顾开源研究。从Phi-3.5来看,拉齐了32k词表。但多语言能力得到了很大提升,看来是针对性的语料训练,我非常期待中文甚至中文多模(汉字是原生多模态的)的提升。
3、更灵活的上下文长度。可以看到Phi模型大部分的“原生”上下文长度是4k,通过LongRoPE外扩到了128k。这给我们使用SLM带来了更灵活的选择。对我来说,如果用Phi进行简单对话和调度,4k是不错的选择;而更复杂的长文本理解或多轮的agent调度,乃至于图片的理解,128k也提供了足够的长度。
4、多模态能力循序渐进。从Phi-3开始,在SLM里也集成了视觉多模态能力,借助Phi-3文本能力,CLIP模型的能力应该也能够更好的发挥,也为端侧设备上的一些场景,例如OCR、智能眼镜、AI视频通讯、拥有视觉的智能助手等等充满想象力的应用。到了Phi-3.5,开始支持多帧图片,我大胆推测一下,后续可能会有视频甚至空间计算的能力集成进来。(写完后我看到了卢老师利用OpenCV抓取视频帧处理的示例代码哈哈)
5、更多的模型加速和架构技术。从模型卡片能看到,模型加速技术帮助Phi模型训练算力和时间都大幅减少,这意味着更低的成本和更少的能源消耗,也意味着更容易的模型微调。而MoE等架构技术的尝试,能看出在尽力提高模型性能的同时,也努力控制模型参数的大小。如此多的研究和技术探索和实践,让我很期待泛化到其他模型和领域,例如TTS/STT等。
最后,感谢您抽出宝贵时间阅读。这个时代能够保持注意力看一篇这么长的文章实属不易,也希望您喜欢讨论到的内容。我们期待Phi模型有更多更新的进展,也希望还有机会大家一起学习讨论。如果觉得还不错,敬请关注点赞转发,哈哈。
模型详情:
[M1]: https://huggingface.co/microsoft/phi-1
[M2]: https://huggingface.co/microsoft/phi-1.5
[M3]: https://huggingface.co/microsoft/phi-2
[M4]: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
[M5]: https://huggingface.co/microsoft/Phi-3-small-128k-instruct
[M6]: https://huggingface.co/microsoft/Phi-3-medium-128k-instruct
[M7]: https://huggingface.co/microsoft/Phi-3-vision-128k-instruct
[M8]: https://huggingface.co/microsoft/Phi-3.5-mini-instruct
[M9]: https://huggingface.co/microsoft/Phi-3.5-MoE-instruct
[M10]: https://huggingface.co/microsoft/Phi-3.5-vision-instruct
参考链接:
[L1]: https://github.com/microsoft/DirectML
[L2]: https://github.com/microsoft/onnxruntime
[L3]: https://huggingface.co/datasets/bigcode/the-stack
[L4]: https://archive.org/download/stackexchange
[L5]: https://github.com/deepmind/code_contests
[L6]: https://platform.openai.com/docs/models/gpt-3-5
[L7]: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/sample_finetune.py
[L8]: https://github.com/microsoft/Phi-3CookBook/blob/main/md/04.Fine-tuning/FineTuning_Vision.md
[L9]: https://huggingface.co/microsoft/Phi-3.5-moe-instruct/blob/main/added_tokens.json
[L10]: https://www.msra.cn/zh-cn/news/features/longrope
[L11]: https://huggingface.co/blog/zh/moe















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









