







 本文介绍了十大算法,包括二分查找、分治法、动态规划、KMP字符匹配、贪心算法、普利姆与克鲁斯卡尔最小生成树算法、迪杰斯特拉与弗洛伊德最短路径算法,以及骑士周游问题。通过实例解析了每个算法的实现与应用,适合复习与学习。
本文介绍了十大算法,包括二分查找、分治法、动态规划、KMP字符匹配、贪心算法、普利姆与克鲁斯卡尔最小生成树算法、迪杰斯特拉与弗洛伊德最短路径算法,以及骑士周游问题。通过实例解析了每个算法的实现与应用,适合复习与学习。
ps: 十大算法合集,学习来源是尚硅谷Java数据结构与java算法,自留复习。
1.二分法查找算法非递归实现
int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] > target) {
right = mid - 1;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
return mid;
}
}
return -1;
}
2.分治算法和汉诺塔问题




void hanoTower(int num, char a, char b, char c) {
if (num == 1) {
//如果只有一个盘
System.out.println("第1个盘从" + a + "->" + c);
} else {
//如果两个盘以上 看做下面一个盘和上面所有盘
//先把上面的盘a->b 移动过程会使用到c
hanoTower(num - 1, a, c, b);
//把最下面的盘a->c
System.out.println("第" + num + "个盘从" + a + "->" + c);
//把b所有的盘b->c 移动过程会使用到a
hanoTower(num - 1, b, a, c);
}
}
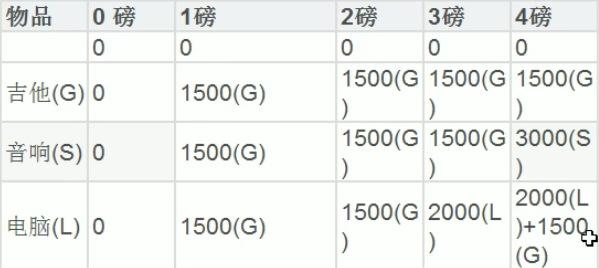
3.动态规划算法和背包问题



算法实现
int[] w = {
1, 4, 3};//物品重量
int[] value = {
1500, 3000, 2000};
int m = 4;//背包容量
int n = value.length;//物品个数
//v[i][j]表示前i个物品中能装入容量为j的背包中的最大值
// 行标题是背包容量0 1 2 3 4 列标题是物品0 1500 3000 2000
int[][] v = new int[n + 1][m + 1];
//用来记录选择的搭配
int[][] path = new int[n + 1][m + 1];
//初始化 第一列 和 第一行
for (int i = 0; i < v.length; i++) {
v[i][0] = 0;
}
for (int i = 0; i < v[0].length; i++) {
v[0][i] = 0;
}
重点
//根据公式进行动态规划处理 不处理第一行及第一列
for (int i = 1; i < v.length; i++) {
for (int j = 1; j < v[0].length; j++) {
if (w[i - 1] > j) {
//如果要加入的商品容量>背包容量 w[0]开始
v[i][j] = v[i - 1][j]; //采用上一格的装配策略
} else {
//如果要加入的商品容量<背包容量
// value,w从0开始
//v[i][j] = Math.max(v[i - 1][j], value[i-1] + v[i - 1][j - w[i-1]]);
if (v[i - 1][j] < value[i - 1] + v[i - 1][j - w[i - 1]]) {
v[i][j] = value[i - 1] + v[i - 1][j - w[i - 1]];
//把当前情况记录到path
path[i][j] = 1;
} else {
v[i][j] = v[i - 1][j];
}
}
}
}
//遍历输出v[i][j]
for (int i = 0; i < v.length; i++) {
for (int j = 0; j < v[0].length; j++) {
System.out.print(v[i][j] + " ");
}
System.out.println();
}
//输出path
for (int i = 0; i < path.length; i++) {
for (int j = 0; j < path[i].length; j++) {
if(path[i][j]==1) {
System.out.print("第" + i + "个商品放入到背包中" + " ");
}else{
System.out.print(" * ");
}
}
System.out.println();
}
//逆向遍历
int i = path.length - 1;
int j = path[0].length - 1;
while (i > 0 && j > 0) {
if (path[i][j] == 1) {
System.out.print("第" + i + "个商品放入到背包中" + " ");
j -= w[i - 1]; //第i个商品的重量w[i - 1]
}
i--;
}
输出结果

4.KMP算法和字符匹配问题

暴力匹配
//暴力匹配算法 一个个字符依次去比较

static int violenceMatch(String str1, String str2) {
char[] s1 = str1.toCharArray();
char[] s2 = str2.toCharArray();
int l1 = s1.length;
int l2 = s2.length;
int i = 0;//指向s1索引
int j = 0;//指向s2索引
while (i < l1 && j < l2) {
//匹配时不可越界
if (s1[i] == s2[j]) {
i++;
j++;
}  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









