






DINOv2:
图像-文本预训练方法会忽略一些位置信息,导致性能不佳,DINOv2 是基于自我监督学习的,不依赖文本描述。再加上强大的执行力,DINOv2 能够为单眼深度估计提供最先进的结果。对于上下文,单目深度估计是一项任务,其目标是预测哪些对象在前景中,哪些对象在背景中。
单目深度估计(Monocular Depth Estimation)是指从单张二维图像中恢复出三维场景的深度信息。其目标是解决从二维图像到三维场景的逆问题,即重建场景中每个像素点到相机的距离。这一任务在计算机视觉领域具有重要意义,因为它涉及到对人类深度感知机制的理解以及深度学习技术的应用
单目深度估计在弱监督语义分割中具有重要作用,它通过提供深度线索、辅助对象定位、增强上下文理解和减少标注依赖等方式,帮助提高语义分割的准确性和效率
DINOv2 的特性总结如下:
- DINOv2 是一种训练高性能计算机视觉模型的新方法。
- DINOv2 提供了强大的性能,并且不需要微调。
- 由于是自监督( self-supervision),DINOv2 可以从任何图像集合中学习。同时,它还可以学习到当现有方法无法学习的某些特征,例如深度估计。
DINOv2研究内容:
创建了一个新的高质量数据集:图三。通过从大量未经整理的数据池中检索与几个经过整理的数据集中的图像相近的图像,来组建一个新的数据集。从 12亿 张图片中得到了经过整理的 1.42 亿张图像,命名为 LVD-142M 数据集。这一过程中,通过采用自监督图像检索技术,大大提高了数据集的质量和多样性,为后面 DINOv2 的训练提供了更加丰富的数据资源。
这篇讲的很好:⭐DINOv2: Learning Robust Visual Features without Supervision 2023 CVPR-CSDN博客
DINOv2模型是否带有registers
DINOv2 的寄存器(Registers)机制是一种改进的模型架构设计,主要用于解决视觉 Transformer(ViT)在注意力图中出现的伪影问题,并提升模型的性能和可解释性。
寄存器机制通过在输入序列的末尾添加一些特殊的可学习 token(称为寄存器 token)来实现。这些寄存器 token 在预训练阶段被使用,其主要作用是为模型提供额外的存储空间,用于存放全局信息。在预训练完成后,这些寄存器 token 会被丢弃。
功能与优势
-
消除伪影:在传统的 ViT 模型中,注意力图中会出现一些高范数的 token,这些 token 主要集中在图像的低信息背景区域,并被模型重新用于内部计算,从而导致伪影。寄存器机制通过为模型提供额外的 token 来存储这些全局信息,从而避免了使用图像块作为“寄存器”,有效消除了注意力图中的伪影。
-
提升可解释性:使用寄存器机制后,注意力图变得更加清晰和可解释。例如,[CLS] token 可以更好地集中在图像中的主要物体上,而寄存器 token 则会关注到一些不同的区域。
-
性能提升:寄存器机制不仅解决了伪影问题,还提升了模型在密集视觉预测任务上的性能。此外,它还使得使用更大模型进行对象发现成为可能。
实现细节
-
配置参数:在 DINOv2 with Registers 的配置类
Dinov2WithRegistersConfig中,可以通过参数num_register_tokens来指定寄存器 token 的数量。 -
模型架构:寄存器 token 被添加到输入序列的末尾,在模型的每一层中都会参与到自注意力计算中。在预训练完成后,这些寄存器 token 会被丢弃,不会影响下游任务。
摘要:
近年来,自然语言处理对大量数据进行模型预训练的突破为计算机视觉中类似的基础模型开辟了道路。这些模型可以通过生成通用的视觉特征来极大地简化任何系统中图像的使用,即在不进行微调的情况下跨图像分布和任务工作的特征。这项工作表明,现有的预训练方法,尤其是自我监督方法,如果在来自不同来源的足够策划的数据上进行训练,可以产生这些特征。我们回顾了现有的方法,并结合了不同的技术,以根据数据和模型大小扩展我们的预训练。大多数技术贡献旨在大规模加速和稳定训练。在数据方面,我们提出了一个自动管道来构建专用、多样化和策划的图像数据集,而不是未经策划的数据,就像在自我监督文献中通常所做的那样。在模型方面,我们训练了一个具有 1B 参数的 ViT 模型 (Dosovitskiy et al., 2021),并将其提炼成一系列更小的模型,这些模型在图像和像素级的大多数基准上都超过了最好的通用特征 OpenCLIP (Ilharco et al., 2021)。
1 Introduction
拉斐尔等人,2020;Chowdhery et al., 2022;Hoffmann等人,2022;Touvron et al., 2023)。人们可以“按原样”使用这些特征,即无需微调,并在下游任务上实现比特定任务模型产生的性能要好得多的性能(Brown et al., 2020)。随着NLP的这种范式转变,我们期望类似的“基础”模型出现在计算机视觉中(Bommasani et al., 2021)。这些模型应该在任何任务上生成开箱即用的视觉特征,无论是在图像级别,例如图像分类,还是在像素级别,例如分割。Mahajan et al., 2018;Radford等人;这种形式的文本引导预训练限制了可以保留的关于图像的信息,因为字幕只能近似图像中的丰富信息,而复杂的像素级信息可能不会在这种监督下出现。此外,这些图像编码器需要对齐的文本-图像语料库,因此不提供文本对应物的灵活性,也就是说,只能从原始数据中学习。
文本引导预训练的另一种替代方法是自监督学习(Caron等人,2018;Chen et al., 2020;他等人,2022),其中仅从图像中学习特征。这些方法在概念上更接近语言建模等借口任务,可以在图像和像素级别捕获信息(Caron等人,2021)。此外,自监督模型输出的特征已被证明具有各种有用的特性,并且已经启用了各种各样的应用(Amir等人,2022;Tumanyan et al., 2022;Ofri-Amar等,2023;Hamilton et al., 2022)。然而,尽管它们具有学习通用特征的潜力,但自监督学习的大部分进展都是在小型精选数据集ImageNet-1k的预训练背景下取得的(Russakovsky et al., 2015)。已经尝试了将这些方法扩展到ImageNet-1k之外的一些努力(Caron等人,2019;Goyal等人,2021;2022a),但他们关注的是未经整理的数据集,这通常会导致特征质量的显著下降。这是因为缺乏对数据质量和多样性的控制,而数据质量和多样性是产生好的特征所必需的。
在这项工作中,我们探索如果在大量的策划数据上进行预训练,自我监督学习是否有学习通用视觉特征的潜力。我们重新审视了现有的在图像和补丁级别学习特征的判别自监督方法,如iBOT (Zhou等人,2022a),并在更大的数据集的镜头下重新考虑了它们的一些设计选择。我们的大部分技术贡献都是为了在模型和数据规模缩放时稳定和加速判别式自监督学习。这些改进使我们的方法比类似的判别式自监督方法快2倍,需要的内存少3倍,使我们能够利用更长的训练时间和更大的批处理规模。
关于预训练数据,我们已经建立了一个自动管道来过滤和平衡来自大量未经整理的图像的数据集。该管道的灵感来自NLP中使用的管道(Wenzek等人,2020),其中使用数据相似度而不是外部元数据,并且不需要手动注释。处理野外图像时的一个主要困难是重新平衡概念并避免在几个主要模式上过度拟合。在这项工作中,一个朴素的聚类方法可以很好地解决这个问题。我们收集了一个小而多样的142M图像语料库来验证我们的方法。
最后,我们提供了各种预训练的视觉模型,称为DINOv2,在我们的数据上使用不同的视觉变形器(ViT) (Dosovitskiy等人,2016)架构进行训练。我们发布了所有的模型和代码,以便在任何数据上重新训练DINOv2。我们在各种计算机视觉基准上验证了DINOv2在图像和像素级别上的质量,如图2所示。我们得出的结论是,单独的自监督预训练是学习可转移的冻结特征的一个很好的候选者,与最好的公开可用的弱监督模型竞争。

图一:第一个PCA分量的可视化。我们计算来自同一列(a, b, c和d)的图像补丁之间的PCA,并显示它们的前3个分量。每个组件都与不同的颜色通道相匹配。无论姿势、风格甚至物体的变化,相同的部分在相关图像之间都是匹配的。背景通过阈值法去除第一个PCA分量。
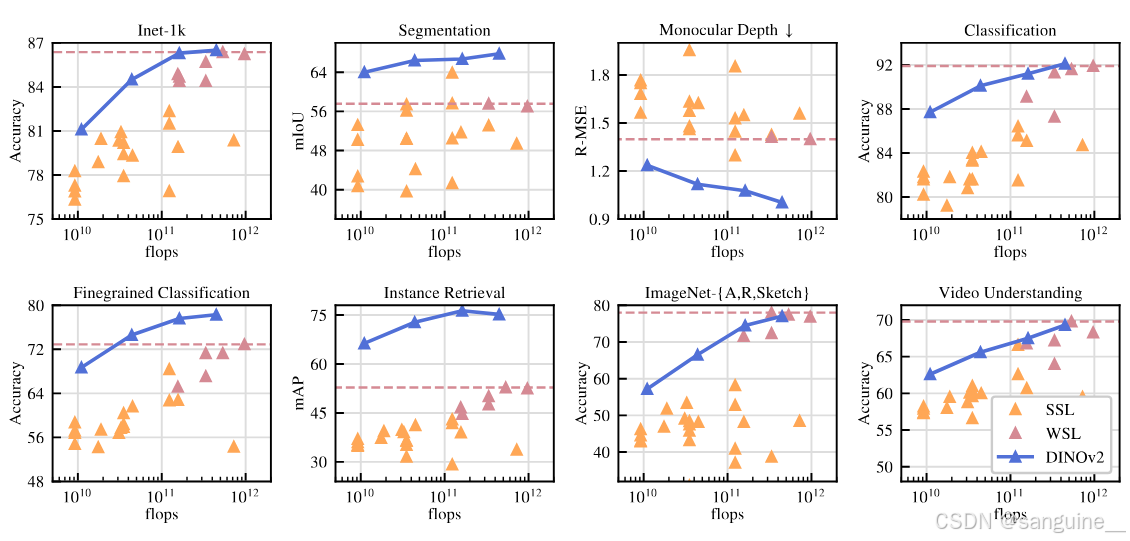
图2:调整参数时性能的演变。我们展示了八种类型的视觉任务的性能,如第7节所示,以及每种类型的平均指标。特征是从我们的自监督编码器DINOv2(深蓝色)中提取的,我们将它们与自监督方法(浅橙色)以及弱监督方法(深粉红色)进行比较。我们将表现最好的弱监督模型的表现用虚线表示。我们的模型家族在自监督学习方面大大提高了以前的技术水平,并达到了与弱监督特征相当的性能。详细分析请参见第7节。
2 Related Work
图像内自我监督训练。第一类自我监督方法侧重于从图像中提取信号的借口任务,即从图像中提取要从图像的其余部分预测的信号。随着Doersch等人(2015)的工作,这个想法变得普遍,他们通过预测给定补丁的上下文来训练。许多其他借口任务是基于重新着色图像(Zhang et al., 2016)、预测转换(Gidaris et al., 2018)、修复(Pathak et al., 2016)或补丁重新排序(Noroozi & Favaro, 2016;Misra & Maaten, 2020)。最近,基于补丁的架构(如 ViT)的出现重新讨论了预训练修复(He et al., 2022; Bao et al., 2021; El-Nouby et al., 2021),可能在特征空间中(Assran et al., 2023; Baevski et al., 2022)。特别有趣的是,He 等人。 (2022) 表明,掩码自动编码器 (MAE) 在对下游任务进行微调时学习提供实质性改进的特征。MAE 的这一特性已在视频 (Tong et al., 2022)、音频 (Xu et al., 2022) 和其他模态 (Girdhar et al., 2023) 上进一步验证。然而,它们的特征需要监督微调,而我们的特征开箱即用。
判别自监督学习。第二行更接近我们的工作是使用图像或图像组之间的判别信号来学习特征。这一系列方法起源于早期的深度学习工作(Hadsell 等人,2006 年),但随着实例分类方法的出现而变得流行(Dosovitskiy 等人,2016 年;Bojanowski 和 Joulin,2017 年;Wu 等人,2018 年)。几个改进,基于实例级目标(Hénaff 等人,2019;He 等人,2020;Chen 和 He,2021;Chen 等人,2020;Grill 等人,2020;Caron 等人,2021)或聚类(Caron 等人,2018;Asano 等人,2020;Caron 等人,2020)进行了一些改进。这些方法在标准基准测试(如 ImageNet,Russakovsky 等人,2015)上提供了性能良好的冻结特征,但它们很难扩展到更大的模型尺寸(Chen 等人,2021)。在这项工作中,我们在大型预训练数据集和模型的背景下重新审视了这些方法的训练。特别是,我们基于 Zhou 等人(2022a)的研究进行构建,我们发现这种方法特别适合于扩展。
缩放自我监督预训练。越来越多的工作集中在自我监督学习在数据和模型大小方面的缩放能力上(Caron 等人,2019;Goyal 等人,2019;Tian 等人,2021;Goyal 等人,2022a)。这些作品中的大多数都使用大量未经策划的数据来训练没有监督的模型。他们表明,判别方法随数据扩展,但由于预训练数据质量较差,大部分结果都是通过微调特征来获得的。特别有趣的是,Goyal等人(2021)还表明,这些方法受益于在给定足够预训练数据的情况下模型大小的缩放。这一系列工作质疑自监督方法在任何数据上工作的能力,而我们专注于生成最好的预训练编码器。
自动数据管理。我们的数据集构建借鉴了图像检索社区(Weinzaepfel 等人,2021;Radenović 等人,2018b;Berman 等人,2019;Douze 等人,2009;Tolias 等人,2016;Revaud 等人,2019)。特别是,在半监督学习的背景下研究了使用检索来增强训练集(Yalniz 等人,2019 年)。同样,其他人使用主题标签或其他元数据(Mahajan 等人,2018 年;Radford 等人,2021 年)或预训练的视觉编码器(Schuhmann 等人,2021 年;2022 年)来过滤未策划的数据集。与这些工作不同,我们不使用预训练的编码器、元数据或监督来过滤图像并利用图像之间的视觉相似性。我们的方法受到文本管理管道的启发(Wenzek et al., 2020),其中语言模型在 Wikipedia 上进行训练,以对从未经策划的源中提取的文本进行评分。
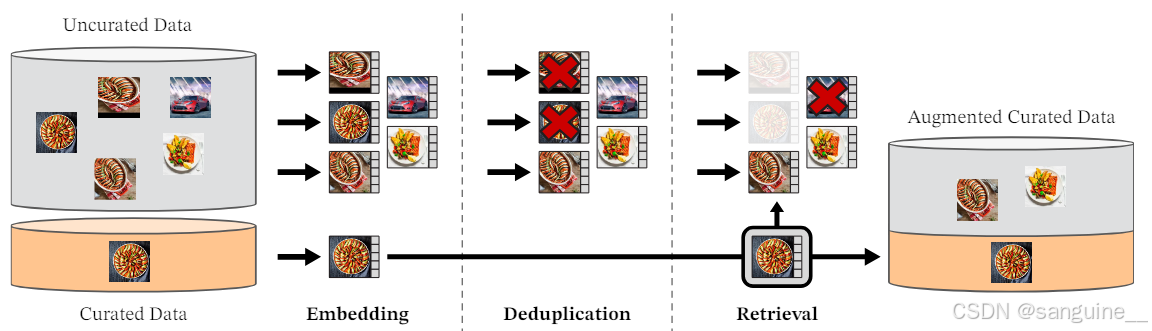
图 3:我们的数据处理管道概述。来自策划和未策划的数据源的图像首先映射到嵌入。然后,在与策划图像匹配之前,未策划的图像被重复数据删除。生成的组合通过自监督检索系统增强初始数据集。
3 Data Processing
我们通过从大量未经策划的数据中检索接近几个精选数据集中的图像来组装我们策划的 LVD-142M 数据集。我们在下面描述了数据管道中的主要组成部分,包括策划/未策划的数据源、图像重复数据删除步骤和检索系统。我们的管道不需要任何元数据或文本,直接与图像一起工作,如图3所示。我们建议读者参阅附录A,了解我们的方法的更多细节。
数据来源。我们在附录(表 15)中详细列出了精选的数据集,包括 ImageNet-22k、ImageNet-1k 的训练集、Google Landmarks 以及几个细粒度的数据集。对于未精选的数据源,我们从一个公开的爬取网络数据的存储库中收集了一个原始未筛选的图像数据集。我们从存储库中的每个网页中提取 `<img>` 标签中的图像 URL 链接。我们丢弃了那些不安全或受域名限制的 URL,并对下载的图像进行后处理(PCA 哈希去重、不适宜内容过滤和模糊可识别的面部)。这最终得到了 12 亿张独特的图像。
重复数据删除。我们将Pizzi等人(2022)的复制检测管道应用于未整理的数据,并去除近重复的图像。这减少了冗余并增加了图像之间的多样性。我们还删除了本工作中使用的任何基准的测试或验证集中包含的接近重复的图像
自监督图像检索。我们通过从我们的非策划数据源中检索与我们策划源中的图像接近的图像来构建我们的策划预训练数据集。为了做到这一点,我们首先使用在ImageNet-22k上预训练的自监督ViT-H/16网络计算图像嵌入,并使用余弦相似度作为图像之间的距离度量。然后,我们对未整理的数据执行k-means聚类。给定一个用于检索的查询数据集,如果它足够大,我们为每个查询图像检索N(通常为4)个最近邻。如果它很小,我们从每个查询图像对应的集群中采样M个图像。尽管视觉检查似乎表明N比4大得多的检索质量很好,但这会导致更多的冲突(多个查询的最近邻检索的图像)。我们选择sen = 4,因为它在这个意义上提供了很好的权衡。
实现细节。我们的管道的重复数据删除和检索阶段依赖于Faiss库(Johnson等人,2019)来有效地索引和计算最近嵌入的批量搜索。特别是,我们大量利用其对gpu加速索引的支持,使用带有产品量化代码的反向文件索引(Jegou等,2010)。整个处理过程分布在20个节点的计算集群上,配备8个V100-32GB的gpu,生成LVD-142M数据集的时间不超过两天。
4 Discriminative Self-supervised Pre-training
我们使用判别自我监督方法来学习我们的特征,该方法可以看作是DINO和iBOT损失与SwAV中心的结合(Caron等人,2020)。我们还添加了一个正则化器来传播特征和较短的高分辨率训练阶段。我们快速介绍这些方法中的每一种,但更多细节可以在相关论文或我们的开源代码中找到。
图像级目标(Caron等人,2021年)。我们考虑从学生和教师网络中提取的特征之间的交叉熵损失。这两种特征都来自ViT的类标记,该标记由同一图像的不同作物获得。我们通过学生 DINO 头传递学生类标记。这个头部是一个 MLP 模型,输出一个分数向量,我们称之为“原型分数”。然后我们应用 softmax 来获得 ps。类似地,我们将教师 DINO 头应用于教师类标记以获得教师原型分数。然后我们应用 softmax,然后使用移动平均(或此后详述的 Sinkhorn-Knopp 中心)居中以获得 pt。DINO损失项对应:
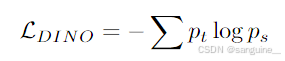
我们学习学生的参数,并以过去迭代的指数移动平均构建教师头(He et al., 2020)。
补丁级目标(Zhou et al., 2022a)。我们随机屏蔽学生给出的一些输入补丁,而不是老师。然后,我们将学生 iBOT 头部应用于学生掩码标记。类似地,我们将教师 iBOT 头部应用于与学生蒙面的令牌相对应的(可见)教师补丁令牌。然后我们应用如上所述的 softmax 和居中步骤,并获得 iBOT 损失项:
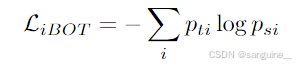
其中 i 是掩码标记的补丁索引。与上述类似,我们学习学生的参数,并通过指数移动平均构建教师头。
两个目标之间的空头权重。DINO 和 iBOT 损失都使用可学习的 MLP 投影头。它应用于输出标记,损失计算顶部。在周等人。 (2022a) 中,消融研究表明 DINO 和 iBOT 头部之间共享参数可以获得更好的性能。大规模,我们观察到相反的情况是正确的,因此我们在所有实验中都使用了两个独立的头部。
Sinkhorn-Knopp居中(Caron等人,2020年)。Ruan等人(2023)建议用SwAV的Sinkhorn-Knopp (SK)批处理归一化替换DINO和iBot的教师softmax中心步骤(Caron等人,2020)。我们运行 Sinkhorn-Knopp 算法步骤 3 次迭代。对于学生,我们应用 softmax 归一化。
KoLeo正则化器(Sablayrolles等人,2019年)。KoLeo 正则化器源自 Kozachenko-Leonenko 微分熵估计器(参见 Beirlant 等人(1997);Delattre & Fournier (2017)),并鼓励批次中特征的均匀跨度。给定一组 n 个向量 (x1,., xn),定义为
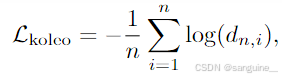
其中dn,i = minj̸=i∥xi−xj∥是xi与批内任何其他点之间的最小距离。我们还在计算这个正则化器之前对特征进行ℓ2-归一化。
调整分辨率(Touvron等人,2019年)。提高图像分辨率是像素级下游任务的关键,例如分割或检测,其中小物体在低分辨率下消失。然而,高分辨率训练需要时间和内存,相反,我们在预训练结束时在短时间内将图像的分辨率提高到 518 × 518。这也类似于Likhomanenko等人(2021)的UniViT训练和Beyer等人(2023)的FlexiViT训练。
5 Efficient implementation
我们考虑在更大范围内训练模型的几种改进。我们使用 PyTorch 2.0 在 A100 GPU 上训练模型。代码和预训练模型可在 Apache 2.0 许可 1 下获得。我们模型的细节在附录中,表 17。与 iBOT 实现相比,DINOv2 代码仅使用 1/3 的内存运行速度快大约 2 倍。
快速和内存高效的注意力。我们实现了我们自己的 FlashAttention (Dao et al., 2022) 版本,以提高自注意力层的内存使用和速度。我们的版本在所考虑的所有情况下都与原始版本相当或更好,同时涵盖了更多的用例和硬件。由于 GPU 硬件细节,当每个头的嵌入维度为 64 的倍数时,效率最好,当完整的嵌入维度为 256 的倍数时,矩阵操作甚至更好。因此,我们的 ViT-g 架构与 Zhai 等人提出的架构略有不同。 (2022)为了最大限度地提高计算效率,我们使用 1536 的嵌入维度,24 个头(64 个暗/头),而不是 1408 个头(88 个暗/头)。我们的实验在最终准确度上没有显着差异,我们的 ViT-g 主干计算 1.1B 参数。
序列打包。DINO算法需要同时处理大尺寸裁剪图像(分辨率为224)和小尺寸裁剪图像(分辨率为98)。当这些图像被分割成块时,这两组图像会表示为长度不同的序列,因此不能一起进行前向传播。为了加速训练,我们使用了一种称为“序列打包”的技巧,这一技巧源自自然语言处理(NLP)领域(Krell等人,2022)。其想法很简单:我们将必须通过Transformer传播的序列拼接成一个长序列。然后,我们像往常一样将这个序列通过Transformer块。然而,在注意力层的自注意力矩阵中应用了一个块对角线掩码,防止不同序列之间的注意力。这样一来,前向传播就严格等同于分别对每个序列进行前向传播。与之前的实现相比,这种方法在计算效率上带来了显著的提升,因为之前的方法需要分别进行前向和反向传播。我们设置中的底层组件可以在xFormers库2中找到(Lefaudeux等人,2022)。
高效的随机深度。我们实现了一个改进的随机深度版本(Huang et al., 2016),它跳过删除残差的计算,而不是屏蔽结果。由于特定的融合内核,这以大约等于丢弃率的比例节省了内存和计算。在高下降率(本工作中 d = 40%)的情况下,这允许显着提高计算效率和内存使用。该实现包括随机打乱批次维度上的 B 个样本,并将第一个 (1 - d) × B 样本切片以进行块中的计算。
全硬数据并行 (FSDP)。使用AdamW优化器最小化我们的目标需要4个模型副本,以float32精度-学生、教师、优化器第一矩、优化器第二矩。这总和为十亿参数模型(例如我们的 ViT-g)的 16 GB 内存。为了减少每个 GPU 的这种内存占用,我们在 GPU 上拆分模型副本,即使用 FSDP 的 PyTorch 实现跨 GPU 分片 16 GB。因此,模型大小不受单个 GPU 的内存的限制,而是受计算节点跨 GPU 内存的总和的限制。FSDP 的 Pytorch 实现带来了第二个优势,即节省跨 GPU 通信成本:权重分片存储在优化器所需的 float32 精度中,但广播权重和减少梯度是在主干的 float16 精度完成的(MLP 头梯度在 float32 中减少以避免训练不稳定)。与 DistributedDataParallel (DDP) 中使用的 float32 梯度 all-reduce 操作相比,这导致通信成本降低了大约 50%,这用于其他自我监督预训练方法(Caron 等人,2021;Zhou 等人,2022a)。因此,当缩放 GPU 节点的数量时,训练过程比具有 float16 autocast 的 DDP 更有效地扩展。总体而言,Pytorch-FSDP 混合精度在我们遇到的几乎所有情况下都优于带有自动广播的 DDP。
模型蒸馏。我们对训练循环的大部分技术改进旨在改进大量数据上训练大型模型。对于较小的模型,我们从最大的模型 ViT-g 中提取它们,而不是从头开始训练它们。知识蒸馏 (Hinton et al., 2014) 旨在通过最小化一组给定输入的两个输出之间的一些距离来再现具有较小模型的大型模型的输出。由于我们的目标函数是从教师网络到学生网络的一种蒸馏形式,我们利用相同的训练循环,但也有一些例外:我们使用更大的模型作为冻结教师,保留我们使用的学生备用 EMA 作为我们的最终模型,去除掩蔽和随机深度,并将 iBOT 损失应用于两个全局作物。在我们的消融中,我们观察到这种方法比从头开始训练取得了更好的性能,即使对于 ViT-L。我们的蒸馏方法最终接近 Duval 等人描述的方法。 (2023),只是我们没有修改蒸馏损失项并评估学生的 EMA。

















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









