








前提
1.安装好hadoop(必要)
2.安装好zookeeper(非必要)
3.安装好mysql(必要,因为我们题目需要mysql数据库)
子任务三:Hive安装配置
本任务需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 从宿主机/opt目录下将文件apache-hive-2.3.4-bin.tar.gz、mysql-connector-java-5.1.47.jar,制到容器master中的/opt/software路径中(若路径不存在,则需新建),将容器master节点Hive安装包解压到/opt/module目录下,将命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
tar --no-same-owner -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
- 设置Hive环境变量,并使环境变量生效,执行命令hive --version并将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
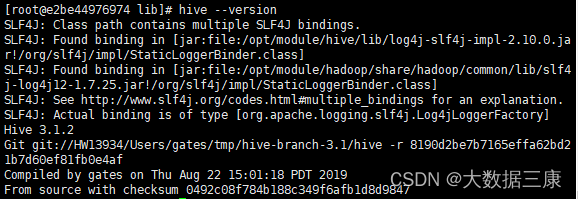
- 完成相关配置并添加所依赖包,将MySQL数据库作为Hive元数据库。初始化Hive元数据,并通过schematool相关命令执行初始化,将初始化结果截图(范围为命令执行结束的最后10行)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
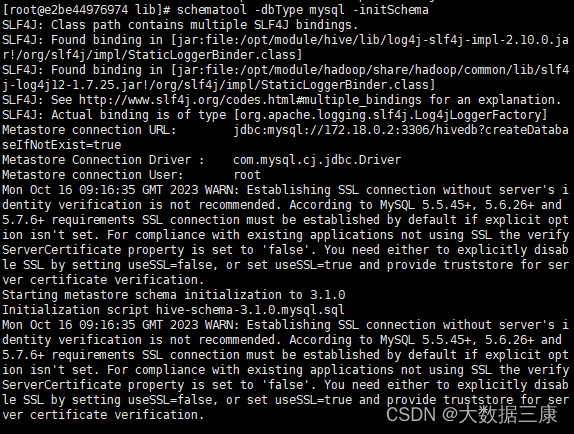
由于吾电脑卡顿了一下,最终格式化结果有些分离,就全部截图了,自己做题时只需要截图最后十行。
一、上传压缩包并解压重命名
- 将安装包上传到容器的software目录下
docker cp ./apache-hive-3.1.2-bin.tar.gz hadoop1:/opt/software/
- 解压
#安装包在software目录下,进入该目录进行解压:
cd /opt/software
第一问答案:
#解压到/opt/module目录下
tar --no-same-owner -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
- 重命名
mv /opt/module/apache-hive-3.1.2-bin /opt/module/hive
二、配置环境变量
1、修改环境变量
vi /etc/profile
内容应修改如下:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
2、重新加载环境变量
source /etc/profile
第二问答案:
3、查看版本号
hive --version
三、修改配置
1.hive-site.xml
# 进入配置目录
cd /opt/module/hive/conf
# 新增或修改hive-site.xml(一般是需要新增)
vi hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/module/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.db.type</name>
<value>mysql</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.18.0.2:3306/hivedb?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>关闭schema验证</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>提示当前数据库名</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>查询输出时带列名一起输出</description>
</property>
</configuration>
2.在lib下面添加mysql的驱动
#在docker容器外执行
docker cp ./mysql-connector-java-8.0.16.jar hadoop1:/opt/module/hive/lib
3. 初始化hive元数据
schematool -dbType mysql -initSchema
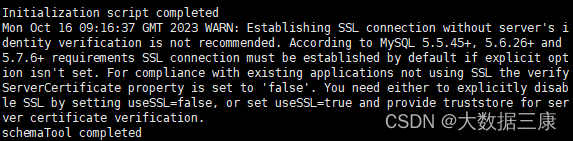
如果出现如下结果,即表示初始化成功
第三问答案:
备注:如果出现如下报错:
[root@e2be44976974 conf]# schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive/lib/log4j-slf4j-impl-
2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop/share/hadoop/common/lib/slf4j-
log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError:
com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object ;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:
1257)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.(JobConf.java:430)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
解决方法:
#删除hive中的guava依赖
cd /opt/module/hive/lib
rm -rf guava-19.0.jar
#使用hadoop中的guava依赖
cd /opt/module/hadoop/share/hadoop/common/lib
cp guava-27.0-jre.jar /opt/module/hive/lib/
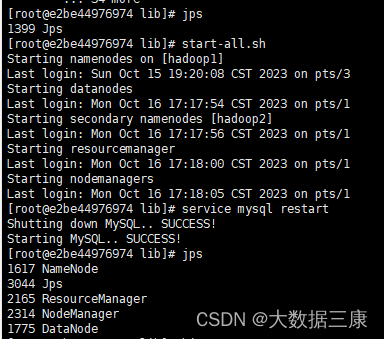
4.启动hive
# 三台容器上分别启动zookeeper
zkServer.sh start
#启动hadoop
start-all.sh
#启动mysql
service mysql start
#进入hive客户端
Hive
出现如下结果,即表示hive安装完成可以正常使用
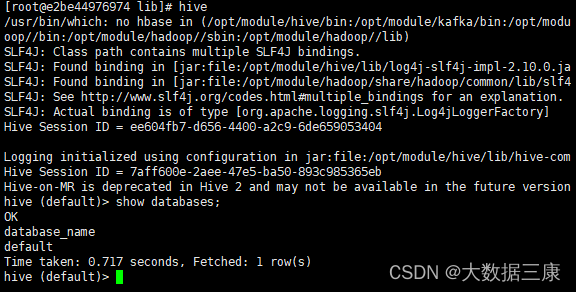
有关报错,列举两项
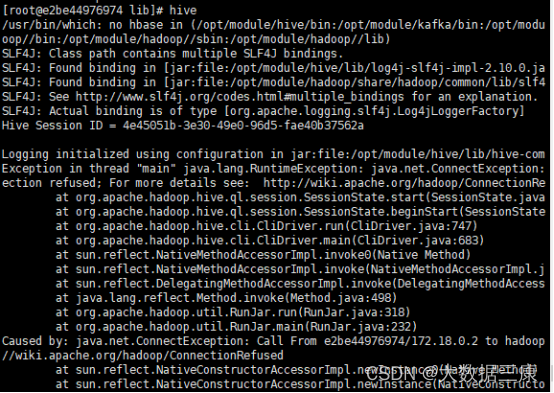
基本是因为hadoop和mysql没起来或这二者有问题。
















 3588
3588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









