







算法基本思想:设无向连通网为G=(V, E),令G的最小生成树为T=(U, TE),其初态为U=V,TE={ },然后,按照边的权值由小到大的顺序,考察G的边集E中的各条边。若被考察的边的两个顶点属于T的两个不同的连通分量,则将此边作为最小生成树的边加入到T中,同时把两个连通分量连接为一个连通分量;若被考察边的两个顶点属于同一个连通分量,则舍去此边,以免造成回路,如此下去,当T中的连通分量个数为1时,此连通分量便为G的一棵最小生成树。
我们在前面讲过的《克里姆算法》是以某个顶点为起点,逐步找各顶点上最小权值的边来构建最小生成树的。同样的思路,我们也可以直接就以边为目标去构建,因为权值为边上,直接找最小权值的边来构建生成树也是很自然的想法,只不过构建时要考虑是否会形成环而已,此时我们就用到了图的存储结构中的边集数组结构,如图7-6-7
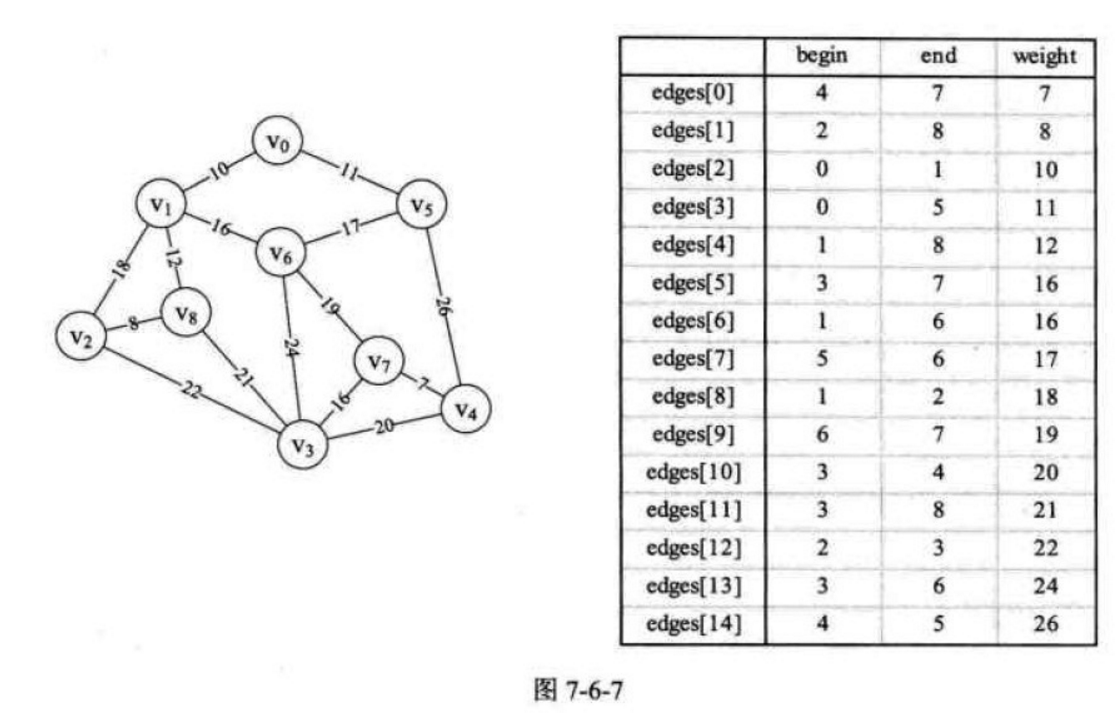
假设现在我们已经通过邻接矩阵得到了边集数组edges并按权值从小到大排列如上图。
下面我们对着程序和每一步循环的图示来看:
算法代码:(改编自《大话数据结构》)
typedef struct
{
int begin;
int end;
int weight;
} Edge;
/* 查找连线顶点的尾部下标 */
int Find(int *parent, int f)
{
while (parent[f] > 0)
f = parent[f];
return f;
}
/* 生成最小生成树 */
void MiniSpanTree_Kruskal(MGraph G)
{
int i, j, n , m;
int k = 0;
int parent[MAXVEX];/* 定义一数组用来判断边与边是否形成环路 */
Edge edges[MAXEDGE];/* 定义边集数组,edge的结构为begin,end,weight,均为整型 */
/* 此处省略将邻接矩阵G转换为边集数组edges并按权由小到大排列的代码*/
for (i = 0; i < G.numVertexes; i++)
parent[i] = 0;
cout << "打印最小生成树:" << endl;
for (i = 0; i < G.numEdges; i++)/* 循环每一条边 */
{
n = Find(parent, edges[i].begin);
m = Find(parent, edges[i].end);
if (n != m)/* 假如n与m不等,说明此边没有与现有的生成树形成环路 */
{
parent[n] = m;/* 将此边的结尾顶点放入下标为起点的parent中。 */
/* 表示此顶点已经在生成树集合中 */
cout << "(" << edges[i].begin << ", " << edges[i].end << ") "
<< edges[i].weight << endl;
}
}
}1、程序 第17~28行是初始化操作,中间省略了一些存储结构转换代码。
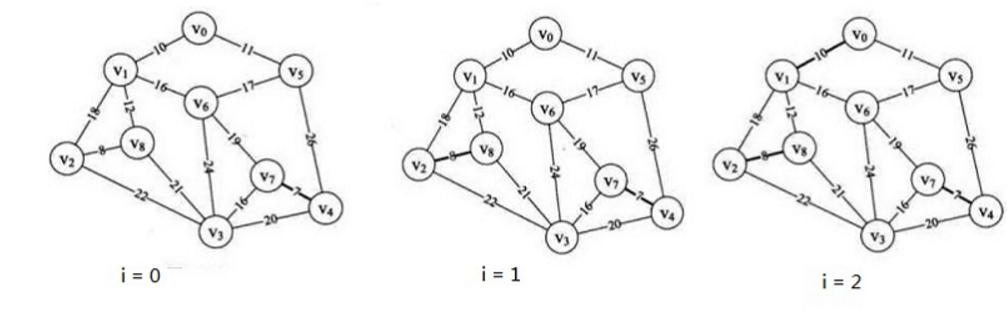
2、第30~42行,i = 0 第一次循环,n = Find( parent, 4) = 4; 同理 m = 7; 因为 n != m 所以parent[4] = 7, 并且打印 “ (4, 7) 7 ” 。此时我们已经将边(v4, v7)纳入到最小生成树中,如下图的第一个小图。
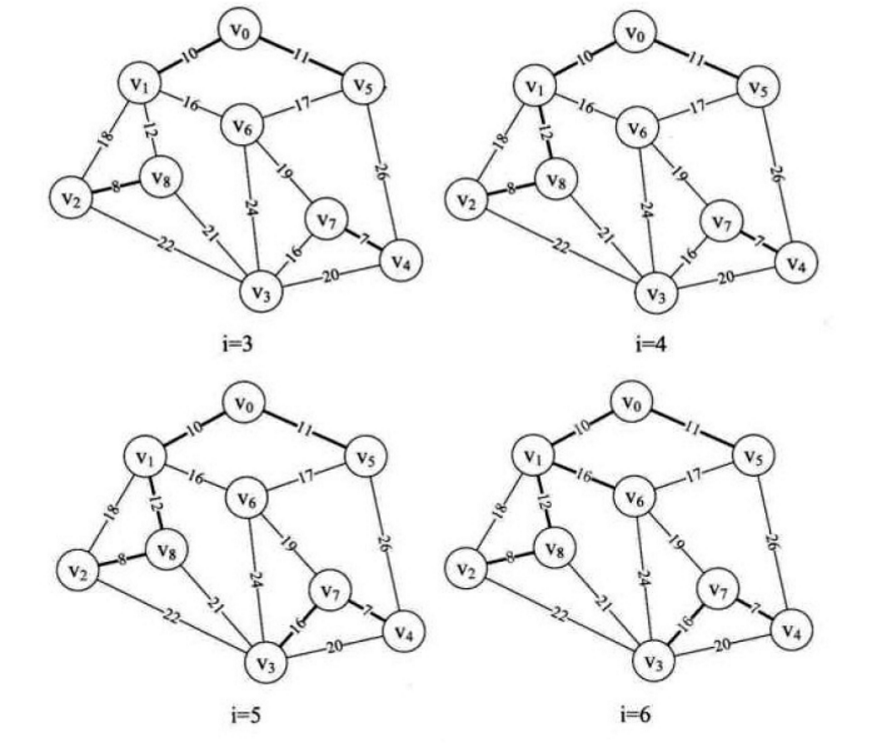
3、继续循环,当i从1 至 6 时,分别把(v2, v8), (v0, v1), (v0, v5), (v1, v8), (v3, v7), (v1, v6)纳入到最小生成树中,如下图所示,此时parent数组为
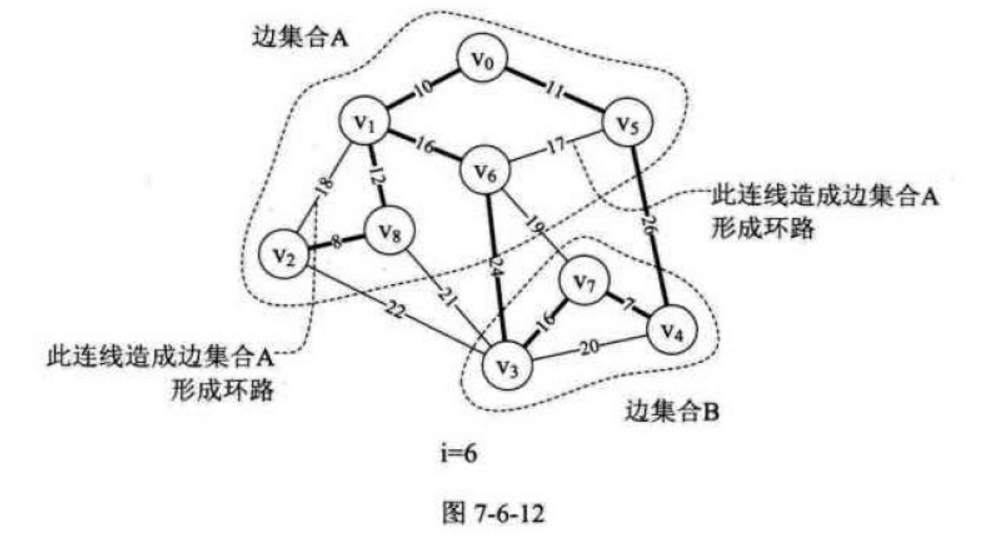
{ 1, 5, 8, 7, 7, 8, 0, 0, 6 },如何解读现在这些数字的意义呢?从图i = 6来看,其实是有两个连通的边集合A与B 纳入到最小生成树找中的,如图7-6-12所示。parent[0] = 1表示v0 和v1 已经在生成树的边集合A中,将parent[0] = 1中的 1 改成下标,由parent[1] = 5 ,表示v1 和v5 已经在生成树的边集合A中,parent[5] = 8 ,表示v5 和v8 已经在生成树的边集合A中,parent[8] = 6 ,表示v8 和v6 已经在生成树的边集合A中,parent[6] = 0 表示集合A暂时到头,此时边集合A有 v0, v1, v5, v6, v8。查看parent中没有查看的值,parent[2] = 8,表明v2 和 v8在一个集合中,即A中。再由parent[3] = 7, parent[4] = 7 和 parent[7] = 0 可知v3, v4, v7 在一个边集合B中。
4、当i = 7时, 调用Find函数,n = m = 6,不再打印,继续下一循环,即告诉我们,因为(v5, v6) 使得边集合A形成了回路,因此不能将其纳入生成树中,如图7-6-12所示。
5、当i = 8时与上面相同,由于边(v1, v2) 使得边集合A形成了回路,因此不能将其纳入到生成树中,如图7-6-12所示。
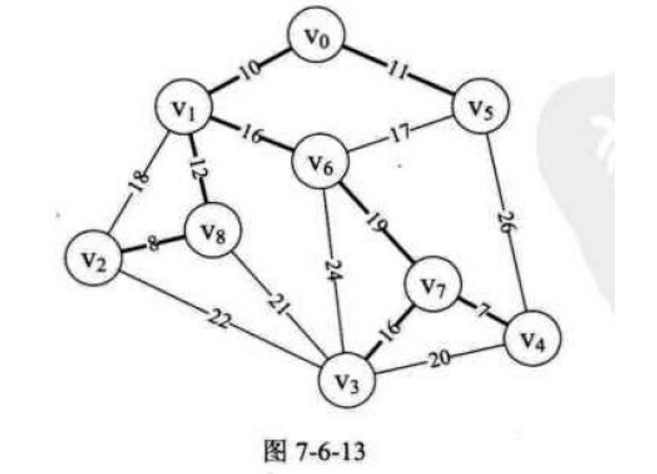
6、当i = 9时,n = 6, m = 7, 即parent[6] = 7,打印“(6, 7)19” ,此时parent数组为{ 1, 5, 8, 7, 7, 8, 7, 0, 6 } ,如图7-6-13所示。
最后,我们来总结一下克鲁斯卡尔算法的定义:
假设 N = (V, {E} )是连通网,则令最小生成树的初始状态为只有n个顶点而无边的非连通图T { V, {} },图中每个顶点自成一个连通分量。在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将其加入到 T 中,否则舍去此边而选择下一条代价最小的边。依次类推,直至T中所有顶点都在同一连通分量上为止。
此算法的Find函数由边数e决定,时间复杂度为O(loge),而外面有一个for循环e次,所以克鲁斯卡尔算法的时间复杂度为O(eloge)。
对比普里姆和克鲁斯卡尔算法,克鲁斯卡尔算法主要针对边来展开,边数少时效率比较高,所以对于稀疏图有较大的优势;而普里姆算法对于稠密图,即边数非常多的情况下更好一些。















 7463
7463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









