







前言
国庆的时候,为了理解DexDiff算法,花了几天时间研究了下Dex的文件结构,算是有个整体的把握,这篇文章是在姜维的 《Android逆向之旅—解析编译之后的Dex文件格式》基础上,自己对Dex格式的理解,以防忘记,做一次备忘。在理解Dex文件格式之前,需要了解两个概念:
- 字节序
- LEB128格式
相关链接
字节序
如果将值为0x12345678的32位整型从地址0x00000000开始保存,那么是如何存储的呢,有两种情况:
| 地址偏移 | 大端存储 | 小端存储 |
|---|---|---|
| 0x00000000 | 0x12 | 0x78 |
| 0x00000001 | 0x34 | 0x56 |
| 0x00000002 | 0x56 | 0x34 |
| 0x00000003 | 0x78 | 0x12 |
从上表中看到:
- 如果使用大端存储:较高的有效字节(0x12)存放在较低的存储器地址(0x00000000),较低的有效字节(0x78)存放在较高的存储器地址(0x00000003)。
- 如果使用小端存储:较高的有效字节(0x12)存放在较高的的存储器地址(0x00000003),较低的有效字节(0x78)存放在较低的存储器地址(0x00000000)。
而Dex文件格式中有一项是大小端标记,其真实值为0x12345678,但是它在文件中存储为0x78563412,因此Dex是典型的小端存储。
LEB128格式
LEB 128是一种基于1个字节的不定长度的编码方式 。如果第一个字节的最高位为1,则表示还需要下一个字节来继续补充描述 ,直到最后一个字节的最高位为0 。这种编码方式主要为了解决内存的浪费问题,当表示一个int类型的值时,最少只需要1个字节,最多需要5个字节进行表示。
那么问题来了,如果我们用正常方式来存储值为131的int类型,则需要整整4个字节,即0b 00000000 00000000 00000000 10000011 ,可以看到高3位都是无效位,浪费内存。这时候如果用LEB128编码进行存储,则可以表示为
10000011 00000001可以看到,只需要2个字节就可以表示131。那么如何对上面的编码进行解码呢?
- 初始化result=0,n=0,每操作完一个字节对n进行递增。
- 循环开始,读取一个字节
- 去除该字节最高位
- 将其余字节左移7*n位 ,然后与result进行或运算连接
- 递增n
- 判断当前字节最高位是否是1且n是否小于5,如果是的话,回到第二步继续循环,直到最高位是0或者n>=5终止循环。
- 这时候的result就是最终的值。
我们按照以上流程对10000011 00000001进行解码。
- 读一个字节字节,得到10000011,去除最高位得到0000011,左移7*n位,此时n=0,无需左移,与result进行或运算,得到result=0000011
- 递增n,此时n=1
- 10000011的最高位是1,并且n<5,继续循环读取一个字节,得到00000001
- 去除最高位得到0000001,左移7*n位,此时n=1,左移7位,得到00000010000000,与result进行或运算连接,得到result=00000010000011
- 递增n,此时n=2
- 00000001的最高位是0,终止循环。
- 此时result=00000010000011,去除高位无效位后得到result=10000011,转换为10进制就是131.
那么代码里如何对LEB128编码格式进行解码呢。简单地看下aosp的实现。
public static int readUnsignedLeb128(Buffer in) {
int result = 0;
int cur;
int count = 0;
do {
byte b = in.readByte();//读取一个字节
cur = b & 0xff; //该字节与0b11111111进行与操作,得到的应该还是其本身,这一步操作是否必要? 为了对齐8位?
result |= (cur & 0x7f) << (count * 7); //该字节与0b0111111进行与操作,去除最高位,然后左移7*count位数,与result进行或运算连接,左移是因为是小端存储
count++;
} while (((cur & 0x80) == 0x80) && count < 5);//与0b10000000,最高位是1并且小于5个字节则一直循环
//10000 0000 是非法的LEB128序列,0用00000000表示
if ((cur & 0x80) == 0x80) {
throw new DexException("invalid LEB128 sequence");
}
return result;
}构造解析文件
在解析文件格式之前,需要构造一个Dex,这个Dex我们以最简单为主。
新建一个新的类Hello.java,假设该文件位于$Test目录下。
public class Hello{
public static void main(String[] args){
System.out.println("Hello world!");
}
}进入$Test 目录,将源码编译成class文件。
javac Hello.java -source 1.7 -target 1.7通过dx命令将class转为dex文件,dx命令位于 $AndroidSDK/build-tools/$version/dx下
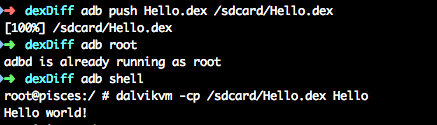
dx --dex --output=Hello.dex Hello.class当然我们可以直接在手机上运行该dex,通过adb push该dex到手机上直接运行,用dalvikvm运行,dalvikvm 会在 /data/dalvik-cache/ 目录下创建 .dex 文件 ,因此要求 ADB 执行 Shell时 对目录 /data/dalvik-cache/ 有读、写和执行的权限,因此要求手机是root的,或者用模拟器。
adb push Hellp.dex /sdcard/Hello.dex
adb root
adb shell
dalvikvm -cp /sdcard/Hello.dex Hello 效果如下,可以看到输出了Hello world!
用Beyond Compare打开,得到如图内容

具体二进制内容如下
6465780A30333500B25DC890C98FC9101D7A1C391CB10CEDF77CD758725E91ACE002000070000000785634120000000000000000400200000E0000007000000007000000A800000003000000C400000001000000E800000004000000F00000000100000010010000B001000030010000760100007E0100008C01000098010000A1010000B8010000CC010000E0010000F4010000F7010000FB01000010020000160200001B0200000300000004000000050000000600000007000000080000000A000000080000000500000000000000090000000500000068010000090000000500000070010000040001000C0000000000000000000000000002000B000000010001000D00000002000000000000000000000001000000020000000000000002000000000000003002000000000000010001000100000024020000040000007010030000000E0003000100020000002902000008000000620000001A0101006E20020010000E000100000003000000010000000600063C696E69743E000C48656C6C6F20776F726C6421000A48656C6C6F2E6A61766100074C48656C6C6F3B00154C6A6176612F696F2F5072696E7453747265616D3B00124C6A6176612F6C616E672F4F626A6563743B00124C6A6176612F6C616E672F537472696E673B00124C6A6176612F6C616E672F53797374656D3B0001560002564C00135B4C6A6176612F6C616E672F537472696E673B00046D61696E00036F757400077072696E746C6E000100070E00030100070E78000000020000818004B0020109C80200000D000000000000000100000000000000010000000E000000700000000200000007000000A80000000300000003000000C40000000400000001000000E80000000500000004000000F0000000060000000100000010010000012000000200000030010000011000000200000068010000022000000E00000076010000032000000200000024020000002000000100000030020000001000000100000040020000得到了这个Dex文件后我们就可以开始解析了。
Dex 文件结构解析
Dex文件头由下表组成
| 偏移地址 | 字节大小 | 备注 |
|---|---|---|
| 0x00 | 8 | Magic,Dex文件魔数,值为 “dex\n035\0”或”dex\n037\0” |
| 0x08 | 4 | Checksum,使用alder32算法校验文件除去 maigc ,checksum 外余下的所有文件区域 |
| 0x0C | 20 | Signature,使用 SHA-1 算法 hash 除去 magic ,checksum 和 signature 外余下的所有文件区域 |
| 0x20 | 4 | File Size,Dex文件大小 |
| 0x24 | 4 | Header Size,Dex文件头大小,一般目前是0x70 |
| 0x28 | 4 | Endian Tag,大小端标记,值为0x12345678,由于Dex是小端存储,所以Dex文件中保存为0x78563412 |
| 0x2C | 4 | Link Size,链接数据的大小 |
| 0x30 | 4 | Link Off ,链接数据的偏移 |
| 0x34 | 4 | Map Off,Map Item 的偏移地址,后面细说 |
| 0x38 | 4 | String Ids Size ,所有用到的字符串大小 |
| 0x3C | 4 | String Ids Off,所有用到的字符串偏移 |
| 0x40 | 4 | Type Ids Size,Dex中类型数据结构的大小 |
| 0x44 | 4 | Type Ids Off,Dex中类型数据结构的偏移 |
| 0x48 | 4 | Proto Ids Size,Dex中元数据信息数据结构的大小 |
| 0x4C | 4 | Proto Ids Off,Dex中元数据信息数据结构的偏移 |
| 0x50 | 4 | Field Ids Size,Dex中字段信息数据结构的大小 |
| 0x54 | 4 | Field Ids Off,Dex中字段信息数据结构的偏移 |
| 0x58 | 4 | Method Ids Size,Dex中方法信息数据结构的大小 |
| 0x5C | 4 | Method Ids Off,Dex中方法信息数据结构的偏移 |
| 0x60 | 4 | Class Defs Size,Dex中类信息数据结构的大小 |
| 0x64 | 4 | Class Defs Off,Dex中类信息数据结构的偏移 |
| 0x68 | 4 | Data Size,Dex中数据区域的大小 |
| 0x6C | 4 | Data Off,Dex中数据区域的偏移 |
有了上面这张表,接下来我们对刚才编译出来的Dex文件进行解析。为了便于输出一些内容,这里使用Okio读取Dex文件。引入依赖:
compile 'com.squareup.okio:okio:1.11.0'约定全局静态常量File类型的DEX指向刚才的Dex文件
private static final File DEX = new File("path/to/Hello.dex");读取魔数
魔数占8个字节,读取开始地址的8个字节即为魔数。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
//8个字节
byte[] bytes = bufferedSource.readByteArray(8);
Buffer buffer = new Buffer();
buffer.write(bytes);
ByteString byteString = buffer.readByteString();
//输出16进制
Logger.e(TAG, "magic hex: %s", byteString.hex());
//输出文本内容
Logger.e(TAG, "magic string: %s", byteString.utf8());输出结果:

可以看到,我们这个Dex的魔数值为dex\n035\0
读取CheckSum
CheckSum 占4个字节,继魔数后读取4个字节即可。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
//忽略魔数8个字节
bufferedSource.skip(8);
//4个字节
byte[] bytes = bufferedSource.readByteArray(4);
Buffer buffer = new Buffer();
buffer.write(bytes);
ByteString byteString = buffer.readByteString();
//输出16进制
Logger.e(TAG, "CheckSum hex: %s", byteString.hex());输出结果:

这个值是如何计算而来的呢,其实就是Dex文件除了魔数和checksum的8+4个字节外的其他字节的adler32的值。计算算法如下:
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
Adler32 adler32 = new Adler32();
adler32.update(bufferedSource.readByteArray());
long value = adler32.getValue();
Buffer buffer = new Buffer();
buffer.writeIntLe((int) value);
ByteString byteString = buffer.readByteString();
Logger.e(TAG, "checksum hex: %s", byteString.hex());得到的结果和直接从Dex中读取的Checksum值是一样的。
读取Signature
Signature占的字节数比较大,有20个字节,读完Checksum后读取20个字节即Signature的值。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
//忽略魔数8个字节
bufferedSource.skip(8);
//忽略CheckSum 4个字节
bufferedSource.skip(4);
//20个字节
byte[] bytes = bufferedSource.readByteArray(20);
Buffer buffer = new Buffer();
buffer.write(bytes);
ByteString byteString = buffer.readByteString();
//输出16进制
Logger.e(TAG, "Signature hex: %s", byteString.hex());输出结果:

同理,这个值是如何计算而来的呢,其实就是Dex文件除了魔数、checksum和Signature的8+4+4个字节外的其他字节的SHA-1的值。计算算法如下:
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
Buffer buffer = new Buffer();
buffer.writeAll(bufferedSource);
ByteString signature = buffer.sha1();
Logger.e(TAG, "signature hex: %s", signature.hex());得到的结果和直接从Dex中读取的Signature值是一样的。
读取Dex文件大小
Dex文件大小占4个字节,读完Signature后读取4个字节即为值。
Logger.e(TAG, "file size from file: %s", DEX.length());
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
int readIntLe = bufferedSource.readIntLe();
Logger.e(TAG, "file size: %s", readIntLe);
Buffer fileBuffer = new Buffer();
fileBuffer.writeIntLe(readIntLe);
ByteString fileByteString = fileBuffer.readByteString();
Logger.e(TAG, "file size hex: %s", fileByteString);输出结果

可以看到直接读取Dex的File文件大小和直接读取Dex中二进制文件大小值是一样的。
这里需要注意一点,Dex是小端存储,所以读取short,int,long等数据类型,都需要调用readShortLe、readIntLe、readLongLe等方法还原原始数据。
读取Dex文件头大小
Dex文件头大小占4个字节,读完Dex文件大小后读取4个字节即为值。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
int readIntLe = bufferedSource.readIntLe();
Logger.e(TAG, "header size: %s", readIntLe);
Buffer buffer = new Buffer();
buffer.writeIntLe(readIntLe);
ByteString byteString = buffer.readByteString();
Logger.e(TAG, "header size hex: %s", byteString);输出结果:

读取Dex大小端标记
大小端标记位于Dex文件头后的4个字节,值为常量0x12345678,由于是Dex是小端存储,所以文件中存储为0x78563412,可以使用readIntLe方法还原为0x12345678常量。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
Buffer buffer = new Buffer();
//还原小端存储的原始数据
buffer.writeInt(bufferedSource.readIntLe());
ByteString byteString = buffer.readByteString();
Logger.e(TAG, "endian tag hex: %s", byteString);读取Link Size和Link Off
Link Size和Link Off各占4个字节,紧跟大小端标记后面。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
int readIntLe = bufferedSource.readIntLe();
Logger.e(TAG, "link size: %s", readIntLe);
Buffer buffer = new Buffer();
buffer.writeInt(readIntLe);
ByteString byteString = buffer.readByteString();
Logger.e(TAG, "link size hex: %s", byteString);
buffer.writeInt(bufferedSource.readIntLe());
byteString = buffer.readByteString();
Logger.e(TAG, "link off hex: %s", byteString);运行结果:

说明这个Dex没有link段内容。
读取Map off
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
Buffer buffer = new Buffer();
buffer.writeInt(bufferedSource.readIntLe());
ByteString byteString = buffer.readByteString();
Logger.e(TAG, "map off: %s", byteString);运行结果:
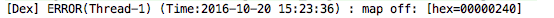
读取剩下的Dex文件头内容
剩下的Dex文件头都是成对存在的,分别是大小和偏移,有了上面的经验,这次我们直接读取整个文件头内容。
BufferedSource buffer = Okio.buffer(Okio.source(DEX));
byte[] bytes = null;
ByteString of = null;
bytes = buffer.readByteArray(8);
of = ByteString.of(bytes);
Logger.e(TAG, "magic: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "checksum: %s", of);
bytes = buffer.readByteArray(20);
of = ByteString.of(bytes);
Logger.e(TAG, "signature: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "file size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "header size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "endian_tag: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "link_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "link_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "map_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "string_ids_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "string_ids_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "type_ids_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "type_ids_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "proto_ids_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "proto_ids_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "field_ids_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "field_ids_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "method_ids_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "method_ids_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "class_defs_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "class_defs_off: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "data_size: %s", of);
bytes = buffer.readByteArray(4);
of = ByteString.of(bytes);
Logger.e(TAG, "data_off: %s", of);输出结果:
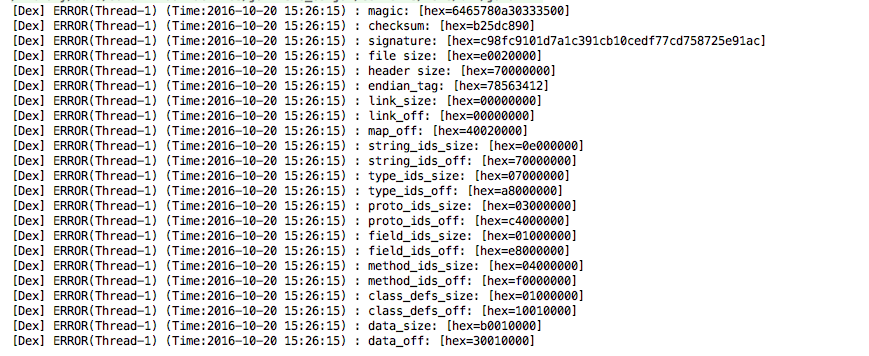
解析Map off中的内容
读取到Map off的偏移地址后,该地址指向的是一个map items数据结构区域,从该地址开始的4个字节是Map items的大小n,之后跟着n个map item数据结构,而map item则是由四部分组成,分别是short类型的type,short类型的unuse,int类型的size,int类型offset。而map off中所有的map item,其实是有一部分内容和Dex 文件头中定义的size和off是重复冗余的。
map items可以用以下两张表总结:
| 名称 | 数据类型 | 大小 |
|---|---|---|
| map items size | int | 4字节 |
| map item | n个map item | map item 数据结构大小*(map items size) |
map items的数据结构总结为:
| 名称 | 数据类型 | 大小 |
|---|---|---|
| type | short | 2字节 |
| unuse | short | 2字节 |
| size | int | 4字节 |
| offset | int | 4字节 |
type主要就是Dex文件头中的几个类型,可总结为下表
| type值 | type对应的数据结构 |
|---|---|
| 0x0000 | Header |
| 0x0001 | String Ids |
| 0x0002 | Type Ids |
| 0x0003 | Proto Ids |
| 0x0004 | Field Id |
| 0x0005 | Methos Ids |
| 0x0006 | Class Defs |
| 0x1000 | Map List |
| 0x1001 | Type Lists |
| 0x1002 | Annotation Set Ref Lists |
| 0x1003 | Annotation Sets |
| 0x2000 | Class Datas |
| 0x2001 | Codes |
| 0x2002 | StringDatas |
| 0x2003 | DebugInfos |
| 0x2004 | Annotations |
| 0x2005 | EncodedArrays |
| 0x2006 | AnnotationsDirectories |
接下来来读取map items中的数据结构
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
int readIntLe = bufferedSource.readIntLe();
Logger.e(TAG, "map off: %s", readIntLe);
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(readIntLe);
int mapSize = bufferedSource.readIntLe();
Logger.e(TAG, "map size: %s", mapSize);
for (int i = 0; i < mapSize; i++) {
short type = bufferedSource.readShortLe();
short unused = bufferedSource.readShortLe();
int size = bufferedSource.readIntLe();
int offset = bufferedSource.readIntLe();
Logger.e(TAG, "type:0x%04x", type);
Logger.e(TAG, "unused: %s", unused);
Logger.e(TAG, "size: %s", size);
Logger.e(TAG, "offset: %s", offset);
}输出结果:
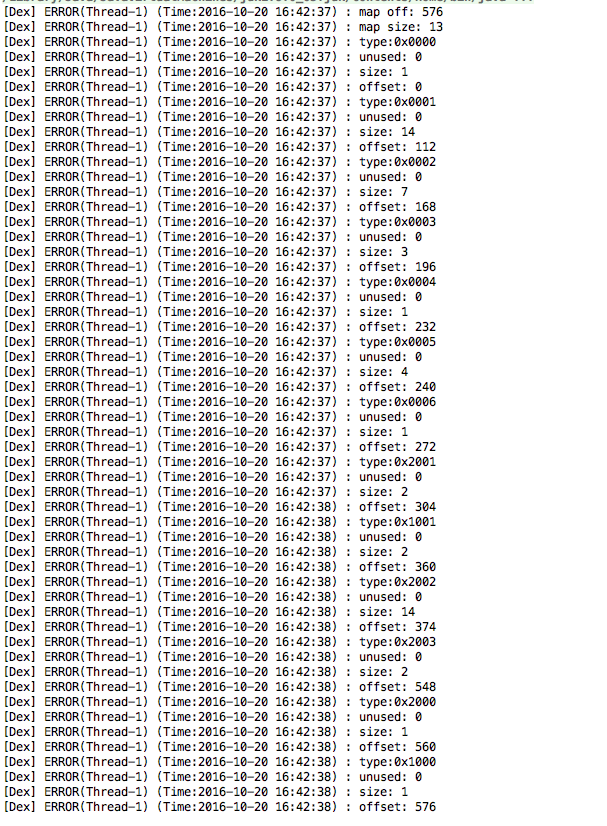
解析String Ids区中的内容
这个区域中的数据非常重要,里面存储了整个Dex会用到的字符串资源。该区域存储的是size个字符串索引,真正的字符串存在对应的索引上。读取这n个offset很简单,只需要将string ids size和string ids off读出来,然后从string ids off处开始读取string ids size个int型数据就可以了。
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
//获得string size
int size = bufferedSource.readIntLe();
//获得string off
int offset = bufferedSource.readIntLe();
//移动到offset处
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
//读取size个offset
List<Integer> list = new ArrayList<>();
Buffer buffer = new Buffer();
for (int i = 0; i < size; i++) {
int readIntLe = bufferedSource.readIntLe();
Logger.e(TAG, "offset:0x%08x", readIntLe);
list.add(readIntLe);
buffer.writeInt(readIntLe);
}输出结果
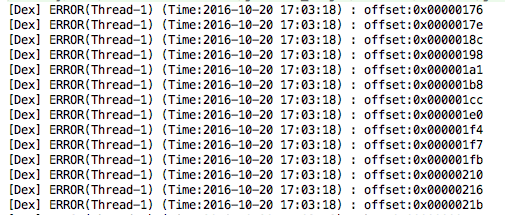
之后我们移动到第一个索引处开始读取真正的string,其数据结构为一个LEB 128编码的int型,之后跟着该int型的就是对应的字符串。因为后面会不断用到这些字符串,这里将其封装成函数。
public HashMap<Integer, String> getStringTable() throws IOException {
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
//获得string size
int size = bufferedSource.readIntLe();
//获得string off
int offset = bufferedSource.readIntLe();
//移动到offset处
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
//读取size个offset
List<Integer> list = new ArrayList<>();
Buffer buffer = new Buffer();
for (int i = 0; i < size; i++) {
int readIntLe = bufferedSource.readIntLe();
list.add(readIntLe);
buffer.writeInt(readIntLe);
}
//移动到第一个索引开始解析
int offset0 = list.get(0);
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset0);
buffer = new Buffer();
buffer.writeAll(bufferedSource);
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
for (int i = 0; i < list.size(); i++) {
//读LEB 128,表示字符串长度
int leb128 = readUnsignedLeb128(buffer);
//解析真正的字符串
String decode = decode(buffer, new char[leb128]);
hashMap.put(i, decode);
}
return hashMap;
}
public static int readUnsignedLeb128(Buffer in) {
int result = 0;
int cur;
int count = 0;
do {
byte b = in.readByte();//读取一个字节
cur = b & 0xff; //该字节与0b11111111进行与操作,得到的应该还是其本身,这一步操作是否必要? 为了对齐8位?
result |= (cur & 0x7f) << (count * 7); //该字节与0b0111111进行与操作,去除最高位,然后左移7*count位数,与result进行或运算连接,左移是因为是小端存储
count++;
} while (((cur & 0x80) == 0x80) && count < 5);//与0b10000000,最高位是1并且小于5个字节则一直循环
//10000 0000 是非法的LEB128序列,0用00000000表示
if ((cur & 0x80) == 0x80) {
throw new DexException("invalid LEB128 sequence");
}
return result;
}
public static String decode(Buffer in, char[] out) throws IOException {
int s = 0;
while (true) {
char a = (char) (in.readByte() & 0xff);
if (a == 0) {
//字符串以\0结尾
return new String(out, 0, s);
}
out[s] = a;
if (a < '\u0080') {
s++;
} else if ((a & 0xe0) == 0xc0) {
int b = in.readByte() & 0xff;
if ((b & 0xC0) != 0x80) {
throw new UTFDataFormatException("bad second byte");
}
out[s++] = (char) (((a & 0x1F) << 6) | (b & 0x3F));
} else if ((a & 0xf0) == 0xe0) {
int b = in.readByte() & 0xff;
int c = in.readByte() & 0xff;
if (((b & 0xC0) != 0x80) || ((c & 0xC0) != 0x80)) {
throw new UTFDataFormatException("bad second or third byte");
}
out[s++] = (char) (((a & 0x0F) << 12) | ((b & 0x3F) << 6) | (c & 0x3F));
} else {
throw new UTFDataFormatException("bad byte");
}
}
}输出如下:
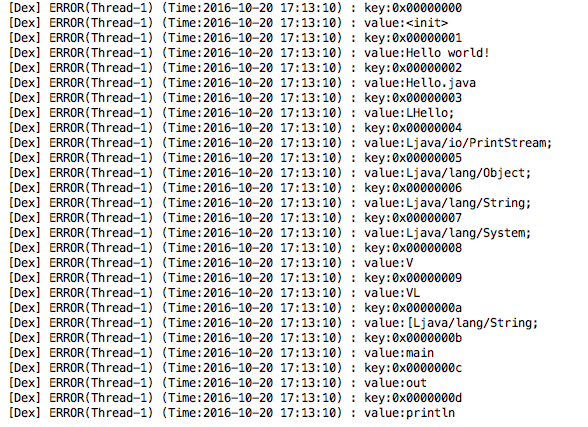
String data段主要知道对应索引的字符串即可,比如0x0000000d对应的是println字符串。
解析Type ids区中的内容
这个数据结构中存放的数据主要是描述dex中所有的类型,比如类类型,基本类型等信息。type_ids 区索引了 dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型和基本类型 。我们从文件头中读取到size和off数据后,从off开始的地址读取size个数据即可,而off指向的地址,对应的数据结构是type在string table中的索引值。由于type区域后续还要用到,这里也封装成函数。
public HashMap<Integer, String> getTypesIds() throws IOException {
//获得刚才解析的字符串区域的内容
HashMap<Integer, String> stringTable = getStringTable();
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
//获得type索引个数
int size = bufferedSource.readIntLe();
//获取type偏移地址
int offset = bufferedSource.readIntLe();
//移动到索引处
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
for (int i = 0; i < size; i++) {
//off开始的地址是int类型的数据结构
int readIntLe = bufferedSource.readIntLe();
//从字符串区域中获取type对应的字符串
String typeString = stringTable.get(readIntLe);
hashMap.put(i, typeString);
}
return hashMap;
}输出结果如下:
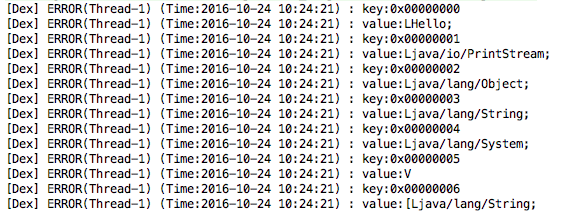
解析Proto Ids区中的内容
这个区域的数据 method 的函数原型 。proto_ids 里的元素为 proto_id_item , 结构如下 :
| 名称 | 数据类型 | 大小 |
|---|---|---|
| shorty_idx | int | 4字节 |
| return_type_idx | int | 4字节 |
| parameters_off | int | 4字节 |
parameters_off值如果大于0,则表示有参数,执行参数的偏移地址,前面四个自己表示参数个数n,后面紧跟n个short类型的type 索引。
解析代码如下:
public HashMap<Integer, String> getProtoIds() throws IOException {
// 获取字符串区域数据
HashMap<Integer, String> stringTable = getStringTable();
//获取类型区域数据
HashMap<Integer, String> typesIds = getTypesIds();
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
//读取Proto size
int size = bufferedSource.readIntLe();
//读取Proto off
int offset = bufferedSource.readIntLe();
//移动到偏移地址
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
for (int i = 0; i < size; i++) {
//读取shorty_idx
int shorty_idx = bufferedSource.readIntLe();
//读取return_type_idx
int return_type_idx = bufferedSource.readIntLe();
//读取parameters_off
int parameters_off = bufferedSource.readIntLe();
String shortyString = stringTable.get(shorty_idx);
String returnTypeString = typesIds.get(return_type_idx);
List<String> parametersString = new ArrayList<>();
//如果parameters_off大于0,则有参数
if (parameters_off > 0) {
BufferedSource source = Okio.buffer(Okio.source(DEX));
//移动到偏移处
source.skip(parameters_off);
//第一个自己是参数个数
int parameterSize = source.readIntLe();
for (int j = 0; j < parameterSize; j++) {
//循环读取参数类型
int typeIds = source.readShortLe();
String s = typesIds.get(typeIds);
parametersString.add(s);
}
}
String format = String.format("%s %s %s", shortyString, returnTypeString, parametersString);
hashMap.put(i, format);
}
return hashMap;
}
输出结果:

解析Field ids区中的内容
这个区域存储着Dex中所用Field。它指向的数据结构如下表所示:
| 名称 | 数据类型 | 大小 |
|---|---|---|
| class_idx | short | 2字节 |
| type_idx | short | 2字节 |
| name_idx | int | 4字节 |
解析代码如下:
//获取字符串内容
HashMap<Integer, String> stringTable = getStringTable();
//获取type内容
HashMap<Integer, String> typesIds = getTypesIds();
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
//field 大小
int size = bufferedSource.readIntLe();
//field 索引
int offset = bufferedSource.readIntLe();
Logger.e(TAG, "field size: %s", size);
Logger.e(TAG, "field offset: %s", offset);
//移动到索引
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
//循环读取size个field
for (int i = 0; i < size; i++) {
//读取class_idx
int class_idx = bufferedSource.readShortLe();
//读取type_idx
int type_idx = bufferedSource.readShortLe();
//读取name_idx
int name_idx = bufferedSource.readIntLe();
Logger.e(TAG, "index %s: %s %s %s", i, class_idx, type_idx, name_idx);
String classString = typesIds.get(class_idx);
String typeString = typesIds.get(type_idx);
String nameString = stringTable.get(name_idx);
Logger.e(TAG, "string %s: %s %s %s", i, classString, typeString, nameString);
}输出结果:

解析Method Ids区中的内容
这个区索引了整个Dex中的方法。其指向的数据结构如下表所示
| 名称 | 数据类型 | 大小 |
|---|---|---|
| class_idx | short | 2字节 |
| proto_idx | short | 2字节 |
| name_idx | int | 4字节 |
class_idx是type ids的一索引。proto_idx是proto ids的一个索引。name_idx是string区的一个索引。
解析代码如下:
public HashMap<Integer, String> getMethodIds() throws IOException {
//获取字符串索引表
HashMap<Integer, String> stringTable = getStringTable();
//获取类型索引表
HashMap<Integer, String> typesIds = getTypesIds();
//获得原型索引表
HashMap<Integer, String> protoIds = getProtoIds();
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
//读取方法个数
int size = bufferedSource.readIntLe();
//读取偏移地址
int offset = bufferedSource.readIntLe();
//移动到偏移地址处
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
for (int i = 0; i < size; i++) {
int class_idx = bufferedSource.readShortLe();
int proto_idx = bufferedSource.readShortLe();
int name_idx = bufferedSource.readIntLe();
//获得class名
String classString = typesIds.get(class_idx);
//获得原型字符串
String protoString = protoIds.get(proto_idx);
//获得函数名
String nameString = stringTable.get(name_idx);
hashMap.put(i, String.format("%s %s %s", classString, protoString, nameString));
}
return hashMap;
}输出结果:

解析class_defs区中的内容
这个区非常复杂,简单过一下。
| 名称 | 数据类型 | 大小 |
|---|---|---|
| class_idx | int | 4字节 |
| access_flags | int | 4字节 |
| superclass_idx | int | 4字节 |
| iterfaces_off | int | 4字节 |
| source_file_idx | int | 4字节 |
| annotations_off | int | 4字节 |
| class_data_off | int | 4字节 |
| static_value_off | int | 4字节 |
解析代码如下:
HashMap<Integer, String> stringTable = getStringTable();
HashMap<Integer, String> typesIds = getTypesIds();
HashMap<Integer, String> protoIds = getProtoIds();
HashMap<Integer, String> methodIds = getMethodIds();
BufferedSource bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(8);
bufferedSource.skip(4);
bufferedSource.skip(20);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
bufferedSource.skip(4);
int size = bufferedSource.readIntLe();
int offset = bufferedSource.readIntLe();
Logger.e(TAG, "class def size: %s", size);
Logger.e(TAG, "class def offset: %s", offset);
bufferedSource = Okio.buffer(Okio.source(DEX));
bufferedSource.skip(offset);
for (int i = 0; i < size; i++) {
int class_idx = bufferedSource.readIntLe();
int access_flags = bufferedSource.readIntLe();
int superclass_idx = bufferedSource.readIntLe();
int iterfaces_off = bufferedSource.readIntLe();
int source_file_idx = bufferedSource.readIntLe();
int annotations_off = bufferedSource.readIntLe();
int class_data_off = bufferedSource.readIntLe();
int static_value_off = bufferedSource.readIntLe();
Logger.e(TAG, "class_idx: %s", typesIds.get(class_idx));
Logger.e(TAG, "access_flags: %s", access_flags);
Logger.e(TAG, "superclass_idx: %s", typesIds.get(superclass_idx));
Logger.e(TAG, "iterfaces_off: %s", iterfaces_off);
Logger.e(TAG, "source_file_idx: %s", stringTable.get(source_file_idx));
Logger.e(TAG, "annotations_off: %s", annotations_off);
Logger.e(TAG, "class_data_off: %s", class_data_off);
Logger.e(TAG, "static_value_off: %s", static_value_off);
if (iterfaces_off > 0) {
BufferedSource interfaceBuffer = Okio.buffer(Okio.source(DEX));
interfaceBuffer.skip(iterfaces_off);
int interfacesSize = interfaceBuffer.readIntLe();
Logger.e(TAG, "interfacesSize: %s", interfacesSize);
for (int j = 0; j < interfacesSize; j++) {
int interfaceIndex = interfaceBuffer.readIntLe();
String interfacesString = typesIds.get(interfaceIndex);
Logger.e(TAG, "interfacesString: %s", interfacesString);
}
}
if (annotations_off > 0) {
}
if (class_data_off > 0) {
BufferedSource classDataBuffer = Okio.buffer(Okio.source(DEX));
classDataBuffer.skip(class_data_off);
Buffer buffer = new Buffer();
buffer.writeAll(classDataBuffer);
int staticFieldsSize = readUnsignedLeb128(buffer);
int instanceFieldsSize = readUnsignedLeb128(buffer);
int directMethodsSize = readUnsignedLeb128(buffer);
int virtualMethodsSize = readUnsignedLeb128(buffer);
Logger.e(TAG, "staticFieldsSize: %s", staticFieldsSize);
Logger.e(TAG, "instanceFieldsSize: %s", instanceFieldsSize);
Logger.e(TAG, "directMethodsSize: %s", directMethodsSize);
Logger.e(TAG, "virtualMethodsSize: %s", virtualMethodsSize);
int fieldIndex = 0;
for (int j = 0; j < staticFieldsSize; j++) {
fieldIndex += readUnsignedLeb128(buffer); // field index diff
int accessFlags = readUnsignedLeb128(buffer);
Logger.e(TAG, "field index diff: %s", fieldIndex);
Logger.e(TAG, "accessFlags: %s", accessFlags);
}
fieldIndex = 0;
for (int j = 0; j < instanceFieldsSize; j++) {
fieldIndex += readUnsignedLeb128(buffer); // field index diff
int accessFlags = readUnsignedLeb128(buffer);
Logger.e(TAG, "field index diff: %s", fieldIndex);
Logger.e(TAG, "accessFlags: %s", accessFlags);
}
int methodIndex = 0;
for (int j = 0; j < directMethodsSize; j++) {
methodIndex += readUnsignedLeb128(buffer);// method index diff
int accessFlags = readUnsignedLeb128(buffer);
int codeOff = readUnsignedLeb128(buffer);
Logger.e(TAG, "methodIndex: %s", methodIndex);
Logger.e(TAG, "methodIndexString: %s", methodIds.get(methodIndex));
Logger.e(TAG, "accessFlags: %s", accessFlags);
Logger.e(TAG, "codeOff: %s", codeOff);
BufferedSource codeOffBuffer = Okio.buffer(Okio.source(DEX));
codeOffBuffer.skip(codeOff);
short registersSize = codeOffBuffer.readShortLe();
short insSize = codeOffBuffer.readShortLe();
short outsSize = codeOffBuffer.readShortLe();
short triesSize = codeOffBuffer.readShortLe();
int debugInfoOff = codeOffBuffer.readIntLe();
int insnsSize = codeOffBuffer.readIntLe();
byte[] bytes = codeOffBuffer.readByteArray(insnsSize * 2);
Buffer insnsBuffer = new Buffer();
insnsBuffer.write(bytes);
Logger.e(TAG, "registersSize: %s", registersSize);
Logger.e(TAG, "insSize: %s", insSize);
Logger.e(TAG, "outsSize: %s", outsSize);
Logger.e(TAG, "triesSize: %s", triesSize);
Logger.e(TAG, "debugInfoOff: %s", debugInfoOff);
Logger.e(TAG, "insnsSize: %s", insnsSize);
Logger.e(TAG, "insnsBuffer: %s", insnsBuffer);
}
methodIndex = 0;
for (int j = 0; j < virtualMethodsSize; j++) {
methodIndex += readUnsignedLeb128(buffer);// method index diff
int accessFlags = readUnsignedLeb128(buffer);
int codeOff = readUnsignedLeb128(buffer);
Logger.e(TAG, "methodIndex: %s", methodIndex);
Logger.e(TAG, "methodIndexString: %s", methodIds.get(methodIndex));
Logger.e(TAG, "accessFlags: %s", accessFlags);
Logger.e(TAG, "codeOff: %s", codeOff);
BufferedSource codeOffBuffer = Okio.buffer(Okio.source(DEX));
codeOffBuffer.skip(codeOff);
}
}
if (static_value_off > 0) {
}
}介绍语
本来想详细写下Dex文件结构的,没想到写着写着,越写越多,越写越不想写,于是这篇文章算半成品吧,胎死腹中了。。。。呵呵!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









