







喧闹任其喧闹,自由我自为之。我自风情万种,与世无争。
别人对你的打分,是他对你的看法他不了解你的时候,你又何必在乎她的打分呢!你给自己打几分?
上一节,我们搭建了项目,并且完成了项目搭建,【Vue + Koa 前后端分离项目实战】使用开源框架==>快速搭建后台管理系统 -- part1 项目搭建_小白Rachel的博客-CSDN博客
这节我们从后端入手,开始项目代码学习。从后端入手,完成【新增期刊】功能
项目最终实现效果:qinchenju.com/island
本节实现效果速览:
目录
一、准备工作
使用IDE工具打开后端代码lin-cms-koa
koa 是一个优美的微框架,【林间有风】团队自己整理出了开发规范。
1.功能开发的顺序?
先开发后端接口--->再写前端代码-->前后端联调
2.代码写在哪里?
项目文档地址:项目结构及开发规范 | Lin CMS
(1)项目目录结构

(2)代码规范
- 在
app/api文件夹中开发 API,并将不同版本,不同类型的 API 分开,如:v1 代表 第一版本的 API,v2 代表第二版本,cms 代表属于 cms 的 API。 - 将程序的配置文件放在
app/config文件夹下,并着重区分secure(安全性配置)和setting(普通性配置)。配置更详细内容参考配置 - 将可重用的类库放在
app/lib文件夹下。 - 将数据模型放在
app/model文件夹下。 - 将开发的插件放在
app/plugin文件夹下。 - 将校验类放在
app/validator文件夹下。
(3)数据库模型规范
koa 本身并非对数据库做出支持,Lin 通过集成sequelize这个 orm 库来进行数据访问, 如果你不熟悉,请先阅读官方文档
中文文档: GitHub - demopark/sequelize-docs-Zh-CN at v5
二、接口开发初体验
1.测试接口编写
在app-->api-->v1目录下新建 content.js文件
(1)实例化接口对象
说明:LinRouter()这个类是对KoaRouter的封装,让他的功能更加强大,同时兼容KoaRouter的所有操作
(2)配置路由前缀
(3)定义方法并返回测试数据
// 文件 app/api/v1/content.js
import { LinRouter } from 'lin-mizar'
const contentApi = new LinRouter({
prefix: '/v1/content' // 配置路由前缀
})
// 定义方法
contentApi.post('/', async ctx => {
const test = {
res: true
}
return ctx.json(test) // 返回测试信息
})
module.exports = { contentApi } // 导出2.使用postman工具测试接口
使用node index.js启动项目
由于前端项目还没有实现,之能通过接口测试工具,如postman进行测试
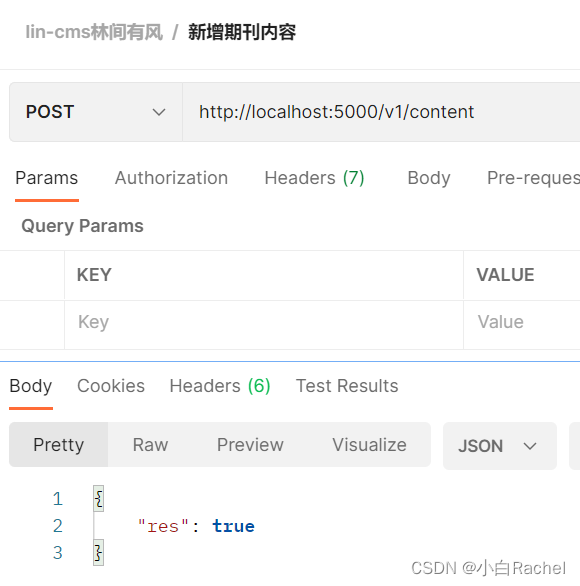
可以看到输入信息,证明接口现在已经跑通了。
三、【正式开始】接口实现业务逻辑
一般写新增接口的业务逻辑:
- 参数校验
- 执行业务逻辑
- 插入数据库
- 返回成功
1.参数校验--校验器
lin-cms已经内置了参数校验的类库
按照目录规范: 在app-->validators 新建 content.js 保持同名
声明 AddContentValidator()类,继承了LinValidator()验证器基类
lin-cms是基于validator.js库实现的。因此validator.js中的原生校验也可以在此使用。
// 文件 app/validator/content.js
import { config, LinValidator } from 'lin-mizar'
import { Rule } from 'lin-mizar/lin'
class AddContentValidator extends LinValidator {
constructor () {
super();
this.image = [
new Rule('isNotEmpty', '内容封面不能为空')
]
this.type = [
new Rule('isNotEmpty', '内容类型不能为空'),
new Rule('isInt', '内容类型id必须是数字')
]
this.title = [
new Rule('isNotEmpty', '内容标题不能为空')
]
this.content = [
new Rule('isNotEmpty', '内容介绍不能为空')
]
this.url = [
new Rule('isOptional'),
new Rule('isURL', '内容外链必须是合法url地址')
]
this.pubdata = [
new Rule('isNotEmpty', '发布不能为空'),
new Rule('isISO8601', '发布日期格式不正确')
]
this.status = [
new Rule('isNotEmpty', '内容有效状态未指定'),
new Rule('isInt', '内容有效状态标识不正确')
]
}
}
export { AddContentValidator }在content中添加如下,进行测试。
// app/api/v1/content.js
// 1.参数校验
const v = await new AddContentValidator().validate(ctx)
return ctx.json(v)修改完成之后,重启框架。到postman测试
由于没有传参 因此所有的校验都报错。传入一些信息之后,可以校验。


如果想要获取到返回数据,只需要 修改 return ctx.json(v.get('body')) 重启框架,输入正确的信息,可以看到数据已经全部返回。
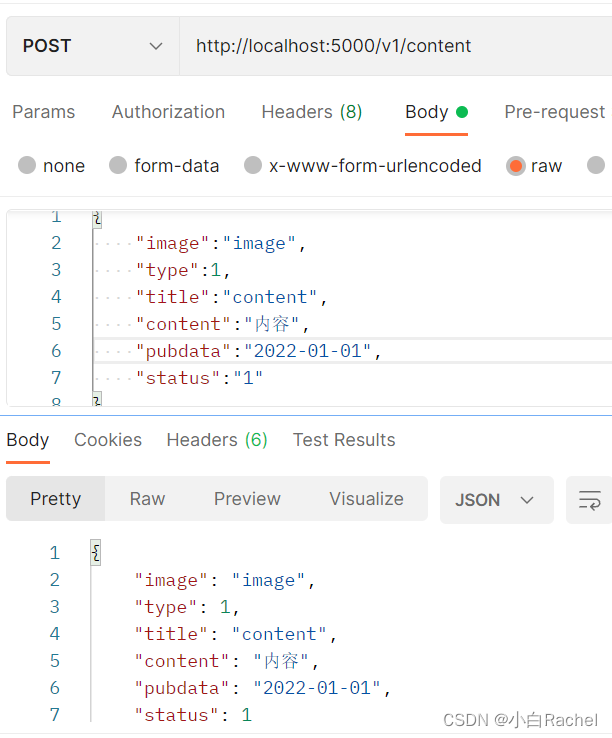
2.执行业务逻辑
由于movie music sentence三者主要字段相同,但是music多了一个url字段
因此,每次添加之前,需要判断数据是三者之中的哪一类,然后再插入数据库中。
(1)新增服务层Service文件
在app目录下新建service文件,表示服务层文件。并添加centent.js文件。
在类中定义添加期刊的方法addContent,其参数是前端传入的表单。
在switch中判断type字段(100-电影 200-音乐 300-句子)插入到表中
import { MovieDao } from '../dao/movie';
import { MusicDao } from '../dao/music';
import { SentenceDao } from '../dao/sentence';
import { NotFound } from 'lin-mizar';
class Content {
static async addContent (v) {
// 根据不同种类判断数据
switch (v['type']) {
case 100:
// 电影
// delete v['url']
// await MovieDao.addMovice(v);
break;
case 200:
// 音乐
/// await MusicDao.addMusic(v);
break;
case 300:
// 句子
// delete v['url']
// await SentenceDao.addSentence(v);
break;
default:
throw new NotFound({ msg: '内容类型不存在' });
}
}
}
export { Content as ContentService };问题来了:如何插入数据到数据库中?
回答:数据库模型orm库
(2)新建模型层Model文件
在app-->model中新增三个模型文件movie.js music.js sentence.js
每一个模型对应一张表。
import { Sequelize, Model } from 'sequelize';
import sequelize from '../libs/db';
import { config } from 'lin-mizar';
class Movie extends Model {
}
Movie.init (
{
id: {
type: Sequelize.INTEGER,
primaryKey: true,
autoIncrement: true
},
image: {
type: Sequelize.STRING(64)
},
content: {
type: Sequelize.STRING(300),
allowNull: true
},
pubdate: {
type: Sequelize.INTEGER,
allowNull: true
},
fav_nums: {
type: Sequelize.INTEGER,
defaultValue: 0
},
title: {
type: Sequelize.STRING(50)
},
type: {
type: Sequelize.INTEGER
},
status: {
type: Sequelize.INTEGER
}
},
{
// 定义表名
tableName: 'movie',
// 定义模型名
modelName: 'movie',
// 删除
paranoid: true,
// 自动写入时间
timestamps: true,
// 重命名时间字段
createdAt: 'created_at',
updatedAt: 'updated_at',
deletedAt: 'deleted_at',
sequelize
}
)
export { Movie as MovieModel }定义了一个类,继承Model基类 。并配置属性,是关系的映射。
(3)新增Dao层文件
在Dao文件夹下新建三个js文件 movie.js music.js sentence.js 分别对应三个模型
思路:在Dao层中调用模型层
import { MovieModel } from '../models/movie';
// 在Dao层中调用模型层
class Movie {
static async addMovice (v) {
return await MovieModel.create(v)
}
}
export { Movie as MovieDao }(4)完整实现Service逻辑
在service层中,可以调用Dao层数据
service层中的content.js 完成整个添加逻辑
由于电影和句子没有url字段,因此去掉即可
import { MovieDao } from '../dao/movie';
import { MusicDao } from '../dao/music';
import { SentenceDao } from '../dao/sentence';
import { NotFound } from 'lin-mizar';
class Content {
static async addContent (v) {
// 根据不同种类判断数据
switch (v['type']) {
case 100:
// 电影
delete v['url']
await MovieDao.addMovice(v);
break;
case 200:
// 音乐
await MusicDao.addMusic(v);
break;
case 300:
// 句子
delete v['url']
await SentenceDao.addSentence(v);
break;
default:
throw new NotFound({ msg: '内容类型不存在' });
}
}
}
export { Content as ContentService };3.完整实现api逻辑
回到api文件中,完善content.js
contentApi.post('/', async ctx => {
// 1.参数校验
const v = await new AddContentValidator().validate(ctx)
// return ctx.json(v.get('body'))
// 2.执行业务逻辑
// 3.插入数据库-封装在service层
await ContentService.addContent(v.get('body'))
// 4.返回成功
ctx.success({
msg: '期刊内容新增成功'
})
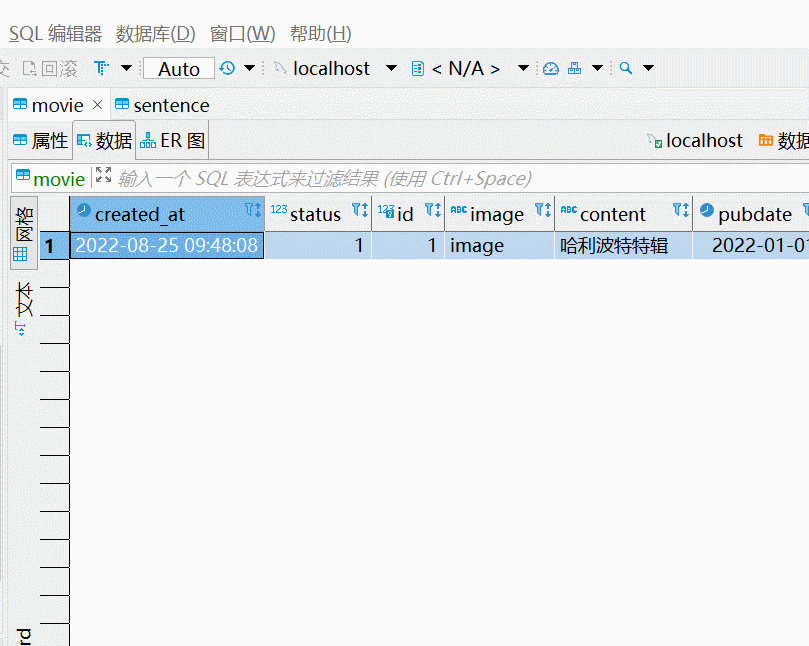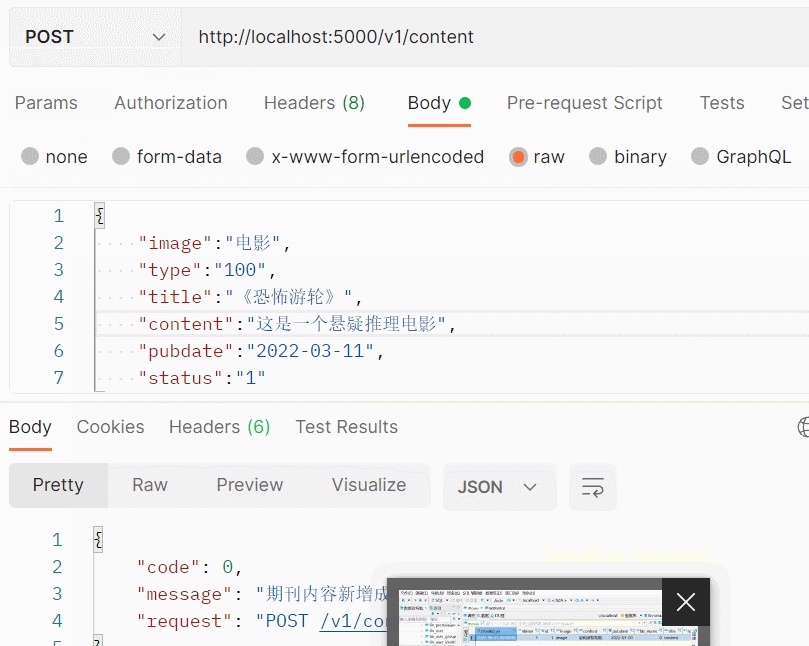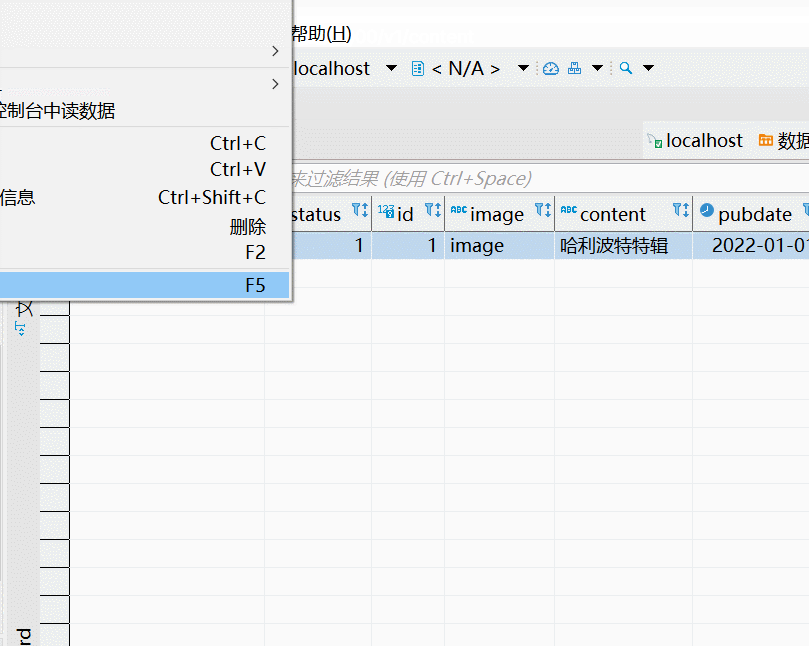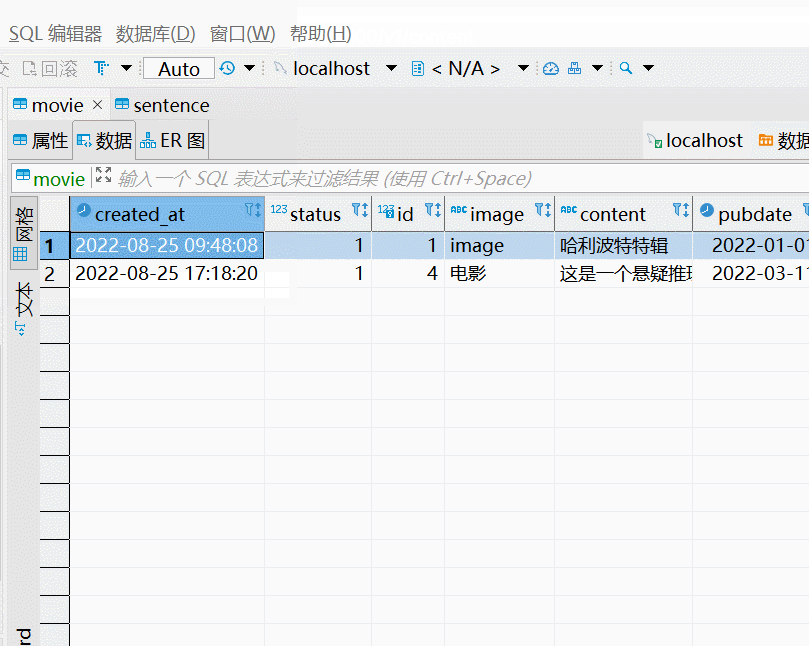
})在postman中,模拟数据调用,调用完成之后,直接查看数据库,即可看到新增数据。切换类型,可以测试其他类型的数据新增情况。
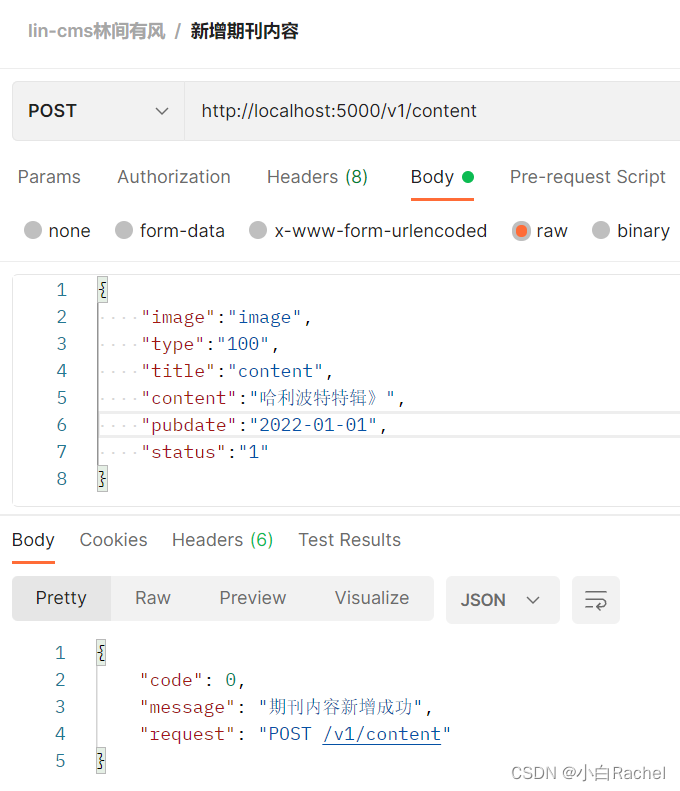
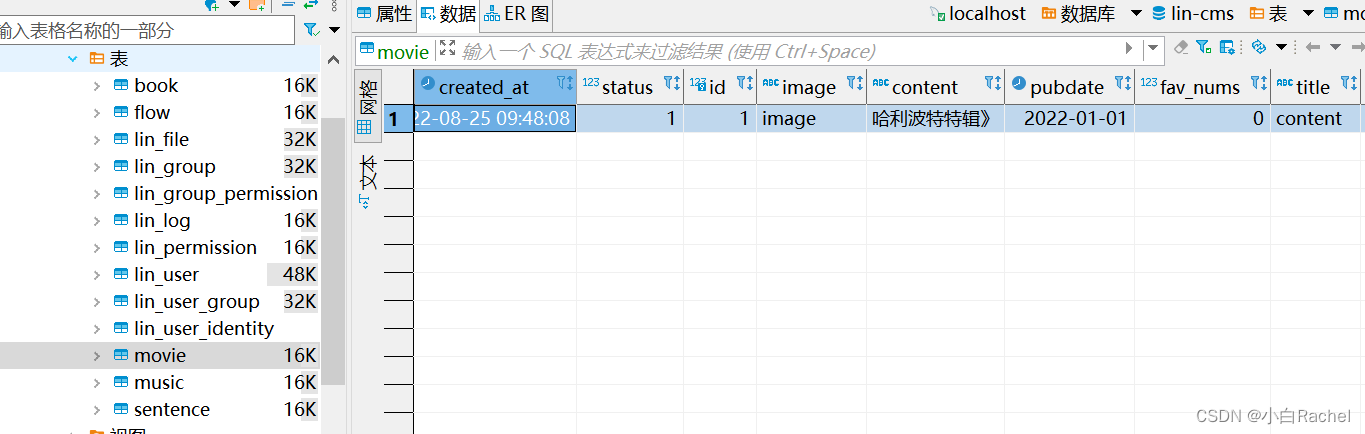
至此,我们本节完成了一次新增方法的后端逻辑

问题:每次查看都需要在数据库中查阅数据新增情况,有些麻烦。
因此下一节,我们将 实现 【期刊列表查询】功能















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











