







本文内容参考自《走进搜索引擎》(第2版)潘雪峰 花贵春 梁斌 电子工业出版社 如转载请注明出处
第一章 引论
1.1 搜索引擎概述
1.1.1 搜索引擎定义:
(1)搜索引擎指自动从因特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。
【维基百科】http://zh.wikipedia.org/wiki/%E6%90%9C%E5%B0%8B%E5%BC%95%E6%93%8E
(2)搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
【百度百科】http://baike.baidu.com/link?url=BCQy7Ik-EMZ6yD89gnLOzWbRAlG6BzMEh8Gl4uK2xoTCinyGHyDxIFOZMEweFKez
(3)一种用来在计算机网络,特别是在万维网上检索各种文件的计算机程序。【WordNet】
因此,与其说搜索引擎是一个查询系统,不如说它是一个用户定义的信息聚合系统。
1.1.2 搜索引擎分类
(1)目录是搜索引擎:信息检索通常为人工发现信息,依靠编辑人员的知识进行甄选,并进行分类;早起的雅虎和搜狐都是这种搜索引擎。
(2)全文搜索引擎:针对万维网上所有网页进行全文搜索的搜索引擎,主要由下载系统、索引系统及查询系统组成;谷歌,百度等公司属于该类型。
(3)元搜索引擎:将用户的索引词提交给多个搜索引擎根据其返回的查询结果进行进一步筛选及重新排序,之后在返回给用户;
代表网站:www.webcrawler.com、http://www.dogpile.com/
1.2 搜索引擎的主要需求
【快】反映搜索引擎的查询速度,一般的商用引擎反映速度在毫秒级;主要受分词效果,索引库的效率,分布查询的处理功能和查询缓存的命中率影响。
【全】一般用查全率(Recall)作为衡量检索是否全面的度量指标,Recall=N(索引出网页数量)/M(包含索引信息的全部网页数量)*100%;主要取决于网页索引库中条目数量。
【准】一般以查准率(Precision)作为衡量检索是否准确的指标,Precision=P(与查询相关的网页)/N(全部索引的网页数)*100%;主要取决于网页排序。
【稳】长期稳定提供服务。
【省】据美国哈佛大学物理学者研究以台式机在Google网站执行两次搜索,所制作的二氧化碳相当于煮一壶茶;主要考虑电能、带宽、机器折旧。
1.3 搜索引擎四大系统
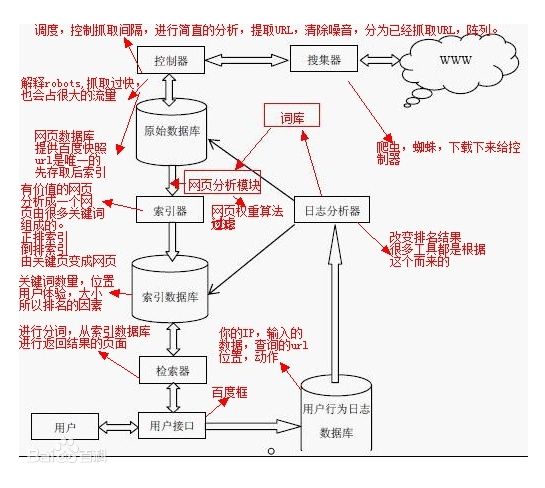
从整体上看,下载、分析、索引系统属于离线部分,查询系统属于在线部分。
第二章 搜索引擎的下载系统
2.1 爬虫发展史
【世界上第一个爬虫】又MIT的学生马休 格雷与1993年写成,主要用于抓去万维网网页信息。
【应用于搜索引擎】1994年Michael Mauldin将一个蜘蛛程序写入索引程序,创立搜素引擎公司Lycos http://www.lycos.com/















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









