






摘要
图像级弱监督语义分割由于其低标注成本而受到越来越多的关注。现有的方法主要依赖于类激活映射(Class Activation Mapping, CAM)来获取伪标签,用于训练语义分割模型。在本研究中,我们首次证明了训练数据中的长尾分布会导致通过分类器权重计算的CAM在头部类别上过度激活,而在尾部类别上激活不足,这是由于头部和尾部类别之间共享特征所导致的。这种现象会降低伪标签的质量,并进一步影响最终的语义分割性能。为了解决这一问题,我们提出了一种用于CAM生成的共享特征校准(Shared Feature Calibration, SFC)方法。具体来说,我们利用携带正向共享特征的类别原型,并提出了一种多尺度分布加权一致性损失(Multi-Scaled Distribution-Weighted Consistency Loss, MSDW),用于在训练过程中缩小通过分类器权重和类别原型生成的CAM之间的差距。MSDW损失通过校准头部/尾部类别分类器权重中的共享特征,来平衡过度激活和激活不足的问题。实验结果表明,我们的SFC方法显著改善了CAM的边界,并实现了新的最先进性能。该项目可在 GitHub - Barrett-python/SFC: SFC: Shared Feature Calibration in Weakly Supervised Semantic Segmentation (AAAI24) 获取。
引言:
然而,我们发现WSSS(弱监督语义分割)的训练数据自然呈现长尾分布(如图1(a)所示)。这使得共享特征组件(Li和Monga 2020)在头部类别的分类器权重中倾向于为正,而在尾部类别的分类器权重中倾向于为负。这是因为头部类别的权重接收到更多的正梯度(表示为⊕)而不是负梯度(表示为⊖),而尾部类别的权重接收到更多的负梯度而不是正梯度(如图1(b)所示)。这使得包含共享特征的像素被头部类别的分类器权重激活(即特征和权重的点积(表示为·)> 0),而包含尾部类别特征的像素则不被尾部类别的权重激活(即特征和权重的点积 < 0),如图1(c)所示。因此,通过分类器权重计算的CAM(类激活图)不可避免地导致头部类别的激活过度,而尾部类别的激活不足(如图1(d)所示)。这降低了伪标签的质量,并进一步影响了WSSS的最终性能。另一方面,如图1(d)所示,由头部类别原型(Chen等,2022a)激活的CAM与由头部类别分类器权重激活的CAM相比,激活程度较低;而由尾部类别原型激活的CAM与由尾部类别分类器权重激活的CAM相比,激活程度较高。
长尾分布问题:
在WSSS的训练数据中,头部类别(即样本数量较多的类别)和尾部类别(即样本数量较少的类别)的分布不均衡,呈现长尾分布。这种不均衡导致模型在训练过程中对头部类别和尾部类别的学习效果不同。
共享特征组件的梯度问题:
由于头部类别的样本数量多,模型在训练过程中会接收到更多的正梯度,使得头部类别的分类器权重倾向于为正。相反,尾部类别的样本数量少,模型会接收到更多的负梯度,使得尾部类别的分类器权重倾向于为负。
梯度是指损失函数对模型参数的偏导数,它指示了参数应该如何更新以最小化损失函数。正梯度和负梯度描述了梯度方向对参数更新的影响
CAM的激活问题:
CAM是通过分类器权重和特征的点积来计算的。由于头部类别的权重为正,包含共享特征的像素容易被头部类别的分类器权重激活(点积 > 0)。而尾部类别的权重为负,包含尾部类别特征的像素不容易被尾部类别的分类器权重激活(点积 < 0)。
原型激活是指利用类别原型来激活图像中与类别相关的区域。具体来说,通过计算图像特征与类别原型之间的相似度,生成类激活图(CAM),从而定位图像中属于该类别的区域。类别原型是某个类别的特征空间的中心或代表性特征向量。它可以看作是该类别的“平均特征”或“典型特征”。在训练过程中,模型会为每个类别学习一个原型,这个原型能够代表该类别的全局特征。
在传统的CAM方法中,类激活图是通过分类器权重与特征图的点积生成的。然而,这种方法在长尾分布的数据中容易出现问题:
分类器权重激活:
分类器权重是通过训练数据学习得到的,容易受到数据分布不均衡的影响。
在长尾分布中,头部类别的权重倾向于为正,尾部类别的权重倾向于为负,导致头部类别的CAM过激活,尾部类别的CAM欠激活。
原型激活:
原型是基于类别特征的中心表示的,能够更好地捕捉类别的全局特征。
原型激活对数据分布不均衡的敏感性较低,能够更均衡地激活头部类别和尾部类别的区域。
受上述发现的启发(详细的理论分析见主论文中的“共享特征校准分析”部分),我们提出了一种共享特征校准(Shared Feature Calibration, SFC)方法,旨在减少头部类别分类器权重中的共享特征比例,并增加尾部类别分类器权重中的共享特征比例,从而避免由共享特征引起的过度激活或欠激活问题。具体来说,我们在通过类别原型和分类器权重生成的类激活图(CAM)上计算了一种多尺度分布加权一致性损失(Multi-Scaled Distribution-Weighted Consistency Loss, MSDW),其中每个类别的一致性损失大小通过该类别与其他类别之间的样本数量差距进行重新加权。我们还证明了这种重新加权策略背后的理论,表明通过我们的SFC方法可以获得边界更好的伪标签。本工作的贡献包括:
-
首次指出:在长尾分布场景下,头部类别和尾部类别共享的特征会扩大由分类器权重生成的头部类别的CAM,同时缩小尾部类别的CAM。
-
提出SFC方法:我们提出了一种共享特征校准(SFC)的CAM生成方法,旨在平衡不同分类器权重中的共享特征比例,从而提高CAM的质量。
-
实现新的SOTA性能:我们的方法在仅使用图像级标签的情况下,在Pascal VOC 2012和COCO 2014数据集上实现了新的最先进的弱监督语义分割(WSSS)性能。
类别原型生成的CAM:通过类别原型(Class Prototype)生成的CAM,能够捕捉类别的全局特征,对长尾分布问题较为鲁棒。
分类器权重生成的CAM:通过分类器权重生成的CAM,容易受到长尾分布的影响,导致头部类别的CAM过度激活,尾部类别的CAM欠激活。
2. MSDW损失的作用
MSDW损失的目标是强制这两种CAM之间的一致性,即让分类器权重生成的CAM尽可能接近类别原型生成的CAM。这样做的目的是:
减少偏差:通过引入类别原型的全局特征信息,减少分类器权重生成的CAM在头部类别和尾部类别上的偏差。
提高伪标签质量:通过一致性约束,生成更准确、边界更清晰的伪标签,从而提升弱监督语义分割的性能。
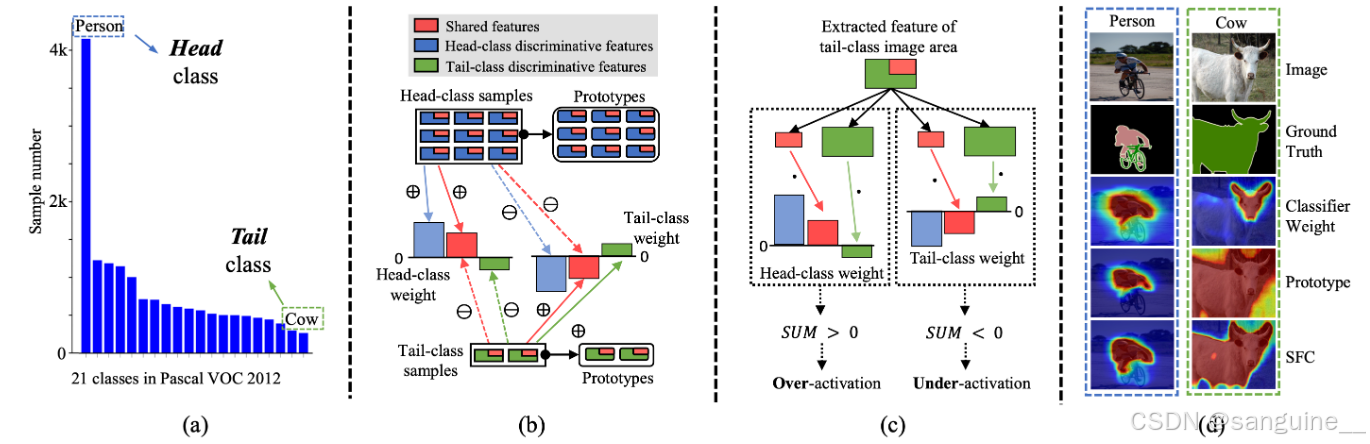
图一:说明在长尾情景下共享特征如何影响cam以及我们提议的SFC的影响。(a)表明Pascal VOC 2012 (Everingham等人2010)是一个天然的长尾分布式数据集。(b)解释了头/尾类分类器权重和原型中的共享特征组件。(c)显示了过度/欠激活是如何发生的。(d)显示了头/尾类示例的cam。我们的SFC通过适当的激活区域达到更好的效果。
激活是通过计算特征和权重的点积(dot product)来确定的。如果点积大于0,则认为特征被激活;如果小于0,则认为未被激活。
在图 c 中,显示了头类分类器权重(i.e., 包含共享特征的权重)会激活包含共享特征的像素,而尾类权重则不会激活这些像素。
正梯度(Positive Gradients)
正梯度是指模型在训练过程中,对于某个类别的样本,模型预测值与真实标签相比偏离正方向(即预测值偏低)时产生的梯度。这些梯度用于指导模型在后续的训练中增加对应特征的权重,以便更好地识别这些类别的样本。在长尾分布的数据集中,头类(样本数量较多的类别)会产生更多的正梯度,因为这些类别的样本在训练集中占比较大,模型更容易在这些类别上产生误差。
负梯度(Negative Gradients)
负梯度是指模型在训练过程中,对于某个类别的样本,模型预测值与真实标签相比偏离负方向(即预测值偏高)时产生的梯度。这些梯度用于指导模型在后续训练中减小对应特征的权重,从而减少对这些类别的误识别。在长尾分布的数据集中,尾类(样本数量较少的类别)会产生更多的负梯度,因为这些类别的样本较少,模型在这些类别上更容易出现过拟合,导致在这些类别上产生误差。
方法
我们的共享特征校准(SFC)方法的流程如图2所示。它包括图像库重采样(Image Bank Re-sampling, IBR)和多尺度分布加权一致性损失(Multi-Scaled Distribution-Weighted Consistency Loss, MSDW)。
分类器权重 CAM :给定输入图像 I,编码器从 I 中提取的特征表示为 F ∈RH×W ×D ,类 c 的分类器权重表示为 Wc ∈ RD×1,其中 H × W 是特征图大小,D是特征维度。分类损失,即多标签软边际损失,计算如下:
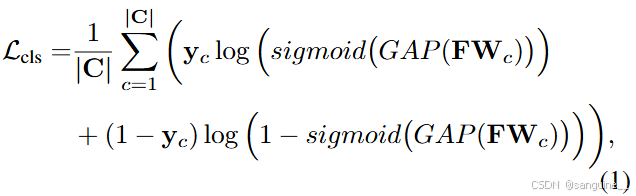
其中,C 是前景类别集合,∣C∣ 表示其大小;yc 表示类别 c 上的二元标签;GAP(·) 表示全局平均池化。然后,通过分类器权重 W(即分类器权重 CAM)在输入图像 I 的提取特征 F 上生成的类激活图(CAM)计算如下:

其中,MW 表示分类器权重生成的类激活图(CAM),f(⋅) 表示一个函数,它将经过归一化并经过 ReLU 激活的 FW、输入图像 I以及特征 F 输入到像素相关性模块(Pixel Correlation Module, PCM)(Wang 等,2020)中,以基于不同像素的低级特征之间的关系来优化 CAM。
原型 CAM(Prototype CAM):根据 Chen 等人在 2022年和2023年的研究,类别原型是通过提取的特征进行掩码平均池化(masked average pooling)来计算的。具体来说,从特征提取器的不同层提取的层次化特征分别表示为 F1,F2,F3,F4;L(⋅) 表示线性投影,并且它阻止梯度向特征提取器传播。然后,类别 ~c的原型 P ~c(~c可以是前景类别或背景类别)计算如下:
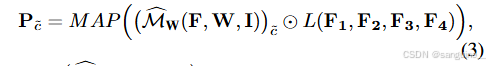
掩码平均池化的过程:
生成掩码:
首先,需要生成一个掩码,这个掩码是一个与特征图大小相同的二值矩阵,其中非零元素表示感兴趣的区域(例如,通过某种方式确定的类别相关区域),零元素表示不感兴趣的区域(例如,背景或其他类别的区域)。
应用掩码:
将掩码与特征图逐元素相乘。这意味着掩码中的非零元素会保留特征图中的相应激活值,而零元素会将特征图中的相应激活值置为零。
计算平均值:
对乘以掩码的特征图进行平均池化操作,即计算所有非零激活值的平均值。这可以通过对所有非零元素求和后除以非零元素的数量来实现。
其中MW(F,W,I)是̃c类的二进制掩码,突出显示激活值高于集合阈值的像素;M AP(·)表示掩码平均池。最后,通过类 ̃c(即原型 CAM)原型计算的 CAM 计算如下:
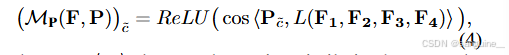
余弦相似度计算:
计算原型 P\tilde{\tilde}{c} 与线性投影后的特征之间的余弦相似度。余弦相似度衡量两个向量之间的相似程度,其值范围在 -1 到 1 之间。值越接近 1,表示两个向量越相似。
生成原型 CAM:
使用 ReLU 函数处理余弦相似度结果,保留对目标类别有正向贡献的区域,生成最终的原型 CAM。
共享特征校准
图像库重采样(Shared Feature Calibration Image Bank Re-sampling,简称IBR)是一种用于改善长尾分布数据集上弱监督语义分割性能的方法。
我们维护一个图像库 B=(b1,...,bc),该库存储了 ∣C∣ 个前景类别的图像。对于当前训练批次中的每张图像 I,当第 c 个类别出现在图像 I 中时,我们用图像 I 更新对应的库 bc。否则,我们保持 bc 不变。在库更新后,我们从当前库中均匀地采样 NIBR 张图像,并将它们与原始训练批次拼接作为最终的训练输入。均匀采样不会因长尾分布而带来进一步的共享特征问题,因为不同类别的样本数量几乎平衡。我们提出的IBR用于增加尾类别的采样频率,因此MSDW(Multi-Scaled Distribution-Weighted consistency loss)损失将更频繁地强制应用于尾类别,有效地校准尾类别分类器权重中的共享特征。
多尺度分布加权一致性损失为了解决头部类的过度激活问题和尾部类的欠激活问题,我们提出了两种分布加权(DW)一致性损失LP DW和LW DW。LP DW 在原型 CAM 和分类器权重 CAM 之间计算为:
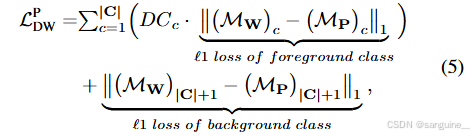
它是用来衡量原型类别激活图(prototype CAM)和分类器权重类别激活图(classifier weight CAM)之间的一致性。这个损失函数特别关注于长尾分布数据集中的类别不平衡问题,尝试通过校准共享特征来提高分割性能。
其中 DCc 表示缩放分布系数,为每个前景类 c 计算为:
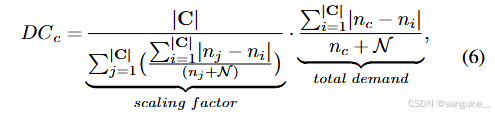
这段描述中,nc 表示类别 c 的样本数量;N 表示我们通过图像库重采样(IBR)在每个类别上估计增加的样本数量,并且 N=NIBR⋅CIBR⋅Niter⋅∣C∣。这里,Niter 表示在一个训练周期(epoch)中的迭代次数;NIBR 是从图像库中采样的数量;CIBR 是一张图像中覆盖的平均类别数量。
我们计算 c 类与其他类之间的样本数差距之和,并将该总和视为对 c 类一致性损失的总需求。接下来,这个总奖励由 nc + N(即 c 类的估计总样本数)平均,并用比例因子进行缩放,得到缩放分布系数(即 DCc)。比例因子是将前景类的ℓ1损失幅度缩放到与背景类相同的级别。
DCc 最终用于重新加权 c 类上的一致性损失,为总需求较高的类分配更高的一致性损失,因为过度/欠激活问题的严重程度与总需求呈正相关。
同时,当前训练批次中的所有图像通过双线性插值算法进一步缩小 0.5,用于计算损失 LW DW:
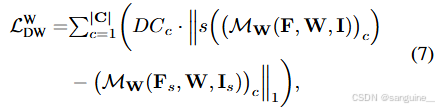
其中 s(·) 表示双线性下采样操作; Is 表示下采样图像,Fs 表示其提取的特征。与方程式类似。 (5),我们通过 DC 系数重新加权一致性损失。考虑到缩小图像上的原型 CAM 比原始图像上计算的缩小分类器权重 CAM 不太准确(参见附录中具有多尺度方案的 LW DW),我们计算原始图像上缩小的分类器权重 CAM 与缩小图像上的分类器权重 CAM 之间的一致性损失。LW DW 进一步提高了性能改进。我们的多尺度分布加权一致性损失 LMSDW 公式如下:
![]()
推理:用于推理的最终 CAM 计算为
![]()
其中(Mfinal)̃c表示̃c类的最终CAM;̃c可以是前景类或背景类。这样,分类器权重 CAM 由原型 CAM 补充,共同解决过度/欠激活问题。
Analysis on SFC
本节展示了分类器权重中的共享特征如何在长尾场景下导致过度/欠激活问题和SFC背后的工作机制
分类器权重中的共享特征分布
在图像级别的弱监督语义分割(WSSS)中,通常使用一种多标签软边界损失(记作 L)来训练分类模型(Chen 等人,2022a)。根据(Tan 等人,2021)中的定义,由 L 引起的正梯度和负梯度可以表述如下:
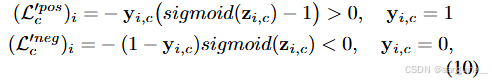
在这里,zi,c 表示模型对第 i 个样本在类别 c 上的预测对数(logit),而 sigmoid(zi,c) 表示该预测对数经过 sigmoid 激活函数后的值;yi,c 表示第 i 个样本在类别 c 上的标签(可以是 0 或 1);(Lpos_c′)i 和 (Lneg_c′)i 分别表示在 zi,c 上的正梯度和负梯度。
考虑一个简化的情况,其中有一个头类(Hand)和一个尾类(T),基于不同类别之间存在共享特征的结论(Hou, Yu, 和 Tao 2022; Liu 等人 2021; Li 和 Monga 2020),头类图像特征可以分解为 αHfH+ηHf0,其中 αHfH 和 ηHf0 分别表示区分性特征部分和共享特征部分,αH 和 ηH 表示它们的比例。同样,尾类图像特征可以分解为 αTfT+ηTf0。然后,头类分类器权重 WH 可以表示为:
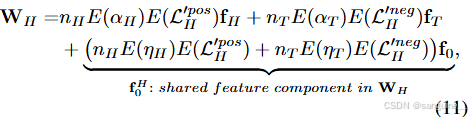
其中 nH 和 nT 表示头类和尾类的样本数,nH ≫ nT 在长尾场景下;E(·) 表示期望操作。类似地,我们有尾部类分类器权重 WT 为:
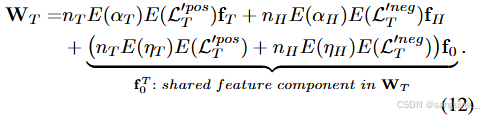
式(11)和式(12)的证明见附录证明1。然后,如附录的梯度幅度分析所示,E(L′pos) 的大小大于 E(L′neg ) 的大小,差距并不显着。结合 nH ≫ nT 的前提,可以得出结论,在等式中。 (11)我们有 nH E(L′pos H ) + nT E(L′neg H ) > 0。类似地,在等式中。 (12)我们有 nT E(L′pos T ) + nH E(L′neg T ) < 0。然后,基于方程式。 (11) 和等式。 (12),我们可以有:
结论 1. 当 nH ≫ nT 和 E(ηH ) 和 E(ηT ) 之间的差异与 nH 和 nT 之间的差异不显着时,WH 中的共享特征分量(即 f H0 )往往具有较大的幅度为正,WT 中的特征分量(即 f T0 )往往为负,幅度较大。然而,当 nH ≈ nT 时,具有较高 E(η) 的类在其分类器权重中具有更大的共享特征,并且共享特征幅度将远低于 nH ≫ nT 时。
过度激活(Over-activation)和未充分激活(Under-activation):
对于尾类图像区域提取的一个特征可以分解为 AT=αATfT+ηATf0(其中 αAT 和 ηAT 分别是特征 fT 和 f0 的比例)。类似地,头类图像区域提取的一个特征可以分解为 AH=αAHfH+ηAHf0。在长尾分布情况下(即,nH≫nT ),头类/尾类分类器权重对 AT 和 AH 的激活可以表述如下:
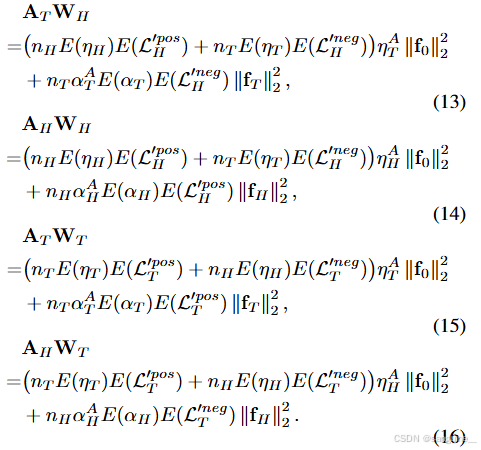
基于附录中通过证明2得出的结论1,我们得到了结论2: 结论2. 当 nH≫nT 时,即头类样本数远大于尾类样本数时,AHWT 和 ATWT 倾向于未被激活,而 WT 与真实标签相比在尾类图像区域有未充分激活的问题(如图3(b)的尾类部分所示)。相反,AHWH 和 ATWH 倾向于被激活,而 WH 与真实标签相比在头类图像区域有过度激活的问题(如图3(b)的头类部分所示)。
另一方面,对于通过对其分类器权重激活的特征进行平均来提取的类别原型,它仅具有正向共享特征。因此,基于结论2,通过附录中的证明3,我们得到了结论3: 结论3. 设 PH 和 PT 分别表示头类 H 和尾类 T 的原型,A 表示包括 AH 和 AT 的图像区域。当 nH≫nT 时,APH 与 AWH 相比激活程度较低(如图3(b)和图3(c)的头类所示)。相反,APT 与 AWT 相比激活程度更高(如图3(b)和图3(c)的尾类所示)。
How SFC Works
正如公式 (5) 所描述的,我们的分布加权(DW)一致性损失使得原型CAM和分类器权重CAM对于以下几对更加接近:{AT_WH , AT_PH},{AT_WT , AT_PT},{AH_WH , AH_PH},{AH_WT , AH_PT}。因此,WH 或 WT 被强制学习向由 PH 或 PT 激活的特征靠近。当 nH≫nT 时,基于结论 3,我们有:
情况 1:对于 {AT_WH , AT_PH},与 AT_WH 相比,AT_PH 的激活程度较低。由于 AT 包含 f0 和 fT,WH 被优化为向 −f0 和 −fT 靠近,这为 WH 缩小其在尾类区域的CAM带来了积极效果。
情况 2:对于 {AT_WT , AT_PT},与 AT_WT 相比,AT_PT 的激活程度更高。由于 AT 包含 f0 和 fT,W_T 被优化为向 f0 和 fT 靠近,这为 WT 扩展其在尾类区域的CAM带来了积极效果。
情况 3:对于 {AH_WT , AH_PT},与 AH_WT 相比,AH_PT 的激活程度更高。由于 AH 包含 f0 和 fH,W_T 被优化为向 f0 和 fH 靠近。由于 WT 具有较大幅度的 −f0 和 −fH(结论 1),优化 WT 向正向 f0 和 fH 几乎不会产生负面影响。
情况 4:对于 {AH_WH , AH_PH},与 AH_WH 相比,AH_PH 的激活程度较低。由于 AH 包含 f0 和 fH,WH 被优化为向 −f0 和 −fH 靠近。由于 WH 具有较大幅度的 f0 和 fH(结论 1),优化 WH 向 −f0 和 −fH 几乎不会产生负面影响。
总结来说,具有严重过度激活/未充分激活问题的分类器权重可以从情况 1 和情况 2 中受益,而它们不会受到情况 3 和情况 4 的负面影响,从而如图 3(d) 所示改善整体的CAM。然而,当 nH≈nT 时,一致性会负面影响CAM的生成。例如,通过拉近 {AH_WT , AH_PT} 这一对,由于 PT 包含 f0 并且它激活 AH 包含 f0 和 fH,W_T 将被优化为向 f0 和 fH 靠近。然而,当 nH≈nT 时(结论 1),W_T 没有较大幅度的 −f0 或 −fH,增加 W_T 中的 fH 和 f0 会产生负面影响。考虑到一致性损失在 nH≫nT 时带来积极效果,而在 nH≈nT 时带来负面影响,我们通过将该类别与其他所有其他类别之间的样本数量差距相加,然后将其视为该类别一致性损失的权重(即公式 (5) 中的 DC 系数),最大化一致性损失的效果。
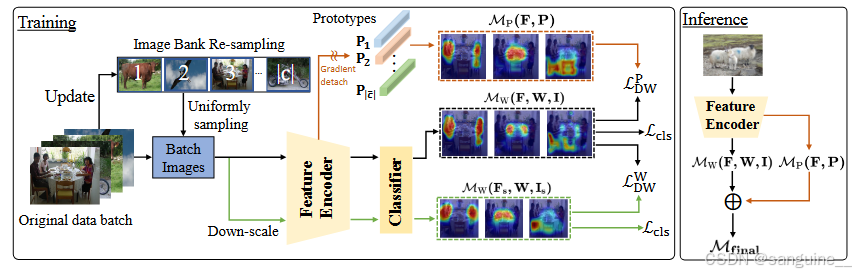
图二: 我们提出的共享特征校准(Shared Feature Calibration,简称SFC)的整体结构如下:对于每张训练图像,计算两个分布加权一致性损失(LP DW 和 LW DW),其中LP DW 是在原始图像的原型CAM(MP)和分类器权重CAM(MW)之间计算的,而LW DW 是在降采样的图像上的分类器权重CAM和原始图像之间计算的。此外,维护一个图像库,该库存储了不同类别的最新显示图像,并从中均匀采样图像以补充原始训练批次,增加了尾类别的一致性损失优化频率。最后,在推理过程中,分类器权重CAM与原型CAM相辅相成。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









