









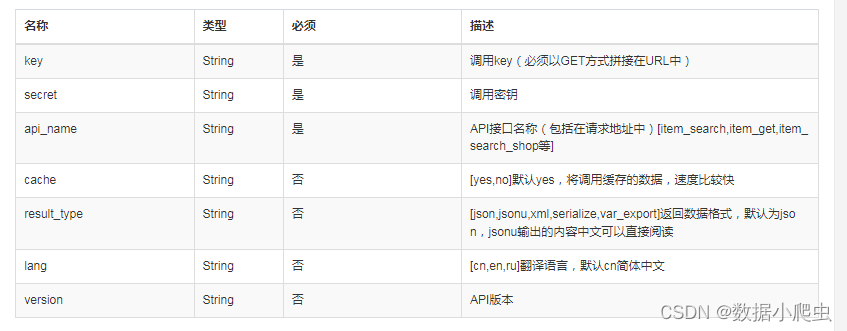
要实现数据中台,一个最基本的要求就是同步交易系统接口数据。实现接口数据同步的方式主要有3种:全量同步、增量同步、流式数据同步,其中流式数据又分为业务流数据和日志流数据。
接口数据同步是数据中台的一项重要工作,是在搭建数据中台的过程中需要投入很多精力完成的。虽然单个表的数据同步任务难度不大,但是我们需要在数据中台实现标准化配置,这样才可以提高工作效率,为后续的数据中台运维和持续扩充接口打下良好的基础。
全量接口同步
一般而言,全量接口同步是数据中台必不可少的功能模块。不管是增量数据同步还是流式数据同步,都是在全量接口同步的基础上进行的。
全量接口同步一般针对T+1的业务进行,选择晚上业务低峰和网络空闲时期,全量抽取交易系统的某些业务数据。一般来说,虽然全量接口同步占用时间长,耗费网络宽带高,但是数据抽取过程简单、准确度高,数据可靠性好,因此比较容易进行平台标准化配置。
根据目前的开源生态,我们主要推荐了两种数据同步工具,一个是Kettle,一个是DolphinScheduler集成的DataX。
1.Kettle
对于Kettle,我们一般按照系统+业务模块来划分Kettle数据抽取任务。
第一步,把对应数据库的JDBC驱动都加入到data-integration\lib目录下,然后重新打开Spoon.bat。
第二步,在新创建的转换里面创建DB连接。
增量接口同步
一般来说,数据仓库的接口都符合二八规律,即20%的表存储了80%的数据,因此这20%的表数据抽取特别耗费时间。此时,对于批处理来说,最好的方法是,对于80%数据量较小的表,采用流水线作业的方式,快速生成接口表、接口程序、接口任务,通过全量接口快速抽取、先清空后插入目标表;针对20%数据量较大的表,则需要精耕细作,确定一个具体可行的增量方案。
我认为一般满足以下条件之一就是较大的表:①抽取时间超过10分钟;②单表记录数超过或者接近100万;③接口数据超过1GB。之所以如此定义,是从数据接口的实际情况出发。第一,抽取时间超过10分钟,会影响整体调度任务的执行时间;第二,单表记录数超过100万,则插入数据占用数据库大量的资源,会影响其他任务的插入,降低系统的并发能力;第三,数据传输超过1GB,则需要耗费大量的网络宽带,每天重复一次会增加网络负担。
对于需要做增量的接口表,主要推荐以下两种批处理方案。
方案一:根据数据创建或者修改时间来实现增量
很多业务系统一般都会在表结构上增加创建和修改时间字段,并且存在主键或者唯一键(可以是一个字段,也可以是多个字段组合),同时确保数据不会被物理删除,这种表适合方案一。实际情况是,各大OLTP系统的数据库都可以满足记录创建和修改时间信息的,因此这种方式应用最广泛。
对于创建或者修改时间,MySQL数据库可以在建表时指定字段默认值的方式来生成。















 4820
4820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









