







在一个基于SOA架构的分布式系统体系中,服务(Service)成为了基本的功能提供单元,无论与业务流程无关的基础功能,还是具体的业务逻辑,均实现在相应的服务之中。服务对外提供统一的接口,服务之间采用标准的通信方式进行交互,各个单一的服务精又有效的组合、编排成为一个有机的整体。在这样一个分布式系统中某个活动(Activity)的实现往往需要跨越单个服务的边界,如何协调多个服务之间的关系使之为活动功能的实现服务,涉及到SOA一个重要的课题:服务协作(Service Coordination)。而具体来讲,一个分布式的活动可能会执行几秒钟,比如银行转帐;也可能执行几分钟、几个小时、几天甚至更长,比如移民局处理移民的申请。事务,无疑是属于短暂运行服务协作(Short-Running Service Coordination)的范畴。
一、 什么是事务(Transaction)
事务提供一种机制将一个活动涉及的所有操作纳入到一个不可分割的执行单元,组成事务的所有操作只有在所有操作均能正常执行的情况下方能提交,只要其中任一操作执行失败,都将导致整个事务的回滚。简单地说,事务提供一种“要么什么都不做,要么做全套(All or Nothing)”机制。事务具有如下四个属性,根据其首字母,我们一般将其称为事务的ACID四大属性:
. 原子性(Atomicity):“原子”这个词的本义就是不可分割的意思,事务的原子性的含义是:一个事务的所有操作被捆绑成一个整体,所有的操作要么全部执行,要么都不执行;
. 一致性(Consistence):事务的原子性确保一个事务不会破环数据的一致性,如果事务成功提交,数据的状态是组成事务的所有操作按照事先编排的方式执行的结果,数据状态具有一致性;如果事务任何一个中间步骤出错,整个事务回滚并将数据回复到原来的状态,数据状态仍然具有一致性。所以,事务只会将数据状态从一个一致性状态转换到另一个一致性状态;
. 隔离性(Isolation):从事务的外部来看,事务的一致性实现了数据在两个一致性状态之间的转换,但是从事务内部来看,组成事务的各个操作是按照一定的逻辑顺序执行的,所以数据具有位于两个一致性状态的“中间状态”。但是,这种中间状态被隔离于事务内部,对于事务外部是不可见的;
?持久性(Durability):持久性的意思是一旦成功提交,基于持久化资源(比如数据库)的数据将会被持久化,对数据的改变是永久性的。
事务最初来源于数据库管理系统(DBMS),反映的是对存储于数据库中的数据操作。除了主流的关系型数据库管理系统,比如SQL Server,Oracle和DB2等提供对事务的支持,基于事务的数据操作方式也可以应用到其他一些数据存储资源,比如MSMQ。自Windows Vista开始将文件系统(NTFS)以至于注册表纳入了事务型资源(Transactional Resource)的范畴。
二、 事务的显式控制
虽然事务型资源家族成员越来越多,但是不可否认的是,数据库还是我们使用频率最高的事务型资源。对于稍微有一定经验的开发人员,应该都在存储过程(Stored Procedure)中编写过基于事务的SQL,或者编写过基于ADO.NET事务的代码,对事务的进一步介绍就从这里说起。
1、SQL中的事务处理
无论是基于SQL Server的T-SQL,抑或是基于Oracle的PL-SQL都对事务提供了原生的支持,有意思的是T-SQL中的T本身指的就是事务(Transaction)。以T-SQL为例,我们可以通过如下三个SQL语句实现事务的启动、提交与回滚:
. BEGIN TRANSACTION: 开始一个事务;
. COMMIT TRANSACTION:提交所有位于BEGIN TRANSACTION和COMMIT TRANSACTION之间的操作;
. ROLLBACK TRANSACTION:回滚所有位于BEGIN TRANSACTION和COMMIT TRANSACTION之间的操作。
我们举一个很典型的基于事务型操作的例子:银行转帐,而且这个例子将会贯穿于本章的始终。为此,我们先创建一个最为简单的用于存储帐户的数据表:T_ACCOUNT,整个表近仅仅包括三个字段(ID、NAME和BALANCE),它们分别代表银行帐号的ID、名称和余额。创建该表的T-SQL如下
1: CREATE TABLE [dbo].[T_ACCOUNT](
2: [ID] VARCHAR(50) PRIMARY KEY,
3: [NAME] NVARCHAR(50) NOT NULL,
4: [BALANCE] FLOAT NOT NULL)
5: GO
银行转帐是一个简单的复合型操作,由两个基本的操作构成:存储和提取,即从一个帐户中提取相应金额出入另一个帐户。对数据完整性的要求是我们必须将这两个单一的操作纳入同一个事务。如果我们通过一个存储过程来完成整个转帐的流程,具体的SQL应该采用下面的写法:
1: CREATEProcedure P_TRANSFER
2: (
3: @fromAccount VARCHAR(50),
4: @toAccount VARCHAR(50),
5: @amount FLOAT
6: )
7: AS
8:
9: --确保帐户存在性
10: IF NOT EXISTS(SELECT * FROM [dbo].[T_ACCOUNT] WHERE ID = @fromAccount)
11: BEGIN
12: RAISERROR ('AccountNotExists',16,1)
13: RETURN
14: END
15: IF NOT EXISTS(SELECT * FROM [dbo].[T_ACCOUNT] WHERE ID = @toAccount)
16: BEGIN
17: RAISERROR ('AccountNotExists',16,1)
18: RETURN
19: END
20: --确保余额充足性
21: IF NOT EXISTS(SELECT * FROM [dbo].[T_ACCOUNT] WHERE ID = @fromAccount AND BALANCE >= @amount)
22: BEGIN
23: RAISERROR ('LackofBalance',16,1)
24: RETURN
25: END
26: --转帐
27: BEGIN TRANSACTION
28: UPDATE [dbo].[T_ACCOUNT] SET BALANCE = BALANCE - @amount WHERE ID = @fromAccount
29: IF @@ERROR <> 0
30: BEGIN
31: ROLLBACK TRANSACTION
32: END
33: UPDATE [dbo].[T_ACCOUNT] SET BALANCE = BALANCE + @amount WHERE ID = @toAccount
34: IF @@ERROR <> 0
35: BEGIN
36: ROLLBACK TRANSACTION
37: END
38: COMMIT TRANSACTION
39: GO
2、 ADO.NET事务控制
无论是T-SQL,还是PL-SQL,抑或是其他数据库管理系统对标准SQL的扩展,不仅仅是提供基于标准SQL的DDL(Data Definition Language)和DML(Data Manipulation Language),还提供了对函数、存储过程和流程控制的支持。SQL Server至2005起,甚至实现了与CLR(Common Language Runtime)的集成,使开发人员可以使用任何一种.NET语言编写编写函数或者存储过程。毫无夸张地说,你可以通过SQL实现任何业务逻辑。
但是,在大多数情况我们并不这么做,我们更多地还是将SQL作为最基本的数据操作语言在使用。对于.NET开发者来说,我们还是习惯将复杂的逻辑和流程控制实现在通过C#或者VB.NET这样的面相对象编程语言编写的程序中。究其原因,我觉得主要有两点:
- 面相对象的语言更能容易地实现复杂的逻辑:较之SQL这种基于集合记录的语言,面相对象的语言更加接近于我们真实的世界,通过面相对象的方式模拟具体的逻辑更加贴近于人类的思维方式。此外,通过面相对语言本身的一些特性,我们可以更加容易地应用各种设计模式和思想;
- 将太多逻辑运算的执行放在数据库中不利于应用的扩展:从部属的角度来讲,数据操作运算负载到具体的服务器中,以一个典型的分布式Web应用为例,Web服务器(承载Web应用)、应用服务器(承载各种服务)和数据库服务器均可以承载最终对逻辑的运算。但是,从可扩展性(或者可伸缩性)上考虑,将主要的计算放在前两者比放在数据库更具优势。如果我们将密集的运算(这种运算需要占用更多的CPU时间和内存)迁移到Web服务器或者应用服务器,我们可以通过负载均衡(Load Balance)将其分流到多台服务器上面,这个服务器机群可以根据负载情况进行动态地配置。但是,数据库服务器对负载均衡的支持就不那么容易。
正因为如此,对于事务的控制,较之采用SQL的实现方式,我们使用得最多的还是采用基于面相对象语言编程的方式。对于.NET开发人员,我们可以直接利用ADO.NET将基于单个数据库连接的多个操作纳入同一个事务之中。同样以上面的银行转帐事务为例,这次我们将整个转帐作为一个服务(BankingService)的一个操作(Transfer)。下面的代码通过一种与具体数据库类型无关的ADO.NET编程模式实现了整个银行转帐操作,最终的转帐通过调用一个存储过程实现;
1: publicclass BankingService : IBankingService
2: {
3: //其他操作
4: public void Transfer(string fromAccountId, string toAccountId, double amount)
5: {
6: string connectionStringName = "BankingDb";
7: string connectionString = ConfigurationManager.ConnectionStrings[connectionStringName].ConnectionString;
8: string providerName = ConfigurationManager.ConnectionStrings[connectionStringName].ProviderName;
9: DbProviderFactory dbProviderFactory = DbProviderFactories.GetFactory(providerName);
10: using (DbConnection connection = dbProviderFactory.CreateConnection())
11: {
12: connection.ConnectionString = connectionString;
13: DbCommand command = connection.CreateCommand();
14: command.CommandText = "P_TRANSFER";
15: command.CommandType = CommandType.StoredProcedure;
16:
17: DbParameter parameter = dbProviderFactory.CreateParameter();
18: parameter.ParameterName = BuildParameterName("fromAccount");
19: parameter.Value = fromAccountId;
20: command.Parameters.Add(parameter);
21:
22: parameter = dbProviderFactory.CreateParameter();
23: parameter.ParameterName = BuildParameterName("toAccount");
24: parameter.Value = toAccountId;
25: command.Parameters.Add(parameter);
26:
27: parameter = dbProviderFactory.CreateParameter();
28: parameter.ParameterName = BuildParameterName("amount");
29: parameter.Value = amount;
30: command.Parameters.Add(parameter);
31:
32: connection.Open();
33: using (DbTransaction transaction = connection.BeginTransaction())
34: {
35: command.Transaction = transaction;
36: try
37: {
38: command.ExecuteNonQuery();
39: transaction.Commit();
40: }
41: catch
42: {
43: transaction.Rollback();
44: throw;
45: }
46: }
47: }
48: }
49: }
注:为了使上面一段代码能够同时用于不同的数据库类型,比如SQL Server和Oracle,我通过提取连接字符串配置中的数据库提供者(DbProvider)名称,借此创建相应的DbProviderFactory对象。所有ADO.NET对象,包括DbConnection、DbCommand、DbParameter以及DbTransaction均通过DbProviderFactory创建,所以并不和具体的数据库类型绑定在一起。此外,基于不同数据库类型的存储过程的参数命名各不相同,比如 SQL Server的参数会添加”@”前缀,为此我将对参数名称的解析实现在一个单独的方法(BuildParameterName)之中
3、事务的显式控制限定于对单一资源的访问
通过在SQL中进行事务的控制,只能将基于某一段SQL语句的操作纳入到一个单一的事务中;如果采用基于ADO.NET的数据控制,被纳入到同一个事务的操作仅仅限于某个数据库连接。换句话说,上面介绍的这两种对事务的显式控制仅仅限于对单一的本地资源的控制。
我们将事务的概念引入服务,倘若我们将一个单一的服务操作作为一个事务,如果采用上述的显式事务控制的方式,那么整个服务操作只能涉及一个单一的事务资源。服务于存取的资源关系如图1所以。
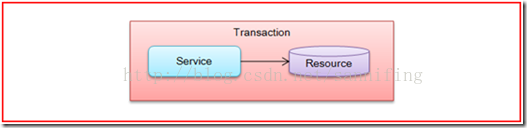
图1 本地事务对单一资源的控制
上述的这种基于某个服务单一本地资源的访问的事务,被称为本地事务(Local Transaction),在一个基于SOA分布式应用环境下,我们需要的同时能将多个资源、多个服务进行统一协作的分布式事务(Distributed Transaction)。接下来,我们来介绍几种典型的分布式事务应用的场景。
三、分布式事务(Distributed Transaction)应用场景
对于一个分布式事务(Distributed Transaction)来讲,事务的参与者分布于网络环境中的不同的节点。也就是说,我们可以将多个事务资源纳入到一个单一的事务之中,并且这些事务资源可以分布到不同的机器上。这些承载分布式资源的机器可能是出于同一个网络中,也可能处于不同的网络中。甚至说,某个事务资源本质上就是一个通过HTTP访问的单纯的Internet资源。
站在SOA的角度来看分布式事务,意味着将服务的某个服务操作视为一个单一的事务。该服务操作可能会访问不止一个事务资源(比如访问两个不同的数据库服务器),也可能调用另一个服务。下面介绍了三个典型的分布式事务应用场景,先从最简单的说起。
1、将对多个资源的访问纳入同一事务
第一个分布式事务应用场景最简单,即一个服务操作并不会调用另一个服务,但是服务操作涉及到对多个事务资源的访问。当一个服务操作访问不同的数据库服务器,比如两台SQL Server,或者一台SQL Server和一台Oracle Server;当一个服务操作访问的是相同数据库,但是相应的数据库访问时基于不同的数据连接;当一个服务操作处理访问数据库资源,还需要访问其他份数据库的事务资源,就需要采用分布式事务来对所有的事务参与者进行协作了。图2反映了这样的分布式应用场景。
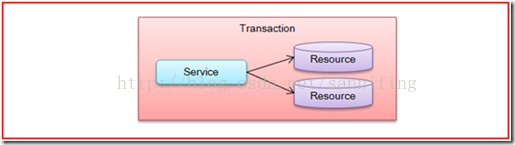
图2 单一服务对多个事务资源的访问
2、将对各个服务的调用纳入同一事务
对于上面介绍的分布式应用场景,尽管一个服务操作会访问多个事务资源,但是毕竟整个事务还是控制在单一的服务内部。如果一个服务操作需要调用另外一个服务,这是的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,以使被调用的服务访问的资源自动加入进来。图3反映了这样一个跨越多个服务的分布式事务。
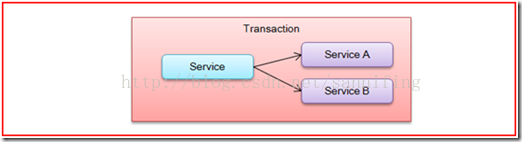
图3 跨越多个服务的事务
3、 将对多个资源和服务的访问纳入同一个事务
如果将上面这两种场景(一个服务可以调用多个事务资源,也可以调用其他服务)结合在一起,对此进行延伸,整个事务的参与者将会组成如图4所示的树形拓扑结构。在一个基于分布式事务的服务调用中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。
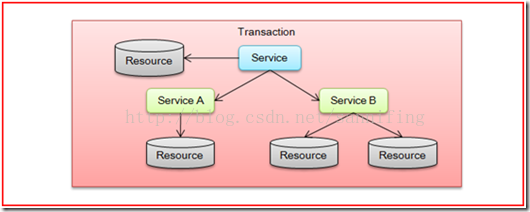
图4 基于SOA分布式事务拓扑结构
较之基于单一资源访问的本地事务,分布式事务的实现机制要复杂得多。Windows平台提供了基于DTC分布式事务基础架构。
作者:Artech出处:http://artech.cnblogs.com本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









