






将stream流操作分成三种类型:
- 创建Stream
- Stream中间处理
- 终止Steam

每个Stream管道操作都包含若干方法,先列举一下各个API的方法:
1.1开始管道
主要负责新建一个Stream流,或者基于现有的数组、List、Set、Map等集合类型对象创建出新的Stream流。

1.2中间管道
负责对Stream进行处理操作,并返回一个新的Stream对象,中间管道操作可以进行叠加。
| API | 功能说明 |
| filter() | 按照条件过滤符合要求的元素, 返回新的stream流。 |
| map() | 将已有元素转换为另一个对象类型,一对一逻辑,返回新的stream流。 |
| flatMap() | 将已有元素转换为另一个对象类型,一对多逻辑,即原来一个元素对象可能会转换为1个或者多个新类型的元素,返回新的stream流。 |
| limit() | 仅保留集合前面指定个数的元素,返回新的stream流。 |
| skip() | 跳过集合前面指定个数的元素,返回新的stream流。 |
| concat() | 将两个流的数据合并起来为1个新的流,返回新的stream流。 |
| distinct() | 对Stream中所有元素进行去重,返回新的stream流。 |
| sorted() | 对stream中所有的元素按照指定规则进行排序,返回新的stream流。 |
| peek() | 对stream流中的每个元素进行逐个遍历处理,返回处理后的stream流。 |
1.3终止管道
顾名思义,通过终止管道操作之后,Stream流将会结束,最后可能会执行某些逻辑处理,或者是按照要求返回某些执行后的结果数据。
| API | 功能说明 |
| count() | 返回stream处理后最终的元素个数。 |
| max() | 返回stream处理后的元素最大值。 |
| min() | 返回stream处理后的元素最小值。 |
| findFirst() | 找到第一个符合条件的元素时则终止流处理。 |
| findAny() | 找到任何一个符合条件的元素时则退出流处理,这个对于串行流时与findFirst相同,对于并行流时比较高效,任何分片中找到都会终止后续计算逻辑。 |
| anyMatch() | 返回一个boolean值,类似于isContains(),用于判断是否有符合条件的元素。 |
| allMatch() | 返回一个boolean值,用于判断是否所有元素都符合条件。 |
| noneMatch() | 返回一个boolean值, 用于判断是否所有元素都不符合条件。 |
| collect() | 将流转换为指定的类型,通过Collectors进行指定。 |
| toArray() | 将流转换为数组。 |
| iterator() | 将流转换为Iterator对象。 |
| foreach() | 无返回值,对元素进行逐个遍历,然后执行给定的处理逻辑。 |
二、Stream方法的使用
2.1map与flatMap
在项目中,经常看到也经常使用到map与flatMap,比如代码:

那两者有什么相同和不同呢?
map与flatMap都是用于转换已有的元素为其它元素,区别点在于:
-
map 必须是一对一的,即每个元素都只能转换为1个新的元素;
-
flatMap 可以是一对多的,即每个元素都可以转换为1个或者多个新的元素;
下面两张图形象地说明了两者之间的区别:
map图:

flatMap图:

map用例:
有一个字符串ID列表,现在需要将其转为别的对象列表。
/** *
* map的用途:一换一
* */
List<String> ids = Arrays.asList("205", "105", "308", "469", "627", "193", "111");
// 使用流操作
List<NormalOfferModel> results = ids.stream()
.map(id -> {
NormalOfferModel model = new NormalOfferModel();
model.setCate1LevelId(id);
return model;
}).collect(Collectors.toList());
System.out.println(results);flatMap用例:
现有一个句子列表,需要将句子中每个单词都提取出来得到一个所有单词列表:

这里需要补充一句,flatMap操作的时候其实是先每个元素处理并返回一个新的Stream,然后将多个Stream展开合并为了一个完整的新的Stream,如下:

2.2 peek和foreach方法
peek和foreach,都可以用于对元素进行遍历然后逐个处理。
但根据前面的介绍,peek属于中间方法,而foreach属于终止方法。这也就意味着peek只能作为管道中途的一个处理步骤,而没法直接执行得到结果,其后面必须还要有其它终止操作的时候才会被执行;而foreach作为无返回值的终止方法,则可以直接执行相关操作。

2.3 filter、sorted、distinct、limit
这几个都是常用的Stream的中间操作方法,具体的方法的含义在上面的表格里面有说明。具体使用的时候,可以根据需要选择一个或者多个进行组合使用,或者同时使用多个相同方法的组合:

2.4 简单结果终止流
按照前面介绍的,终止方法里面像count、max、min、findAny、findFirst、anyMatch、allMatch、noneMatch等方法,均属于这里说的简单结果终止方法。所谓简单,指的是其结果形式是数字、布尔值或者Optional对象值等。

一旦一个Stream被执行了终止操作之后,后续便不可以再读这个流执行其他的操作了,否则会报错,看下面示例:

因为stream已经被执行count()终止方法了,所以对stream再执行anyMatch方法的时候,就会报错stream has already been operated upon or closed,这一点在使用的时候需要特别注意。
2.5 结果收集终止方法
因为Stream主要用于对集合数据的处理场景,所以除了上面几种获取简单结果的终止方法之外,更多的场景是获取一个集合类的结果对象,比如List、Set或者HashMap等。
这里就需要collect方法出场了,它可以支持生成如下类型的结果数据:
1.一个集合类,比如List、Set或者HashMap等;
2.StringBuilder对象,支持将多个字符串进行拼接处理并输出拼接后结果;
3.一个可以记录个数或者计算总和的对象(数据批量运算统计);
2.5.1生成集合对象
应该算是collect最常被使用到的一个场景了:

2.5.2 生成拼接字符串
将一个List或者数组中的值拼接到一个字符串里并以逗号分隔开,这个场景相信大家都不陌生吧?如果通过for循环和StringBuilder去循环拼接,还得考虑下最后一个逗号如何处理的问题,很繁琐:

2.5.3批量数学运算
还有一种场景,实际使用的时候可能会比较少,就是使用collect生成数字数据的总和信息,也可以了解下实现方式:

三、并行Stream
3.1parallelStream的机制说明
使用并行流,可以有效利用计算机的多CPU硬件,提升逻辑的执行速度。并行流通过将一整个stream划分为多个片段,然后对各个分片流并行执行处理逻辑,最后将各个分片流的执行结果汇总为一个整体流。
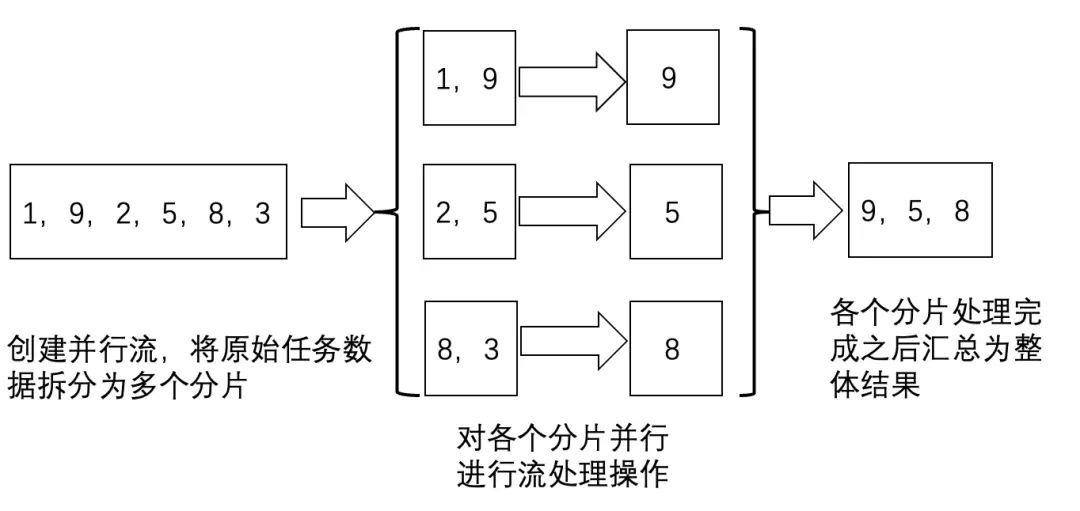
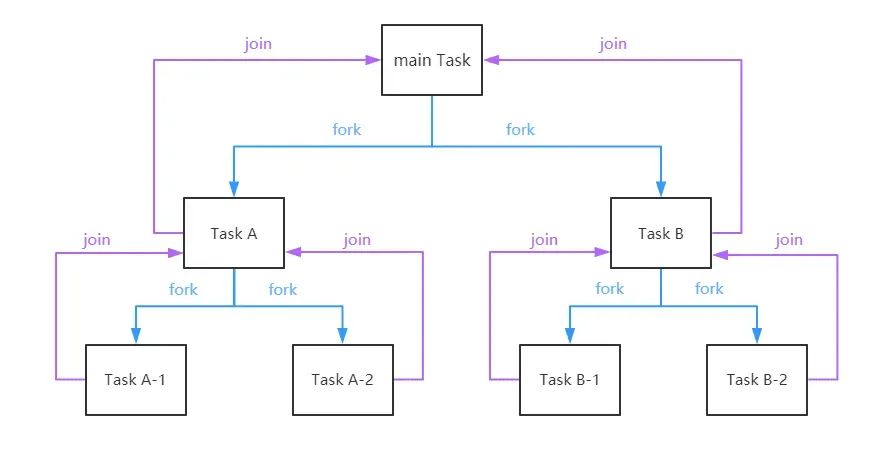
可以通过parallelStream的源码发现parallel Stream底层是将任务进行了切分,最终将任务传递给了jdk8自带的“全局”ForkJoinPool线程池。 在Fork-Join中,比如一个拥有4个线程的ForkJoinPool线程池,有一个任务队列,一个大的任务切分出的子任务会提交到线程池的任务队列中,4个线程从任务队列中获取任务执行,哪个线程执行的任务快,哪个线程执行的任务就多,只有队列中没有任务线程才是空闲的,这就是工作窃取。
可以通过下图更好的理解这种“分而治之”的思想:
3.2约束与限制
1.parallelStream()中foreach()操作必须保证是线程安全的;
很多人在用惯了流式处理之后,很多for循环都会直接使用流式foreach(),实际上这样不一定是合理的,如果只是简单的for循环,确实没有必要使用流式处理,因为流式底层封装了很多流式处理的复杂逻辑,从性能上来讲不占优。
2.parallelStream()中foreach()不要直接使用默认的线程池;

3.parallelStream()使用的时候尽量避免耗时操作;
如果遇到耗时的操作,或者大量IO的操作,或者有线程sleep的操作一定要避免使用并行流。
四、Stream流可能会遇到的一些坑点
4.1 parallelStream和整个java进程共用ForkJoinPool
如果直接使用parallelStream().foreach会默认使用全局的ForkJoinPool,而这样就会导致当前程序很多地方共用同一个线程池,包括gc相关操作在内,所以一旦任务队列中满了之后,就会出现阻塞的情况,导致整个程序的只要当前使用ForkJoinPool的地方都会出现问题。
4.2 parallelStream使用后ThreadLocal数据为空
parallelStream创建的并行流在真正执行时是由ForkJoin框架创建多个线程并行执行,由于ThreadLocal本身不具有可继承性,新生成的线程自然无法获取父线程中的ThreadLocal数据。
4.3 转map的时候,没有注意到key值重复
在使用Stream流转map操作的时候,需要注意key重复的问题。
五、Stream流总结
5.1优势
1.代码更简洁。偏声明式的编码风格,更容易体现出代码的逻辑意图。
2.逻辑间解耦。一个stream中间处理逻辑,无需关注上游与下游的内容,只需要按约定实现自身逻辑即可。
3.并行流场景效率会比迭代器逐个循环更高。
4.函数式接口,延迟执行的特性,中间管道操作不管有多少步骤都不会立即执行,只有遇到终止操作的时候才会开始执行,可以避免一些中间不必要的操作消耗。
5.2劣势
debug不方便。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









