










房价的数据预处理之探索性数据分析
任务简介:
数据的读取与显示、查看数据的缺失情况、查看数据的类型情况、查看特征之间的相关性。
打卡详情:
读取train.csv文件并且显示后五行,自行查阅pandas中的两种数据结构分别是什么?并做出总结(文字)。Pandas的可视化函数有哪些?(文字),person系数为什么可以用来衡量数据之间的相关性?(图文并茂的提交),如何利用pandas来显示数据信息(代码运行截图)
一、何为数据清洗?
数据清洗主要在于为我们后续对数据处理的过程提供正确有保证的数据。
二、数据清洗的难点
之所以在数据清洗中存在一定的难点,是在于我们的数据是来自于真实的世界,纷繁复杂的数据是不可能保持一致性的。
三、数据清洗的方法
四、数据清洗的八大场景
五、数据处理
脏数据经过清洗之后就要对其进行处理,应为清洗过后的数据依然不能保证它能够满足我们当下的需求或者是当下我们没有能力去处理手上的数据,因此我们要对手上的数据进行处理。
六、数据处理方法
七、总结及打卡作业
读取train.csv文件并且显示后五行,自行查阅pandas中的两种数据结构分别是什么?并做出总结(文字)。Pandas的可视化函数有哪些?(文字),person系数为什么可以用来衡量数据之间的相关性?(图文并茂的提交),如何利用pandas来显示数据信息(代码运行截图)
(1)总而言之,当我们从拿到数据开始到开始从数据中提取特征之间,我们要对数据进行处理以使得数据能够完整一致,比较合理的能够被我们处理。
(2)
type(train_set) ==> pandas.core.frame.DataFrame
DataFrame.tail(n) ==> 返回最后n行数据
在pandas中的两种数据结构,一种是Series,一种是Dataframe。
Series表示一维数据,可以简单理解为一个向量,但是不同于向量的是,Series会自动为这一维数据创建行索引。
Dataframe表示一种二维表格型的数据结构,既有行索引index,也有列索引columns。其实可以简单把Dataframe理解为一张数据表。
(3)Pandas中可视化函数有:
折线图:obj.plot()
柱形图:
垂直柱形图:obj.plot.bar()
水平条形图:obj.plot.barh()直方图和概率密度分布图:
直方图:obj.hist()
概率密度分布图:obj.plot(kind=‘kde’)散点图:
plt.scatter()
(4)Pearson相关系数 (Pearson CorrelationCoefficient)是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。描述了两组线性的数据一同变化移动的趋势。
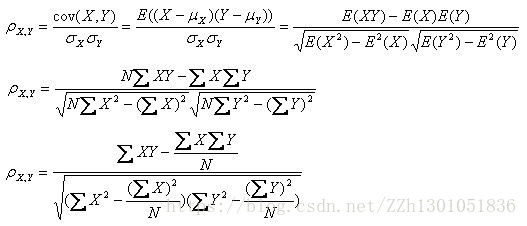
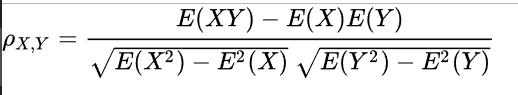
当两个变量的标准差都不为零,相关系数才有定义。从柯西-施瓦茨不等式可知,相关系数的绝对值不超过1。当两个变量的线性关系增强时,相关系数趋于1或-1。当一个变量增加而另一变量也增加时,相关系数大于0。当一个变量的增加而另一变量减少时,相关系数小于0。当两个变量独立时,相关系数为0,但反之并不成立。这是因为相关系数仅仅反映了两个变量之间是否线性相关。比如说,X是区间[-1,1]上的一个均匀分布的随机变量。Y = X2.那么Y是完全由X确定。因此Y和X不独立,但相关系数为0。或者说他们是不相关的。当Y和X服从联合正态分布时,其相互独立和不相关是等价的。
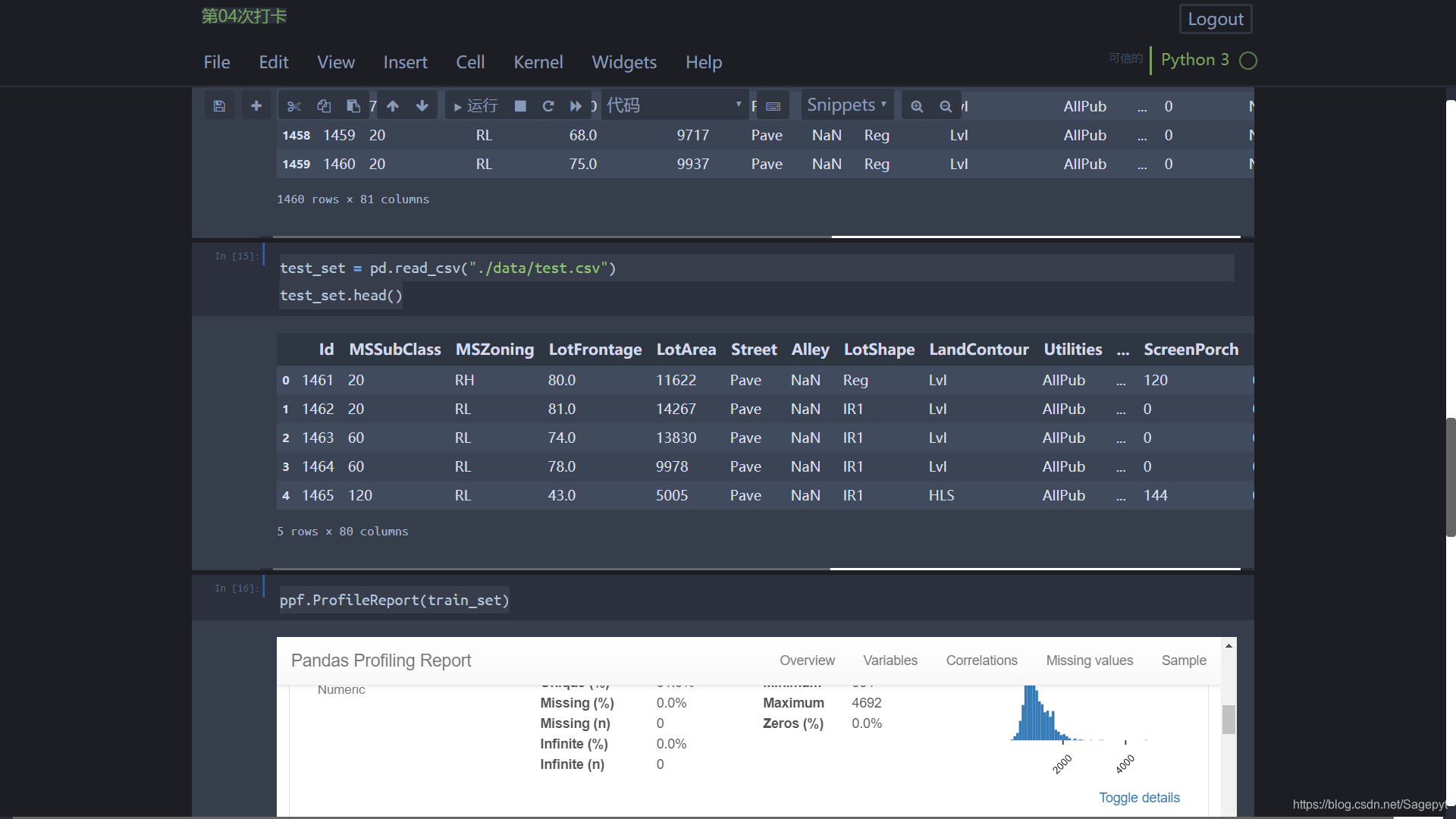
(5)显示数据信息可以用Dataframe自带的函数,比如dataframe.head();要想获得数据的更加详细的相关信息可以使用pandas_profiling包来显示。
import pandas as pd
import pandas_profiling as ppf
train_set = pd.read_csv("./data/train.csv")
train_set.head(train_set.size)
test_set = pd.read_csv("./data/test.csv")
test_set.head()
ppf.ProfileReport(train_set)
ppf.ProfileReport(test_set)















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









