







发表时间:Oct 2024
论文链接:https://readpaper.com/pdf-annotate/note?pdfId=2536104770520270336¬eId=2609148347801754368
作者单位:Carnegie Mellon University
Motivation:In recent years roboticists have achieved remarkable progress in solving increasingly general tasks on dexterous robotic hardware by leveraging high capacity Transformer network architectures and generative diffusion models. Unfortunately, combining these two orthogonal(Transformer network architectures and generative diffusion models) improvements has proven surprisingly difficult, since there is no clear and well understood process for making important design choices.
解决方法:In this paper, we identify, study and improve key architectural design decisions for high-capacity diffusion transformer policies.
Our contributions are:
-
Scalable Attention Blocks:我们提出了一个关键改进(受 Peebles 等人的启发。通过在diffusion transformer policy layers中添加自适应层范数(adaLN)块来稳定训练。这个简单的技巧在包含超过 1000 个决策的长范围、灵巧的、真实世界的操作任务上将性能提高了 30%+(牛逼)!RDT中也使用QKNorm & RMSNorm(稳定计算)。
-
Efficient Observation Tokenization: we compare several methods to tokenize multiple camera observations, such as Vision Transformers [15] and ResNet [16] encoders. We find that a relatively simple implementation (ResNet image tokenizer + Transformer policy) can provide a substantial (40%+) performance boost over competing strategies.
-
DiT-Block Policy: We integrate the best performing components in a unified framework, coined DiTBlock Policy.
实现方式:
The observation tokens are passed into a encoder-decoder transformer network (middle), which is responsible for predicting the noise epsilon (ε) used for diffusion.
-
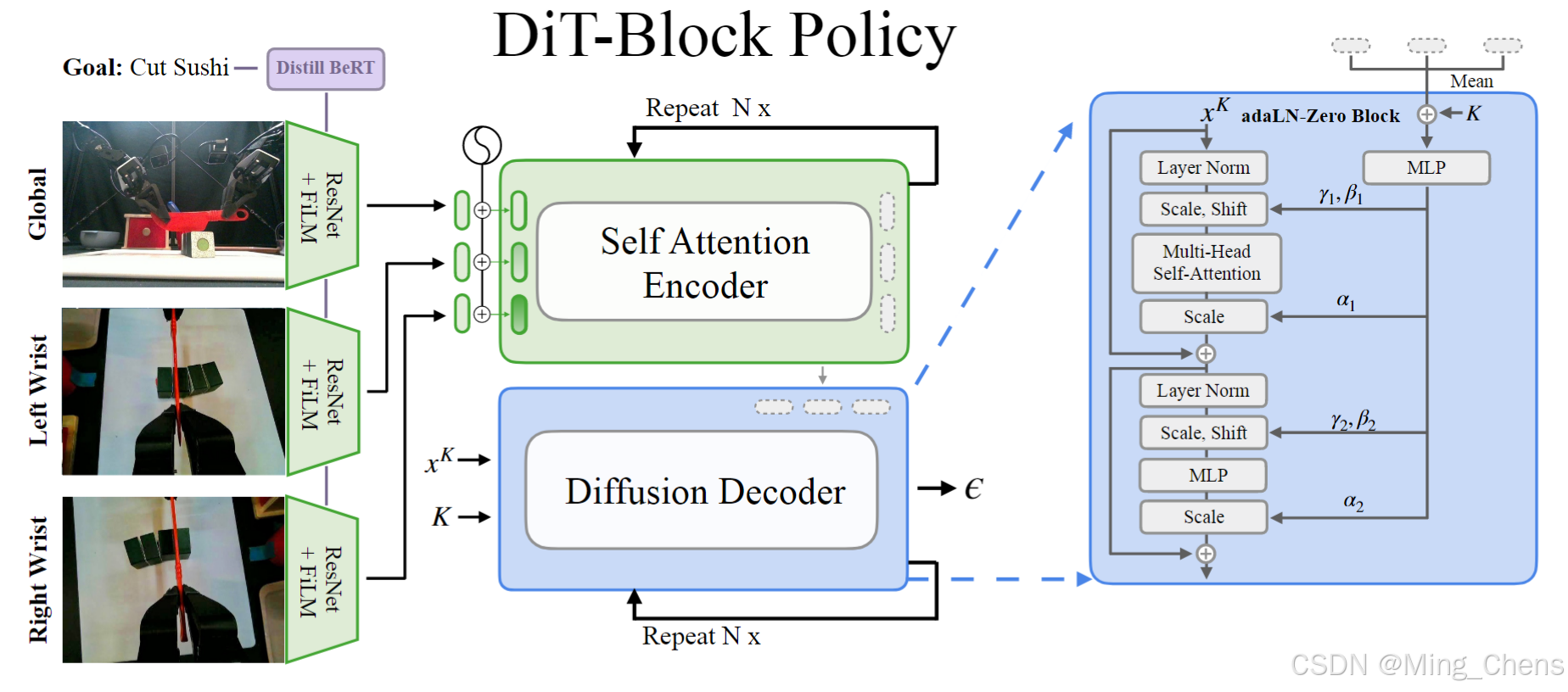 文本用Film融入视觉token。
文本用Film融入视觉token。 -
The observation tokens are passed into an encoder-decoder transformer network (middle), which is responsible for predicting the noise epsilon (ε) used for diffusion.
-
对于稳定的训练,解码器块利用定制的 adaLN-Zero 架构(右),使转换器能够可扩展地优化扩散目标。
实验:我们的第一个任务集考虑了双手动、低成本的 ALOHA 机器人 [8],这使我们能够研究具有高度灵巧、精确行为的挑战性场景。设计了三种任务,由易到难。
最后,请注意 D.P.Transformer 基线无法解决我们的任何任务,因为不稳定的训练会导致嘈杂的/不安全的动作预测。因此,我们得出结论,DiT-Block 策略比基线更稳定地学习扩散策略转换器。
结论:我们希望这项工作将为未来的机器人学习技术打开大门,这些技术利用生成扩散建模的效率和大规模transformer架构的可扩展性。
此外,我们的观察tokenizer的消融表明,使用单独的 ResNet CNN 进行图像编码比单独使用transformers提供更强的性能。即使缩放transformers也不足以弥补这种差异。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











