







 本文深入解析VGG模型,一种流行且高效的卷积神经网络结构,由Simonyan和Zisserman于2014年提出。VGG模型以其简单的结构和强大的应用能力受到广泛欢迎,尤其在图像分类任务上表现突出。文章详细介绍了VGG-16的网络结构,包括13层卷积和3层全连接层,以及如何使用小尺寸卷积核和池化层来构建深度神经网络。
本文深入解析VGG模型,一种流行且高效的卷积神经网络结构,由Simonyan和Zisserman于2014年提出。VGG模型以其简单的结构和强大的应用能力受到广泛欢迎,尤其在图像分类任务上表现突出。文章详细介绍了VGG-16的网络结构,包括13层卷积和3层全连接层,以及如何使用小尺寸卷积核和池化层来构建深度神经网络。
内容都是百度AIstudio的内容,我只是在这里做个笔记,不是原创。
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和pooling层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
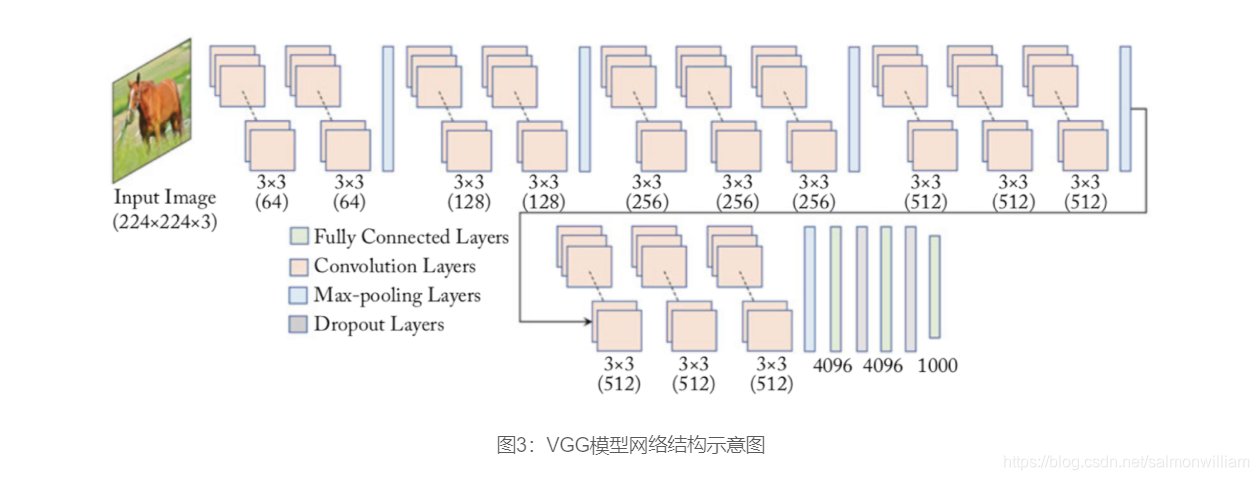
图3 是VGG-16的网络结构示意图,有13层卷积和3层全连接层。VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层3×3卷积层,可以得到感受野为5的特征图,而比使用5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以更好的学习图像中的特征模式。
# -*- coding:utf-8 -*-
import cv2
import random
import numpy as np
# 对读入的图像数据进行预处理
def transform_img(img):
# 将图片尺寸缩放道 224x224
img = cv2.resize(img, (224, 224))
# 读入的图像数据格式是[H, W, C]
# 使用转置操作将其变成[C, H, W]
img = np.transpose(img, (2,0,1))
img = img.astype('float32')
# 将数据范围调整到[-1.0, 1.0]之间
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 将datadir目录下的文件列出来,每条文件都要读入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 训练时随机打乱数据顺序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H开头的文件名表示高度近似,N开头的文件名表示正常视力
# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0
label = 0
elif name[0] == 'P':
# P开头的是病理性近视,属于正样本,标签为1
label = 1
else:
raise('Not excepted file name')
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签
# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容
# csvfile文件所包含的内容格式如下,每一行代表一个样本,
# 其中第一列是图片id,第二列是文件名,第三列是图片标签,
# 第四列和第五列是Fovea的坐标,与分类任务无关
# ID,imgName,Label,Fovea_X,Fovea_Y
# 1,V0001.jpg,0,1157.74,1019.87
# 2,V0002.jpg,1,1285.82,1080.47
# 打开包含验证集标签的csvfile,并读入其中的内容
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',')
name = line[1]
label = int(line[2])
# 根据图片文件名加载图片,并对图像数据作预处理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# LeNet 识别眼疾图片
import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
DATADIR2 = '/home/aistudio/work/palm/PALM-Validation400'
CSVFILE = '/home/aistudio/work/palm/PALM-Validation-GT/labels.csv'
# 定义训练过程
def train(model):
use_gpu = True
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
print('start training ... ')
model.train()
epoch_num = 5
# 定义优化器
opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())
# 定义数据读取器,训练数据读取器和验证数据读取器
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 进行loss计算
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
avg_loss = fluid.layers.mean(loss)
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向传播,更新权重,清除梯度
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别
# 计算sigmoid后的预测概率,进行loss计算
pred = fluid.layers.sigmoid(logits)
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
# 计算预测概率小于0.5的类别
pred2 = pred * (-1.0) + 1.0
# 得到两个类别的预测概率,并沿第一个维度级联
pred = fluid.layers.concat([pred2, pred], axis=1)
acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# save params of model
fluid.save_dygraph(model.state_dict(), 'mnist')
# save optimizer state
fluid.save_dygraph(opt.state_dict(), 'mnist')
# 定义评估过程
def evaluation(model, params_file_path):
use_gpu = True
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
print('start evaluation .......')
#加载模型参数
model_state_dict, _ = fluid.load_dygraph(params_file_path)
model.load_dict(model_state_dict)
model.eval()
eval_loader = load_data('eval')
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 计算预测和精度
prediction, acc = model(img, label)
# 计算损失函数值
loss = fluid.layers.cross_entropy(input=prediction, label=label)
avg_loss = fluid.layers.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
# VGG模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
# 定义vgg块,包含多层卷积和1层2x2的最大池化层
class vgg_block(fluid.dygraph.Layer):
def __init__(self, num_convs, in_channels, out_channels):
"""
num_convs, 卷积层的数目
num_channels, 卷积层的输出通道数,在同一个Incepition块内,卷积层输出通道数是一样的
"""
super(vgg_block, self).__init__()
self.conv_list = []
for i in range(num_convs):
conv_layer = self.add_sublayer('conv_' + str(i), Conv2D(num_channels=in_channels,
num_filters=out_channels, filter_size=3, padding=1, act='relu'))
self.conv_list.append(conv_layer)
in_channels = out_channels
self.pool = Pool2D(pool_stride=2, pool_size = 2, pool_type='max')
def forward(self, x):
for item in self.conv_list:
x = item(x)
return self.pool(x)
class VGG(fluid.dygraph.Layer):
def __init__(self, conv_arch=((2, 64),
(2, 128), (3, 256), (3, 512), (3, 512))):
super(VGG, self).__init__()
self.vgg_blocks=[]
iter_id = 0
# 添加vgg_block
# 这里一共5个vgg_block,每个block里面的卷积层数目和输出通道数由conv_arch指定
in_channels = [3, 64, 128, 256, 512, 512]
for (num_convs, num_channels) in conv_arch:
block = self.add_sublayer('block_' + str(iter_id),
vgg_block(num_convs, in_channels=in_channels[iter_id],
out_channels=num_channels))
self.vgg_blocks.append(block)
iter_id += 1
self.fc1 = Linear(input_dim=512*7*7, output_dim=4096,
act='relu')
self.drop1_ratio = 0.5
self.fc2= Linear(input_dim=4096, output_dim=4096,
act='relu')
self.drop2_ratio = 0.5
self.fc3 = Linear(input_dim=4096, output_dim=1)
def forward(self, x):
for item in self.vgg_blocks:
x = item(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = fluid.layers.dropout(self.fc1(x), self.drop1_ratio)
x = fluid.layers.dropout(self.fc2(x), self.drop2_ratio)
x = self.fc3(x)
return x
with fluid.dygraph.guard():
model = VGG()
train(model)

















 6512
6512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









