







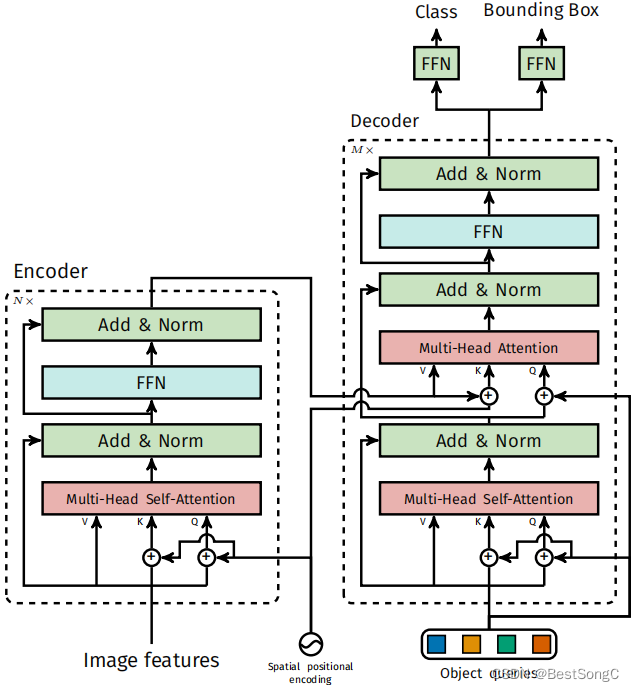
DETR:End-to-End Object Detection with Transformers
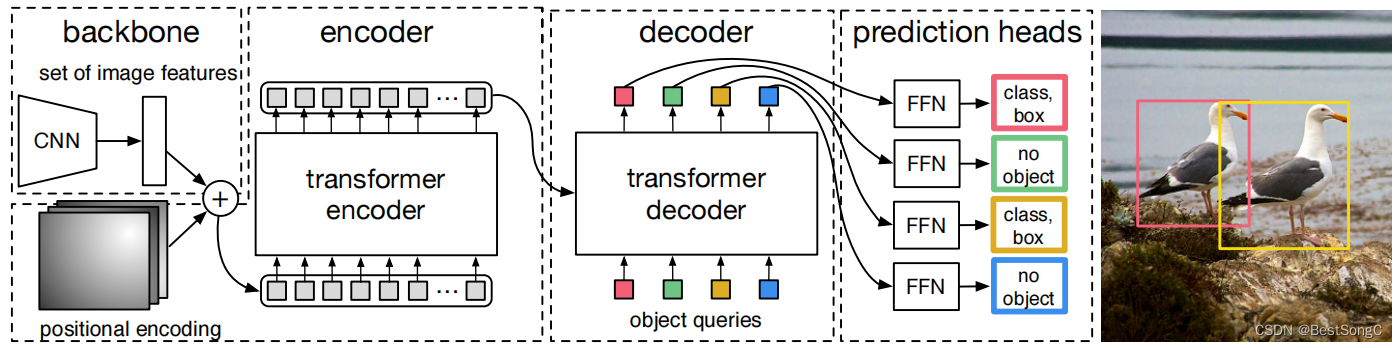
- Encoder:Transformer encoder
- Decoder:Transformer decoder
- GT与预测Queries匹配:匈牙利匹配算法
- 损失计算:分类 + L1边框回归 + GIoU边框回归
- 源码地址:https://github.com/facebookresearch/detr
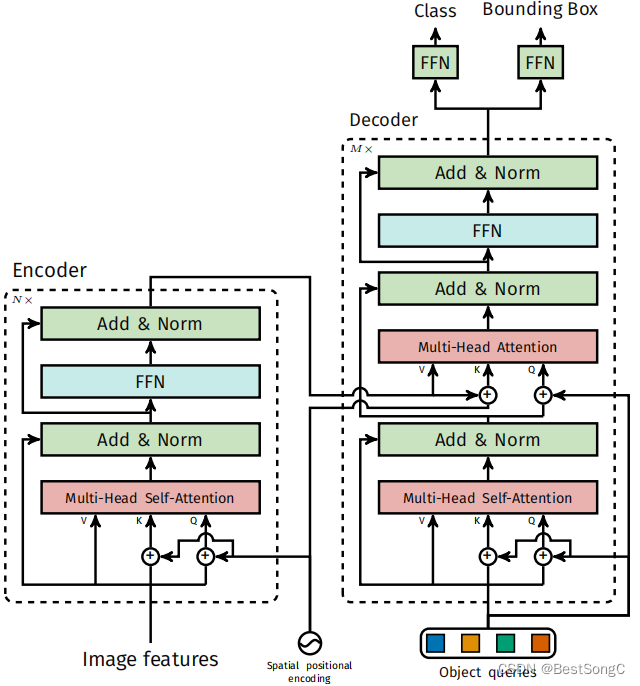
3.2 Transformer encoder和 decoder(重点)
Transformer的forward前向推理过程(在transformer.py中):
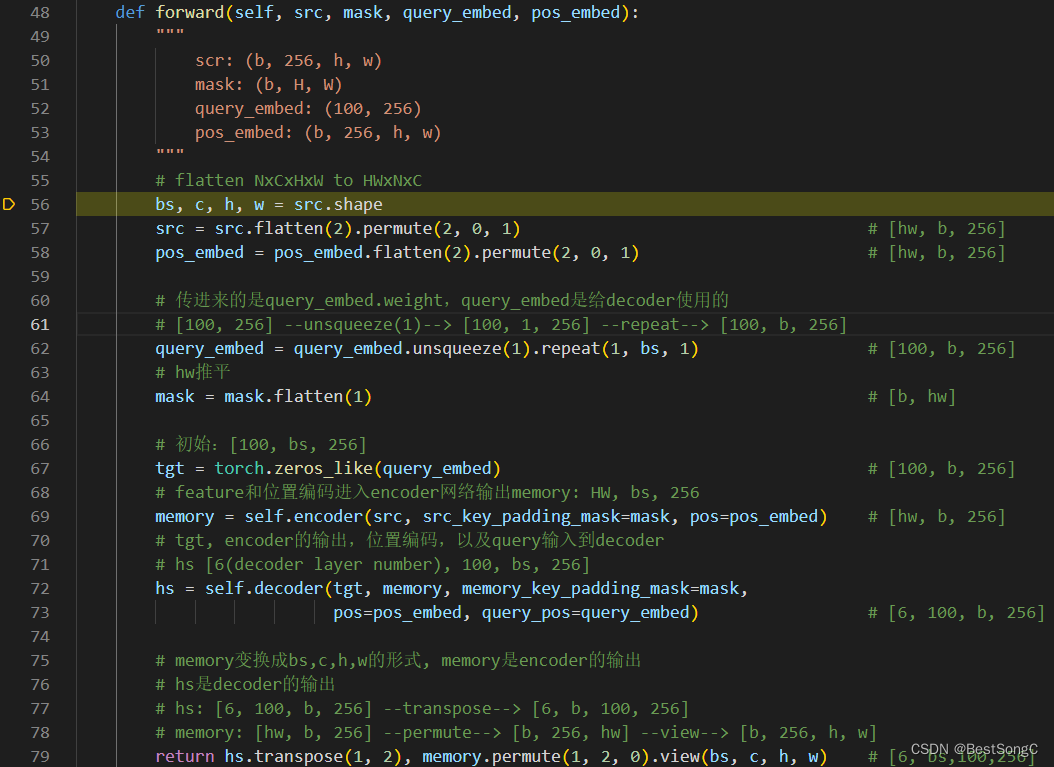
- 展平src,维度是 [hw, b, 256]
- 展平pos_emd,维度是 [hw, b, 256]
- query_embed,输出是 [hw, b, 256]
- tgt是在进入decoder第一层初始化的queries,维度是 [100, b, 256]
- memory:encoder的输出,维度是 [hw, b, 256]
- hs:decoder的输出,维度是 [6, 100, b, 256]
3.2.1 TransformerEncoder
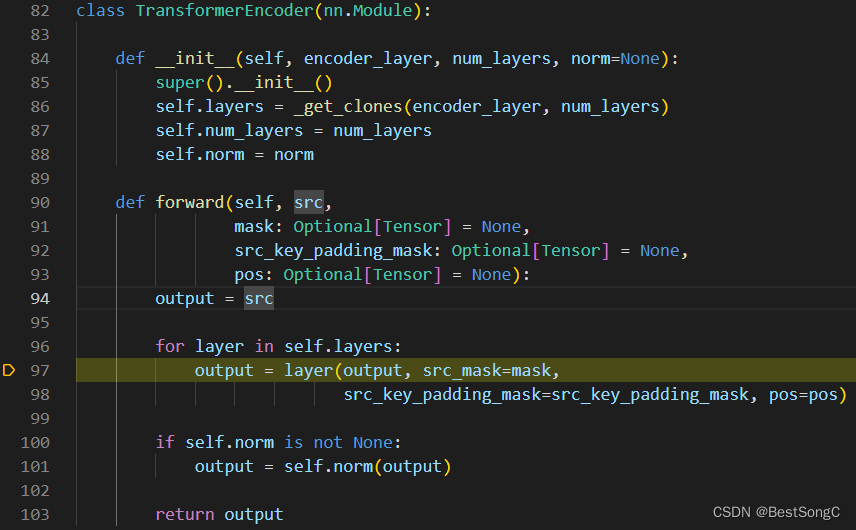
TransformerEncoder的forward过程是依次送入n个TransformerEncoderLayer,对于第一层的输入是256维特征(也就是resnet得到的2048维特征再经过线性映射饿到的256维特征)和position embedding;对于后续几层的输入是前一层的输出和position embedding,具体实现结构和代码如下所示:
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
"""
d_model: 512是encoder中的宽度
2048: FNN的宽度
"""
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
"""
norm在attention和mlp之后
src: (hw, b, 256)
"""
# q和k: 融合位置编码,value不使用位置编码
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
# Dropout + residual
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
TransformerEncoderLayer
- 输入:src: [hw, b, 256] pos_embed: [hw, b, 256]
- 输出: memory: [hw, b, 256]
3.2.2 TransformerDecoder
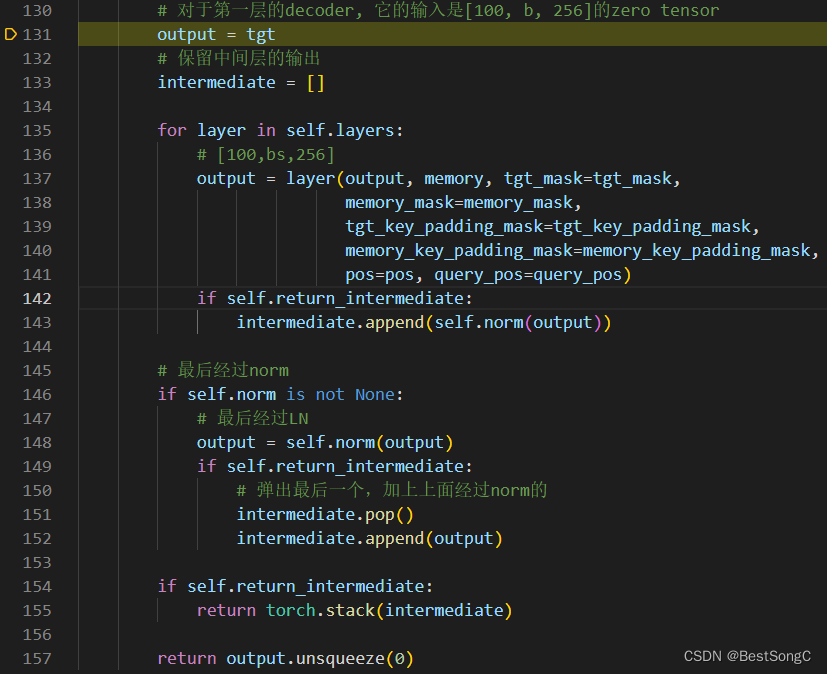
TransformerDecoder的forward过程是依次送入n个TransformerDecoderLayer,对于第一层的输入object Queries、tgt(初始值为0的Tensor)、encoder层的输出memory以及position embedding;对于后续几层的输入是object Queries、上一层decoder的输出、encoder层的输出memory以及position embedding,具体实现结构和代码如下所示:
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
"""
tgt: [100,bs,256]
memory: [hw,bs,256]
pos: [hw,bs,256]
query_pos: [100,bs,256]
"""
# query_pos 就是 query_embed
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
TransformerDncoderLayer
- 输入:memory: [hw, b, 256] pos_embed: [hw, b, 256] query_embed: [100, b, 256] tgt: [100, b, 256]
- 输出: hs: [6, 100, b, 256] (6代表Decoder的输出层数)
彩蛋
本文对DETR代码的模型构建和初始化进行详细阐述,笔者会持续分享DETR解析系列,笔者也建立了一个关于目标检测的交流群:465411015,欢迎大家踊跃加入,一起学习鸭!
笔者也持续更新一个微信公众号:Nuist计算机视觉与模式识别,大家帮忙点个关注谢谢!关注后回复DETR获得DETR源码解析完整pdf















 2048
2048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









