







原文作者:马同学
原文地址:最小二乘法的本质是什么?
最小平方法是十九世纪统计学的主题曲。从许多方面来看,它之于统计学就相当于十八世纪的微积分之于数学。
---史蒂芬-史蒂格勒《The History of Statics》
目录
一、日用而不知
来看一个生活中的例子,比如有5把尺子,如下图所示:

用他们分别测量一线段的长度,得到的数值分别为(颜色指不同的尺子):
| 长度 | |
|---|---|
| 红 | 10.2 |
| 蓝 | 10.3 |
| 橙 | 9.8 |
| 黄 | 9.9 |
| 绿 | 9.8 |
之所以出现的不同的值,可能因为:
- 不同厂家生产的尺子,精度不同
- 材质不同,热胀冷缩不一样
- 测量的时候心情起伏不定
- 。。。。
总之就是有误差,这种情况下,一般取平均值来作为线段的长度:

日常中就是这么使用的,可是作为很事er的数学爱好者,自然要想下:
- 这样做有道理么?
- 用调和平均数行不行?
- 用中位数行不行?
- 用几何平均数行不行?
二、最小二乘法
换一种思路来思考刚才的问题,首先把测试得到的值画在笛卡尔坐标系中,分别记做yi:

首先,要把猜测的线段长度的真实值用平行于横轴的直线来表示,因为是猜测的,所以用虚线画,记做y:

每个点都向y做垂线,垂线的长度就是|y-yi|,也可以理解为测量值和真实值之间的误差:

因为误差是长度还要取绝对值,计算起来麻烦,就干脆用平方来代表误差:

误差的平方和就是:

因为y是猜测的,可以不断变化:

自然误差的平方和是不断变化的,

法国数学家,阿德里安-马里·勒让德提出让总的误差的平方最小的y值就是真值,这是基于,如果误差是随机的,应该围绕真值上下波动,(关于这点可以看下如何理解无偏估计)。勒让德的想法变成代数式就是:

这个猜想也蛮符合直觉的,来算一下。这是一个二次函数,对其求导,导数为0的时候取得最小值:

正好是算数平均数。原来算数平均数可以让误差最小啊,这样看来选用它显得讲道理了。以下这种方法就是最小二乘法,所谓二乘就是平方的意思,台湾直接翻译为最小平方法

三、推广
算数平均数只是最小二乘法的特例,适用范围比较狭窄,而最小二乘法用途就比较广泛。比如温度与冰淇淋的销量:

看上去像某种线性关系:

可以假设这种线性关系为:

通过最小二乘法的思想:

上图的i、y、x分别为:

总的误差平方为:

不同的a、b会导致不同的误差平方,根据多元微积分的知识,当:

这个时候误差平方取最小值。对于a、b而言,上述方程组为线性方程组,用之前的数据解出来,

也就是这跟直线:

其实还可以假设:

在这个假设下,可以根据最小二乘法,算出a、b、c,得到下面这个红色的曲线:

同一组数据,选择不同的f(x),通过最小二乘法可以得到不一样的拟合曲线:

不同的数据,更可以选择不同的f(x),通过最小二乘法可以得到不一样的拟合曲线:

f(x)也不能选择任意的函数,还是有一些讲究的,这里就不介绍了。
四、最小二乘法与正太分布
我们对勒让德的猜测,即最小二乘法,仍然抱有怀疑,万一这个猜测是错误的怎么办?

数学王子高斯也想我们一样持有怀疑,高斯换了一个思考框架,通过统计论那一套来思考
五、skleran的LR模型使用
LinearRegression 拟合一个带有系数 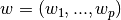 的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的误差平方和最小。其数学表达式为:
的线性模型,使得数据集实际观测数据和预测数据(估计值)之间的误差平方和最小。其数学表达式为:
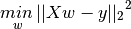
LinearRegression 会调用 fit 方法来拟合数组(x,y),并且将线性模型的系数 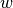 存储在其成员变量
存储在其成员变量 coef_ 中:
>>> from sklearn import linear_model
>>> reg = linear_model.LinearRegression()
>>> reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
>>> reg.coef_
array([ 0.5, 0.5])
然而,对于最小二乘的系数估计问题,其依赖于模型各项的相互独立性。当各项是相关的,且设计矩阵 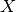 的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。
的各列近似线性相关,那么,设计矩阵会趋向于奇异矩阵,这会导致最小二乘估计对于随机误差非常敏感,产生很大的方差。例如,在没有实验设计的情况下收集到的数据,这种多重共线性(multicollinearity)的情况可能真的会出现。















 3370
3370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









