







http://blog.csdn.net/xiazdong/article/details/8462393
算法
是指解题方案准确而完整的描述,是一系列解决问题的清洗的指令, 算法代表着用系统的方法描述解决问题的策略机制. 也就是说, 能够对一定规范的输入, 在有限时间内获得所求的输出.
程序=算法+数据结构
算法的可行性与空前复杂度, 时间复杂度
大数据下,牺牲精度换取速度.
数据结构
- 是一种存储和组织数据的方式, 意在便于访问和修改
- 指针和链表
- 队列,堆栈,树,散列表
排序
插入排序
将每个元素循环地与前面的元素相比较, 若小于前面的便交换.
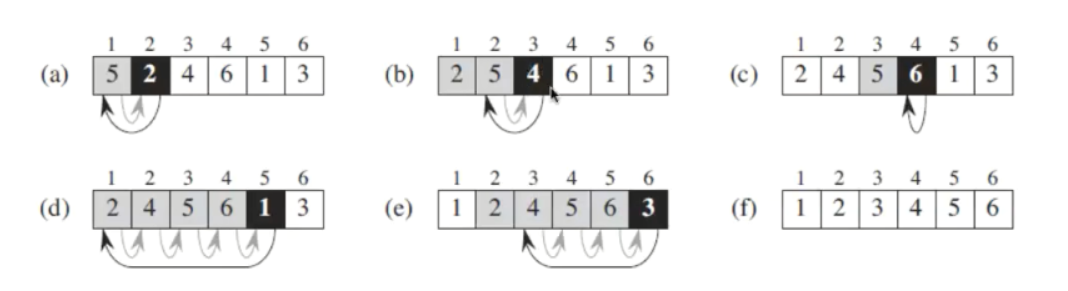
伪代码

时间复杂度为 O(n2)
InSert <- function(a){
for ( i in 2:length(a)){
key <- a[i]
j <- i - 1
while (j >=1 && a[j] > key){
a[j+1] <- a[j]
j = j-1
}
a[j+1] <- key
}
a
}
InSert(c(3,2,1,4))
递归版(有错误未解决,返回不出排序后的数组)
Recursive_InertionSort<- function(A,p,q){
if (p < q){
Recursive_InertionSort(A,p,q-1)
Insert(A, p, q-1)
}
A
}
Insert<- function(A,p,q){
k = A[q+1]
j = q
while (j >= p && A[j] < k){
A[j+1] = A[j]
j = j - 1
}
A[j+1] = k
}
Recursive_InertionSort(c(2,3,4,1),1,4)P与NP
P问题的时间复杂度是多显示时间的
Np问题: 是能被一个多项式时间算法验证的语言类
类P问题有一些可以快速解决的问题组成, 而类NP则由一些可以快速验证其解得问题组成.
线性规划问题的单纯型法和多项式时间复杂度的椭球法, 但线性规划问题不是严格的NP
分治
归并排序例子
冒泡排序
Bubble_sort <- function(A){
len <- length(A)
for (i in 1:(len-1)){
for (j in len:(i+1)){
if (A[j-1] > A[j]){
swap <- A[j]
A[j] <- A[j-1]
A[j-1] <- swap
}
}
}
A
}
> Bubble_sort(c(2,3,4,1))
[1] 1 2 3 4改进的冒泡
每次进入之前判断内层排序是否swap过,即有未排序好的值。若内层都拍好序了就直接得到结果。
improved_Bubble_sort <- function(A){
len <- length(A)
for (i in 1:(len-1)){
if (flag==0) return
flag <- 0
for (j in len:(i+1)){
if (A[j-1] > A[j]){
swap <- A[j]
A[j] <- A[j-1]
A[j-1] <- swap
flag <- 1
}
}
}
A
}递归的冒泡

冒泡排序和插入排序哪个更快“呢?
一般的人回答:“差不多吧,因为渐近时间都是O(n^2)”。
但是事实上不是这样的,插入排序的速度直接是逆序对的个数,而冒泡排序中执行“交换“的次数是逆序对的个数,因此冒泡排序执行的时间至少是逆序对的个数,因此插入排序的执行时间至少比冒泡排序快。选择排序
selection_sort <- function(A){
len <- length(A)
for (i in 1 : (len-1)){
min = i
for (j in (i+1):len){
if(A[min] > A[j])
min <- j
}
tmp <- A[i]
A[i] <- A[min]
A[min] <- tmp
}
A
}
selection_sort(c(3,2,4,5))
归并排序
快速排序
http://blog.csdn.net/morewindows/article/details/6684558
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。














 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









