







今天做python爬虫时,之前可以爬取的网站网址显示:
![]()
爬取内容为空。
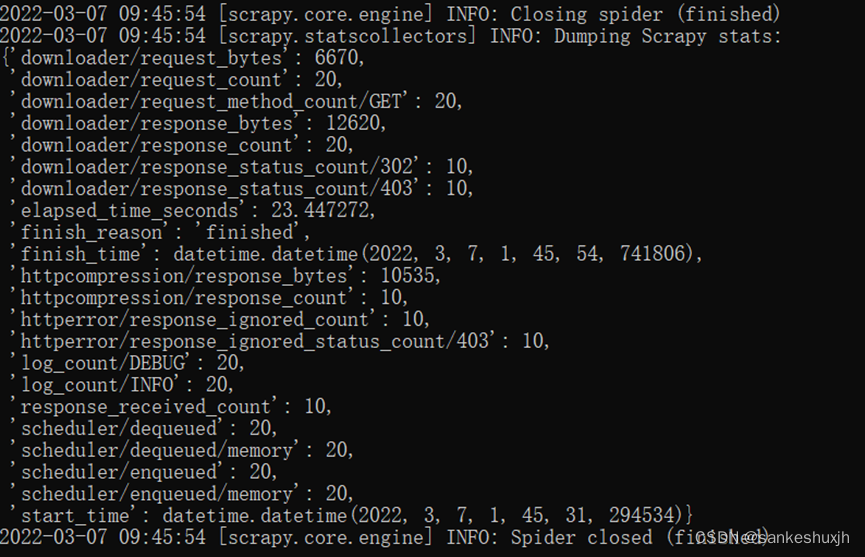
依次查找问题:
(1)INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
报错提示Scrapy爬虫没有任何数据返回,需要修改settings.py设置文件中的ROBOTST_OBEY,将其默认值True改为False。
(2)[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302)
检查代码是,已经使用了 User-Agent,并且源连接直接在浏览器打开并不跳转,使用requests测试,发现并没有被重定向。搜索很久无果,然后开始检查 [scrapy.downloadermiddlewares.redirect] DEBUG,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











