







瑞吉外卖知识总结
学习知识统计:
项目启动类
有许多功能的实现必须要在项目启动类上添加注解,比如本项目所需要的事务管理, 缓存管理, 拦截器管理等功能,所有项目启动类也是一个非常重要的知识。
@Slf4j
@SpringBootApplication
@ServletComponentScan //拦截器需要的
@EnableTransactionManagement //开启事务管理
@EnableCaching //开启缓存管理
public class ReggieApplication {
public static void main(String[] args) {
SpringApplication.run(ReggieApplication.class,args);
log.info("项目启动成功");
}
}
依赖管理
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.0.33</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
</dependencies>
相关配置文件学习
服务器端口设置
server:
port: 9000
数据库和redis相关设置
-
name: 设置项目启动名称。
-
datasource: 设置数据库连接设置。
-
redis: 设置redis连接设置。
其中database是选择连接redis连接的第几个数据库,默认的有16个(0-15下标)。
-
cache: 设置了缓存(redis)有效时间
spring:
application:
name: reggie_take_out
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/reggie?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 1739538774.mcj
redis:
host: localhost
port: 6379
database: 0
cache:
redis:
time-to-live: 1800000
mybatis-plus框架相关设置
-
log-impl: 设置了输出日志为:StdOutImpl
-
map-underscore-to-camel-case: 开启将下划线改为驼峰命名法。
主要目的:数据库相关字段采取下划线命名,Java实体类采取的是驼峰命名,为了将数据库字段和属性名产生对应,mybatis-plus框架可自动开启转换帮助实现对应。
-
id - type: 设置数据库id的生成策略,这里采取的是雪花算法。
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
global-config:
db-config:
id-type: assign_id
自定义配置类
定义了图片上传和保存的地址,方便统一设置,读取和修改。
reggie:
path: D:/image/
读取方式:
采取 ${等级全路径} 方式可以读取配置文件中的相关信息。
@Value("${reggie.path}")
private String path;
config包-配置类相关知识学习
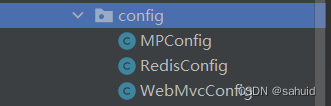
WebMvcConfig ==> 是设置关于SpringMvc相关的配置
MPConfig ==> 是设置关于mybatis-plus相关的的配置 (具体作用到后续相关内容中讲到)
RedisConfig ==> 是设置关于redis相关的配置 (具体内容到后续相关内容中讲到)
解决的问题
如何实现静态资源映射?
在前后端不分离的项目中,idea既保存了前端代码又保存了后端代码。这时我们要想实现我们对静态网页的访问就需要进行对静态资源的映射。
实现方法:(在前后端分离的项目中并不需要如此)
- 继承WebMvcConfigurationSupport类,重写addResourceHandlers,使用addResourceHandle方法(添加访问路径)和addResourceLocations方法(添加的是映射后的真实路径,映射的真实路径末尾必须加 /)。
@Configuration
@Slf4j
public class WebMvcConfig extends WebMvcConfigurationSupport {
/**
* 设置静态资源映射*
* @param registry
*/
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/**").addResourceLocations("classpath:/static/");
}
前端id不准确该怎么做?
在雪花算法中生成的id过长,在进行前端数据传输时,由于js对long类型的处理会损失精度最后id传输时不准确无法完成相关功能。
解决方法:
- 将后端雪花算法生成的long类型id转化为string类型传给前端,前端直接进行json的类型转换保证数据的准确性。
实现方法:
-
提供对象转换器JacksonObjectMapper,基于Jackson进行Java对象到json数据的转换
-
拓展mvc框架的消息转换器 (不需要背,复制即可)
/** * 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象 * 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象] * 从Java对象生成JSON的过程称为 [序列化Java对象到JSON] */ public class JacksonObjectMapper extends ObjectMapper { public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd"; public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss"; public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss"; public JacksonObjectMapper() { super(); //收到未知属性时不报异常 this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false); //反序列化时,属性不存在的兼容处理 this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES); SimpleModule simpleModule = new SimpleModule() .addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT))) .addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT))) .addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT))) .addSerializer(BigInteger.class, ToStringSerializer.instance) .addSerializer(Long.class, ToStringSerializer.instance) .addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT))) .addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT))) .addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT))); //注册功能模块 例如,可以添加自定义序列化器和反序列化器 this.registerModule(simpleModule); } }
@Configuration
@Slf4j
public class WebMvcConfig extends WebMvcConfigurationSupport {
/**
* 拓展mvc框架的消息转换器*
* @param converters
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
//创建消息转换器对象
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
//设置对象转换器, 底层使用Jackson将Java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
//将上面的消息转换器对象追加到mvc框架的转换器集合中
converters.add(0,messageConverter);
}
}
common包 - 公共处理的类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ovUCtWH4-1693122824970)(C:\Users\Lenovo\AppData\Roaming\Typora\typora-user-images\image-20230826152743578.png)]
BaseContext ==> 是通过ThreadLocal全局使用获取id
CustomException ==> 自定义异常类
GlobalExceptionHandler ==> 全局异常处理器
JacksonObjectMapper ==> 对象转换器(解决传递前端id不准确与config类一起使用)
MyMetaObjectHandler ==> 实体类数据自动填充
R ==> 封装的集体返回类
解决的问题
如果全局获取到存储的id
在之前所学的Java web中我们学习过一个思路,就是把要存是的id放到session中然后再通过session进行获取。但是这种方法只局限于 controller层,能够对浏览器进行操作的地方。而想要全局不仅仅只局限于controller层获取所存的id,我们就不能通过session这种方法。
实现方法:
-
我们需要通过ThreadLocal(本地线程变量)进行实现。我们只需要把这个类的创建和get,set方法封装成一个类(BaseContext)就可以通过外部调用set和get方法进行存储和调用所存的id信息。
原理:
在我们整个项目中,从一开始的项目启动的登录到拦截器进行拦截访问和后期的controller调用都是一个相同的线程。而ThreadLocal就可以在一个相同的线程中实现数据的存储和调用是与其他线程完全隔离的,所以我们在一个相同的线程中就可以实现id数据的全局调用。
解决方法:
/**
* 基于ThreadLocal封装的工具类 , 用户保存和获取当前用户的id*
*/
public class BaseContext {
private static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void set(Long id){
threadLocal.set(id);
}
public static Long get(){
return threadLocal.get();
}
}
具体使用:
//把用户的id 基于ThreadLocal 保存起来 方便后期获取
//存储时直接调用set把数据放入即可
BaseContext.set(empId);
// 设置 创建和修改人的自动填充
// 获取时直接get就可以获取
metaObject.setValue("createUser", BaseContext.get());
metaObject.setValue("updateUser", BaseContext.get());
自定义业务异常
在做项目中java里的异常可能无法满足需求,我们需要根据自己的实际情况进行自定义异常。
实现方法:
- 只需要一个类继承RuntimeException,然后写上几个满足我们需求的构造方法。
解决方法:
/**
* 自定义业务异常*
*/
public class CustomException extends RuntimeException{
public CustomException(String message){
super(message);
}
}
全局异常处理器
当项目中任何地方遇到异常时,我们往往希望将这些异常进行统一的处理返回,而不是直接报错或者使项目直接停止,这是我们就需要一个全局异常处理器。同时我们可以实现记录日志等功能方法后期解决bug等问题。
实现方法:
- 我们需要在类上添加一个@ControllerAdvice注解,同时在后面写上我们这个类需要集体处理的异常有哪些。
例如:
@ControllerAdvice(annotations = {RestController.class, Controller.class})
- 如果我们返回的类型需要转换成json类型叫给前端处理时,我们需要添加一个@ResponseBody注解
- 我们需要写处理各个异常的方法,并书写其中的逻辑,方法的参数就是项目报错的异常。
- 同时在这个方法上需要添加一个@ExceptionHandler注解并且后面需要标注这个方法要解决的是哪个或多个异常。
例如:
@ExceptionHandler({SQLIntegrityConstraintViolationException.class})
原理:
- 全局异常处理器是基于spring aop切面处理的知识。就是在执行一个任务或者方法前后我们可以给他添加一些我们需要的额外逻辑,并且不会直接修改源码。
解决方法:
@ControllerAdvice(annotations = {RestController.class, Controller.class})
@ResponseBody
@Slf4j
public class GlobalExceptionHandler {
@ExceptionHandler({SQLIntegrityConstraintViolationException.class})
public R<String> Exception(SQLIntegrityConstraintViolationException ex){
// 判断错误原因根据错误信息
if(ex.getMessage().contains("Duplicate entry")){
String[] sp = ex.getMessage().split(" ");
String result = sp[2];
return R.error(result + "已存在");
}
return R.error("未知错误");
}
/**
* 自定义业务异常*
* @param ex
* @return
*/
@ExceptionHandler(CustomException.class)
public R<String> Exception(CustomException ex){
return R.error(ex.getMessage());
}
}
自动填充字段设置
项目实体类中有个别字段我们会一直使用一种相同的逻辑进行处理,比如updateTime,createTime都是一直使用获取当前时间进行设置数值,这时如果每次操作我们都需要进行书写一边,这会增加许多无效的操作。这时我们就可以使用自动填充,在每次对数据更改创建时都可以自动填充这些数据。
实现方法:
- 在相关属性字段中添加@TableField注解表明这是自动填充字段,同时我们需要在后面标注这是在什么时期进行自动填充(添加 / 修改 / 两者都有)。
例如:
//添加时自动填充
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
//添加修改时都自动填充
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
- 在创建一个类进行自动填充设置,需要实现MetaObjectHandler接口。并且重写相关方法,进行逻辑实现。
解决方法:
需要添加@Component 加入spring bean管理
/**
* 自动填充字段的设置*
*/
@Component
@Slf4j
public class MyMetaObjectHandler implements MetaObjectHandler {
/**
* 插入操作的自动填充*
* @param metaObject
*/
@Override
public void insertFill(MetaObject metaObject) {
// 设置 创建和修改时间的自动填充
metaObject.setValue("createTime", LocalDateTime.now());
metaObject.setValue("updateTime", LocalDateTime.now());
// 设置 创建和修改人的自动填充
metaObject.setValue("createUser", BaseContext.get());
metaObject.setValue("updateUser", BaseContext.get());
}
/**
* 修改操作的自动填充*
* @param metaObject
*/
@Override
public void updateFill(MetaObject metaObject) {
metaObject.setValue("updateTime", LocalDateTime.now());
metaObject.setValue("updateUser", BaseContext.get());
}
}
集体返回类
在我们完成一个接口时我们需要向前端返回处理结果,让前端知道是成功还是失败,如果我们每个方法都返回不一样的类型,那么前端处理起来会非常麻烦,需要对每种情况都进行判断。
实现方法:
- 封装一个集体返回类,进行数据返回。
- 基础属性有 data - 数据 , code - 状态码 , message - 详细信息。
解决方法:
- 数据不强制任何类型,使用泛型方法接受任何数据,同时写success, error静态方法方便使用时不用一直new R对象可以直接调用这两个经常用的方法。
/**
* 通用的返回结果, 服务端响应的数据最终都会包装成此类进行响应
* @param <T>
*/
@Data
public class R<T> implements Serializable {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
filter包 - 过滤器
解决的问题
登录拦截
项目中我们希望用户只有在登录之后才会有资格访问我们所有的页面和请求,而如果没有登录将会重定向到登录界面不允许其他任何操作。这时我们就需要设置登录过滤器。
实现方法:
- 需要添加@WebFilter注解,并在后面设置上过滤器类的名字是什么,和所要拦截的路径(这里我们设置是拦截所有路径,使用“/*”表示)。
@WebFilter(filterName = "loginCheckFilter", urlPatterns = "/*")
- 这个类需要实现Filter接口,并且重写doFilter方法。
- 完成相关逻辑代码。
- 在项目启动类上添加@ServletComponentScan 注解。
解决方法:
@WebFilter(filterName = "loginCheckFilter", urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
// 1. 获得本次请求的URI
String requestURI = request.getRequestURI();
log.info("拦截路径: {}", requestURI);
// 1.1 设置不需要处理路径
String[] urls = {
"/employee/logout",
"/employee/login",
"/backend/**",
"/front/**",
"/common/**",
"/user/sendMsg",
"/user/login"
};
// 2. 判断本次请求是否需要处理
boolean check = check(urls, requestURI);
// 3.如果不需要处理,直接放行
if(check){
filterChain.doFilter(request,response);
return;
}
// 4.1 客户端 登陆验证 如果账号已经登录,直接放行
if(request.getSession().getAttribute("employee") != null){
Long empId = (Long) request.getSession().getAttribute("employee");
//把用户的id 基于ThreadLocal 保存起来 方便后期获取
BaseContext.set(empId);
filterChain.doFilter(request,response);
return;
}
// 4.2 移动端 登陆验证 如果账号已经登录,直接放行
if(request.getSession().getAttribute("user") != null){
Long userId = (Long) request.getSession().getAttribute("user");
//把用户的id 基于ThreadLocal 保存起来 方便后期获取
BaseContext.set(userId);
filterChain.doFilter(request,response);
return;
}
// 5.如果账号还未登录,通过输出流方式向客户端返回数据
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 检查路径是否匹配
* @param urls
* @param url
* @return
*/
public boolean check(String[] urls, String url){
for (String u : urls) {
boolean match = PATH_MATCHER.match(u, url);
if(match){
return true;
}
}
return false;
}
utils包 - 工具包
解决的问题
生成验证码
/**
* 随机生成验证码工具类
*/
public class ValidateCodeUtils {
/**
* 随机生成验证码
* @param length 长度为4位或者6位
* @return
*/
public static Integer generateValidateCode(int length){
Integer code =null;
if(length == 4){
code = new Random().nextInt(9999);//生成随机数,最大为9999
if(code < 1000){
code = code + 1000;//保证随机数为4位数字
}
}else if(length == 6){
code = new Random().nextInt(999999);//生成随机数,最大为999999
if(code < 100000){
code = code + 100000;//保证随机数为6位数字
}
}else{
throw new RuntimeException("只能生成4位或6位数字验证码");
}
return code;
}
/**
* 随机生成指定长度字符串验证码
* @param length 长度
* @return
*/
public static String generateValidateCode4String(int length){
Random rdm = new Random();
String hash1 = Integer.toHexString(rdm.nextInt());
String capstr = hash1.substring(0, length);
return capstr;
}
mybatis - plus学习
坐标导入
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
解决的问题
如果实现分页查询
在mybatis中要实现分页查询的功能,我们就需要得到currentPage(当前页面位置)和pageSize(页面大小)两个参数在进行计算得到。
但是在mybatis-plus中进行分页查询以上两个参数都封装在了一个Page类中,所以我们可以直接将参数传递到Page类中,然后再调用mybatis-plus自己已经封装好的一个page方法就可以实现分页查询。但是如果只是这样我们还是不能实现分页查询。
实现方法:
-
我们还需要对分页进行拦截器配置使其生效。
解决方法:
-
进行设置分页查询拦截器
@Configuration
public class MPConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mybatisPlusInterceptor;
}
}
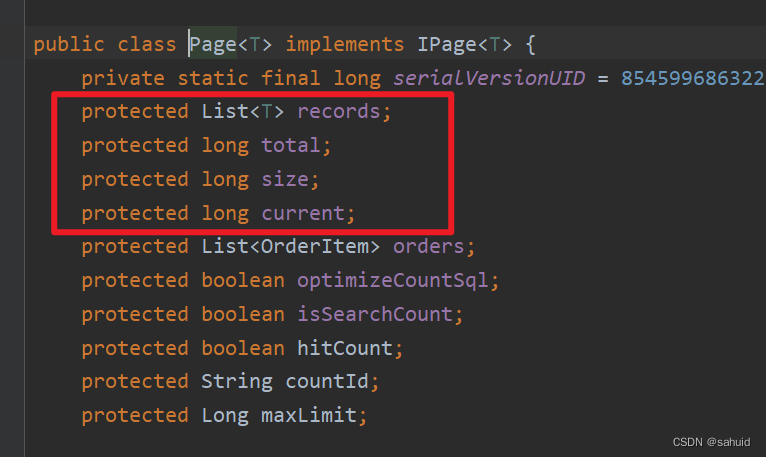
Page类介绍
在这个项目中我们对配置类的四个属性进行详细学习。
- records:是一个List列表主要保存的是分页查询出来的每一条数据。后续我们可以通过debug来查询当中的数据。
- total: 保存的是查询出来的总个数。
- size:保存的是传递过来的pageSize(页面大小)。
- current:保存的是传递过来的currentPage(当前页面的位置)。
redis学习
坐标导入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
遇到的问题
redis保存的数据是乱码形式
这里所说的乱码其实也并不算是乱码,只是算是一种序列化的数据而我们保存的key一般都是在数据的最后几位。
实现方法:
-
实现redis的序列化数据转化,将其变换成一个字符串型得序列化。
解决方法:
-
进行相关类得配置。
@Configuration
public class RedisConfig extends CachingConfigurationSelector {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory){
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
SpringCache学习
springcache技术是方便了redis操作,可以直接通过注解的形式来进行redis的缓冲,删除等操作。大大简化了我们的开发流程。
坐标导入
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
解决的问题
无法显示保存信息或者直接报错
这是的报错好像是一个序列化的错误SerializableException相关的错误。这个错误的主要原因是因为我们通常使用redis保存的数据一般都是实体类。这样就要求我们的实体类其实是需要满足序列化的。
实现方法:
-
我们对实体类进行可序列化的设置
解决方法:
-
实体类实现Serializable接口
-
生成一个serialVersionUID ===> 这里我们可以使用GenerateSerialVersionUID插件再按住alt+insert自动生成UID

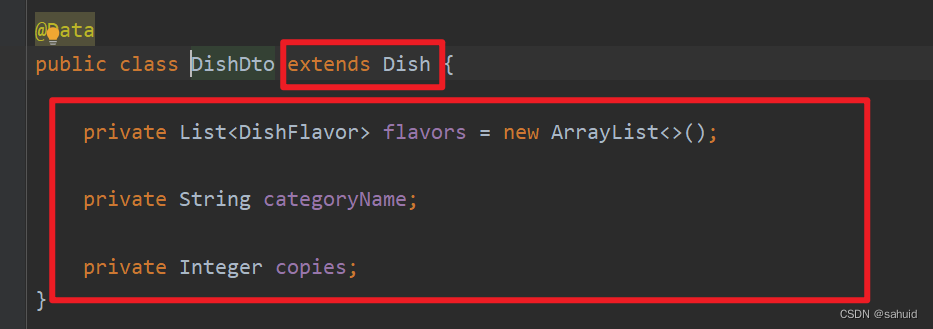
dto包介绍
所谓的dto其实也是一种实体类。只是在平常的业务中可能单纯的,没有关联的实体类经常无法满足我们的需求。比如:在我们进行菜品展示的时候可能需要一个套餐名称。这个字段可能是在套餐类中的,但是菜品类返回数据时也需要这个字段。
这时我们就需要将餐品类的所有字段属性和套餐名称进行一次封装,这个封装类就叫做dto,用来满足自己的实体类无法满足需求还需要其他实体类的属性。然后我们在进行数据返回时就可以将之前返回的实体类改成返回一个dto类。
实现方法:
- 我们只需要继承之前的实体类。
- 在添加我们需要的属性字段。
controller包 - 项目的控制层
解决的问题
图片文件的上传下载
项目中对菜品的上传需要上传图片,这时我们就需要对图片进行本地的上传与下载。
解决方法:
/**
* 文件上传下载管理*
*/
@RestController
@RequestMapping("/common")
@Slf4j
public class CommonController {
@Value("${reggie.path}")
private String path;
/**
* 文件上传*
* 返回值作为文件下载的参数*
* @param file
* @return
*/
@PostMapping("/upload")
public R<String> upload(MultipartFile file){
//获取当前图片的名字
String originalName = file.getOriginalFilename();
//截取名字后面的后缀 如.jpd
String suffix = originalName.substring(originalName.lastIndexOf("."));
//随机生成一个新的名字
String newName = UUID.randomUUID().toString() + suffix;
//判断文件目录是否存在 不存在创建一个文件
File file1 = new File(path);
if(!file1.exists()){
file1.mkdirs();
}
//把文件转存到另外一个位置
try {
file.transferTo(new File(path + newName));
} catch (IOException e) {
e.printStackTrace();
}
return R.success(newName);
}
/**
* 文件下载*
* @param name
* @param response
*/
@GetMapping("/download")
public void download(String name, HttpServletResponse response){
try {
//创建输入流读取照片
FileInputStream fileInputStream = new FileInputStream(new File(path + name));
//获取浏览器的输入流写入照片
ServletOutputStream outputStream = response.getOutputStream();
//设置一下 响应回去的是个什么类型文件
response.setContentType("image/jpeg");
//读取和写入图片
int len = 0;
byte[] bytes = new byte[1024];
while((len = fileInputStream.read(bytes)) != -1){
outputStream.write(bytes,0,len);
//刷新一下
outputStream.flush();
}
//关闭资源
outputStream.close();
fileInputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
基础逻辑的实现(举例)
此项目会进行多表联合,所以在进行多表同时修改时要添加事务管理。
@RestController
@RequestMapping("/setmeal")
@Slf4j
public class SetmealController {
@Autowired
private SetmealService setmealService;
@Autowired
private CategoryService categoryService;
@Autowired
private SetmealDishService setmealDishService;
/**
* 套餐保存*
*
* @param setmealDto
* @return
*/
@Transactional
@PostMapping
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> save(@RequestBody SetmealDto setmealDto) {
log.info("SetmealDto :{}", setmealDto.toString());
//自己构造的方法
setmealService.saveWithDish(setmealDto);
return R.success("保存成功");
}
/**
* 分页查询*
*
* @param page
* @param pageSize
* @param name
* @return
*/
@GetMapping("/page")
public R<Page> page(int page, int pageSize, String name) {
//分页构造器
Page<Setmeal> setmealPage = new Page<>(page, pageSize);
Page<SetmealDto> setmealDtoPage = new Page<>();
LambdaQueryWrapper<Setmeal> wrapper = new LambdaQueryWrapper<>();
// 对name 进行模糊查询
wrapper.like(name != null, Setmeal::getName, name);
//进行分页查询
setmealService.page(setmealPage, wrapper);
//进行数据拷贝
BeanUtils.copyProperties(setmealPage, setmealDtoPage, "records");
//获取数据
List<Setmeal> setmeals = setmealPage.getRecords();
//进行数据处理对categoryname进行赋值
List<SetmealDto> list = setmeals.stream().map((item) -> {
//将基本数据进行复制
SetmealDto setmealDto = new SetmealDto();
BeanUtils.copyProperties(item, setmealDto);
//通过id获取对象
Category category = categoryService.getById(setmealDto.getCategoryId());
//进行赋值
setmealDto.setCategoryName(category.getName());
return setmealDto;
}).collect(Collectors.toList());
setmealDtoPage.setRecords(list);
return R.success(setmealDtoPage);
}
/**
* 删除套餐*
*
* @param ids
* @return
*/
@DeleteMapping
@CacheEvict(value = "setmealCache", allEntries = true)
public R<String> delete(@RequestParam List<Long> ids) {
log.info("ids:{}", ids);
setmealService.removeWithDish(ids);
return R.success("删除成功");
}
@Cacheable(value = "setmealCache", key = "#setmeal.categoryId + '_' + #setmeal.status")
@GetMapping("/list")
public R<List<SetmealDto>> list(Setmeal setmeal) {
//根据 分类id 查询所属套餐种类
LambdaQueryWrapper<Setmeal> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(Setmeal::getCategoryId, setmeal.getCategoryId());
wrapper.eq(Setmeal::getStatus, setmeal.getStatus());
//获得查询的套餐
List<Setmeal> list = setmealService.list(wrapper);
//查询套餐里的所属菜品
List<SetmealDto> setmealDtos = list.stream().map((item) -> {
SetmealDto setmealDto = new SetmealDto();
//复制基本信息
BeanUtils.copyProperties(item, setmealDto);
//根据菜品id进行查询
LambdaQueryWrapper<SetmealDish> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(SetmealDish::getSetmealId, item.getId());
List<SetmealDish> dishes = setmealDishService.list(queryWrapper);
setmealDto.setSetmealDishes(dishes);
return setmealDto;
}).collect(Collectors.toList());
return R.success(setmealDtos);
}
}















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









