







本章从网络爬虫概述入手,介绍网络爬虫的相关基础知识,包括网络爬虫的原理、分类和应用,网络爬虫工作流程,网络爬虫协议,以及搭建Python开发环境等内容
目录
1 网络爬虫概述
网络爬虫又称为“网络蜘蛛”,是一个用来实现自动采集网络数据的程序。如果将互联网比作一张蜘蛛网,互联网上的一个个网页比作蜘蛛网上的一个个节点,那么网页与网页之间的链接关系可以比作节点间的连线,而网络爬虫就可以比作在网上爬来爬去的蜘蛛蜘蛛爬到一个节点相当于访问了该网页,提取了信息,然后顺着节点间的连线继续爬行到下一个节点,这样周而复始,蜘蛛就可以爬遍整个网络的所有节点,抓取数据。
1.1 网络爬虫原理
统一资源定位符(Uniform Resource Locator,URL)是对可以从互联网上得到的资源位置和访问方法的一种简洁表示,是互联网上标准资源的地址。
1.2 网络爬虫分类
通用网络爬虫 (称全网爬虫)
是根据网络爬虫的基本原理实现的,它所爬取的目标会从初始设定的URL扩充到全网。 通用网络爬虫主要应用于门户网站、搜索引擎和大型网络服务提供商的数据采集。
聚焦网络爬虫
目标是与预先定义好的主题相关的网页。聚焦网络爬虫只择爬取与主题相关的网页,极大地节省了硬件和网络资源。 它主要应用于对特定领域信息有需求的场景。 聚焦网络爬虫在通用网络爬虫的基础上,需要对提取的新URL进行过滤处理,过滤掉与目标主题无关的网页,且根据一定的相关性搜索策略,确定待爬取URL列表的读取顺序。
增量式网络爬虫
目标是有更新的已下载网页和新产生的网页。爬虫程序监测网站数据更新的情况,然后在需要的时候只爬取发生更新或新产生的网页。 增量式网络爬虫主要应用于网页内容会时常更新的网站,或者不断有新网页出现的网站。
深层网络爬虫
目标是不能通过静态链接获取的,隐藏在搜索表单后的,只有用户提交一些关键词才能获得的网页。 如用户注册后才可显示内容的网页。
每个独立的搜索引擎都有自己的爬虫程序,爬虫程序每天连续地爬取相关网站,提取信息保存到索引数据库中,如Google爬虫Googlebot、百度爬虫Baiduspider、必应爬虫Bingbot 等。 此外,有些搜索引擎对应不同的业务还有不同的爬虫,如百度图片爬虫Baiduspider-image、百度新闻爬虫Baiduspider-news等。
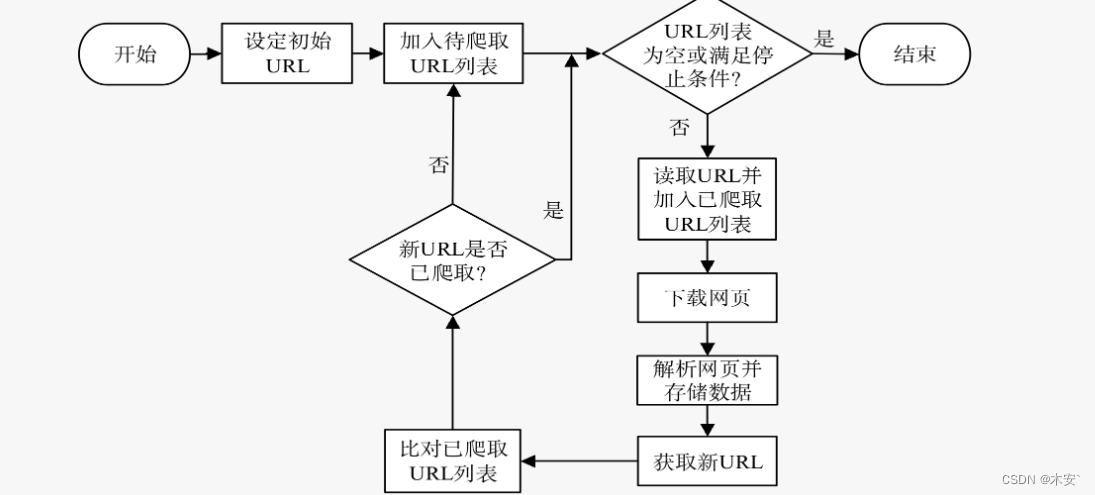
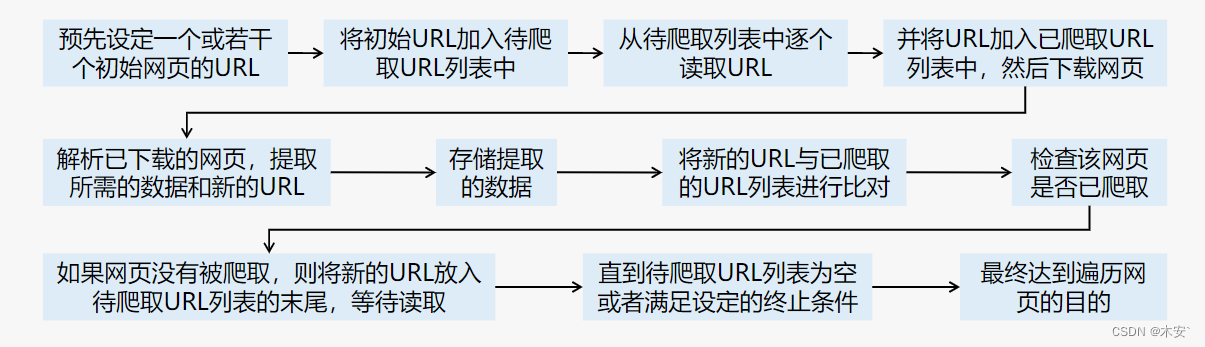
2 网络爬虫工作流程
网络爬虫是一个自动化的程序。爬虫程序首先发送请求,获取网页响应的内容,然后解析网页内容,最后将提取的数据存储到文件或数据库中。
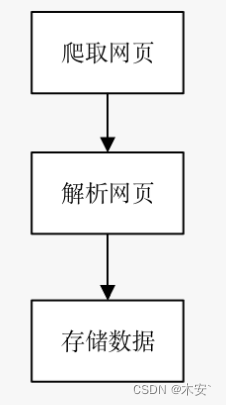
爬取网页
爬虫程序首先要做的工作是爬取网页,即获取网页的源代码。源代码里包含了网页的有用信息,所以只要把源代码爬取下来,就可以从中提取想要的信息。爬虫程序向网站的服务器发送一个HTTP请求,服务器返回给爬虫程序包含所需数据的HTTP响应(即网页源代码)。Python提供了许多与网络爬虫相关的库,其中,在爬取网页方面有urllib、requests、selenium库等。
解析网页
解析网页是用户根据网页结构,分析网页源代码,从中提取想要的数据。它可以使杂乱的数据变得条理清晰,以便用户后续处理和分析。解析网页万能的方法是正则表达式,但是构造正则表达式比较复杂且容易出错,所以Python根据网页节点属性、CSS选择器及XPath语法提供了网页的解析库, 如beautifulsoup4、lxml库等。使用这些库,用户可以高效快速地解析网页。
储存数据
解析网页提取数据后,一般要将提取到的数据保存起来以便后续使用。保存数据的方式有很多种,可以将其简单保存到JSON或CSV文件中,也可以保存到数据库中,如MySQL和MongoDB等。
3 网络爬虫协议
3.1 网络爬虫合法性
用户在爬取数据时应避免以下几个方面的问题
- 侵犯著作权。
- 侵犯商业秘密。
- 侵犯个人隐私。
- 构成不正当竞争。
- 侵入计算机系统,构成刑事犯罪。
总之,用户在爬取网站数据时,需要限制自己的爬虫程序遵守Robots协议,同时控制爬虫程序请求网页的速度。在使用数据时,必须尊重网站的知识产权。
3.2 Robots协议
Robots协议(Robots exclusion protocol)
网站管理者可以通过它来表达是否希望爬虫程序自动获取网站信息的意愿。 管理者可以在网站根目录下放置一个robots.txt文件,并在文件中列出哪些链接不允许爬虫程序获取。
robots.txt用法
网址后面加robots.txt
例
https://cn.bing.com/robots.txt
https://www.bilibili.com/robots.txt
爬虫程序访问一个网站时,它会首先检查该网站根目录下是否存在robots.txt文件, 如果存在,爬虫程序就会按照该文件中的内容来确定访问范围; 如果不存在,爬虫程序就能够访问网站上所有没被保护的网页。
访问https://cn.bing.com/robots.txt可以查看完整代码

“User-agent: Googlebot-Image”表示这部分代码针对谷歌图片爬虫,禁止或允许谷歌图片爬虫爬取某些文件;如果代码为“User-agent:*”,则表示针对所有搜索引擎的爬虫程序
“Disallow: /appview/”表示禁止爬取网站根目录的appview文件夹下的文件。
“Disallow: /login”表示禁止爬取网站根目录下所有以login开头的文件夹和文件。
“Disallow: /*?guide*”表示禁止爬取网站中所有包含guide的网址。
“Allow: /search-special”表示允许爬取网站根目录下所有以search-special开头的文件夹和文件。
如果要禁止爬虫程序爬取网站中的所有内容,可以用更简单的方法。
例如,淘宝网不允许百度的爬虫程序访问其网站下所有的目录

在百度里搜索淘宝就会显示“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取)

4 搭建Python开发环境
懂
去哔哩哔哩搜














 222
222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









