









1.ORM框架
目录
myBatis这个ORM框架在这些年中,逐渐的进入大家的视野,也是现在企业开发框架中用的比较多的一种ORM框架,其中hibernate也是一种ORM框架,但是个人觉得hibernate可能太重了,适合非常大的项目使用,而且是对hibernate设计理念以及原理都非常清楚的团队来使用;MyBatis是一款优秀的持久层框架,它支持定制化SQL、存储过程以及高级映射。MyBatis避免了几乎所有的JDBC代码和手动设置参数以及获取结果集。MyBatis可以使用简单的XML或注解来配置和映射原生类型、接口和Java的POJO(PlainOldJavaObjects,普通老式Java对象)为数据库中的记录。
不管是mybatis还是hibernate,都是一种ORM框架,那么ORM到底是什么意思呢?
ORM的全称是Object Relational Mapping(对象关系映射),我自己的理解就是将数据库中的数据映射到我们的对象中,通过面向对象的方式将数据封装成一个一个的对象;
在传统的JDBC操作数据库的过程中,你从数据库查询出一条数据过后,那么返回的结果集是一个MetaData或者说是一个游标,这个时候如果你想要得到这个数据,必须自己从结果集中取出数据,然后如果要封装到一个对象中,那么你还的一个一个的去手动封装,其实ORM框架的底层原理也就是传统的JDBC操作数据库,然后将数据库返回的数据封装到结果集对象中,完成了数据到对象的映射,所以也就叫做ORM框架,所有的ORM框架,不管是mybatis还是hibernate以及各自的企业中自己研发的框架,包括spring data提供的一些jdbc操作,那么底层必定是传统的JDBC操作,像比如一些封装了底层的数据操作,类似于hibernate和mybatis,那么事物怎么控制?还不是就是传统的JDBC的控制方式,设置事物不自动提交,然后自己来提交,涉及到的api也都是rt.jar中的传统JDBC的操作方式。所以说不管什么ORM框架,那么底层操作数据库的原理都是一模一样的,没有任何区别,因为也绕不开。像mybatis或者hibernate,其实就是提供了一种方式,将数据的操作封装到框架中,而你只需要做你关心的事情,类似于spring也是这种思维,你只需要做你想做的事情,其他无关事物本身的事情由框架来帮你完成,而这样就摆脱了一些琐碎的事情,从开发的角度来说,开发效率高了,从维护的成本来说,成本下降而来,从运行的性能来说,也有提高或者平衡。
2.传统JDBC的弊端
其实传统的JDBC的弊端上面已经说了,传统的jdbc的连接的打开和关闭是由开发者去自行控制的,那么一个团队里面的开发人员万一打开没有关闭,或者对于连接的打开和关闭无法掌握,那么一定会出现连接的问题;这里总结出来几点:
1、jdbc底层没有用连接池、操作数据库需要频繁的创建和关联链接。消耗很大的资源
2、写原生的jdbc代码在java中,一旦我们要修改sql的话,java需要整体编译,不利于系统维护
3、使用PreparedStatement预编译的话对变量进行设置123数字,这样的序号不利于维护
4、返回result结果集也需要硬编码。
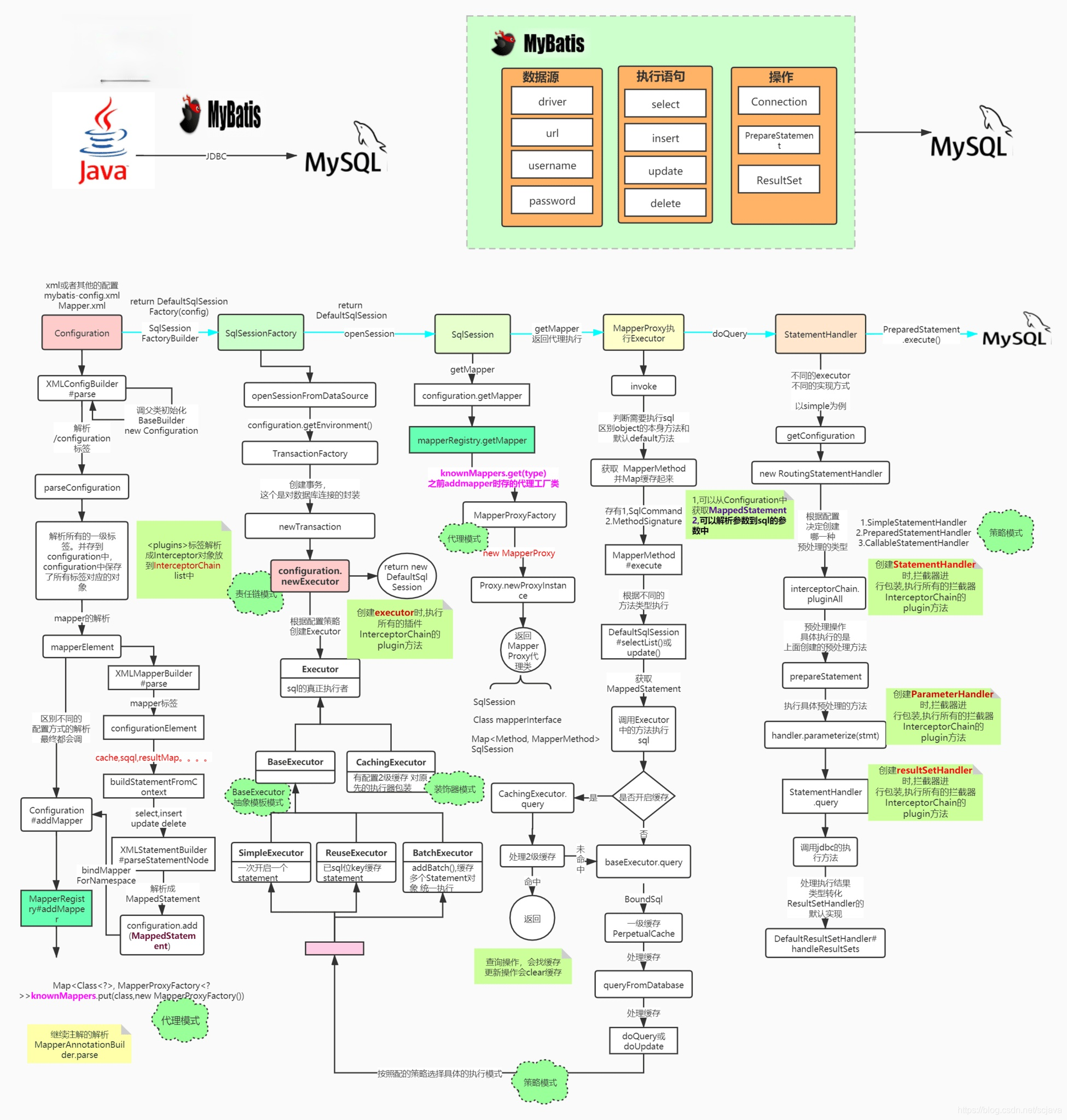
3.mybatis的整体流程分析
mybatis大家用的也比较多,我们都知道mybatis有一个全局的配置文件,就是配置数据库连接或者其他的一些配置,比如缓存的配置,插件的配置等,而这个全局的配置文件会被mybatis加载并且解析,数据源的信息配置也在这个全局的配置文件汇总,所以说我们可以认为谁来解析这个配置文件,那么谁有可能得到数据库的连接信息,也就具有操作数据库的能力;我们看下面的代码
InputStream input = Resources.getResourceAsStream("MyBatis.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(input);
SqlSession sqlSession = sessionFactory.openSession();
List<User> list = sqlSession.selectList("com.mybatis.example.mapper.UserMapper.queryAll");
list.forEach(System.out::println);其中myBatis.xml就是我们的mybatis的全局配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- autoMappingBehavior should be set in each test case -->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
</transactionManager>
<!-- 这里的type代表的就是数据域的类型,通过类型找到指定的数据源对象-->
<dataSource type="UNPOOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="111111"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapping/UserMapper.xml" />
</mappers>
</configuration>在mybatis中,myBatis.xml全局配置文件最终户解析到一个对象Configuration中,数据库连接的获取包括事务的获取创建等都在里面;所以说SqlSessionFactoryBuilder来解析这个配置文件得到一个SqlSessionFactory(DefaultSqlSessionFactory),那么SqlSessionFactory就具有包含了Configuration对象的所有信息。
3.1解析配置文件
/**
* 这里是构建SqlSessionfactory,构建成功会返回一个默认的SqlSessionFactory=DefaultSqlSessionFactory
* 这个build方法主要就是读取mybatis的配置文件,里面包含了很多的配置信息,
* 比如数据源的配置,事物的配置;我这里主要是读取resource下面的MyBatis.xml的配置文件
* 在这个配置文件主要解析了configuration标签,这个就是mybatis的总的上下文的一个配置文件
* 也就是说它具有加载数据源、执行sql语句,拿到执行结果,这里涉及了好几个感念,其中configuration解析的标签
* 在mybatis中也有一个对应的对象Configuration,其中解析的结果就会封装成要一个Configuration对象
* Configuration:管理配置文件mysql-config.xml配置文件
* SqlSessionFactory:Session管理工厂接口
* Session:SqlSession是一个面向用户(程序员)的接口,SqlSession中提供了很多操作数据库的方法
* Executor:执行器是一个接口(基本执行器,缓存执行器)作用:SqlSession内部通过执行器操作数据库
* MappedStatement:底层封装的对象,对操作数据库存储封装,包括sql语句、输入输出参数
* StatementHandler:具体操作数据库相关的handler接口
* ResultSetHandler:具体操作数据库返回结果的handler接口
* @param inputStream
* @return
*/
public SqlSessionFactory build(InputStream inputStream) {
return build(inputStream, null, null);
}
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
/**
* inputStream中是我们的全局上下文配置文件的一个输入流对象
* environment:是环境信息
* properties:是引入的配置文件之一
* 这里会将这几个对象进行封装,其中会将inputStream流创建为一个Documet对象,然后返回一个解析的对象
* XMLConfigBuilder,所做的事情:
* 1.将inputstream流创建为一个Document对象,然后封装在对象XPathParser中;
* 2.new Configuration()对象得到configuration;
* 3.如果environment不为空,设置全局的environment为传入的environment;
* 4.如果properties不为空,则将传入的properties设置到configuration中的variables中。
*/
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
/**
* 这里有两个操作
* 1.parser.parse()方法就是开始解析Mybatis.xml配置文件,得到一个Configuration对象,而这个
* Configuration对象就是上面new出来的configuration对象;
* 2.调用build方法将上下文configuration对象封装成一个DefaultSqlSessionFactory,也就是我们常常
* 看见的SqlSessionFactory
* 所以核心的重点是parser.parse()方法,需要重点分析
*/
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}上面的总体流程就是:
1.解析配置文件(myBatis.xml);
2.将每个标签解析都创建一个对象,比如解析environment标签,会解析到一个Environment对象,最后解析完会设置到Configuration对象中,所以我们从配置文件的结构来看是有层级关系的,也即是可以说是继承关系,但是在mybatis的源码实现中,不是采用的继承关系,而是组合关系模式。
3.最后将所有的 标签都解析出来创建一个相对应的对象然后设置到configuration中。
4.最后根据configuration对象创建一个DefaultSqlSessionFactory对象。
5.最后将创建的DefaultSqlSessionFactory返回。
3.2 SessionFactory的build
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
/**
* inputStream中是我们的全局上下文配置文件的一个输入流对象
* environment:是环境信息
* properties:是引入的配置文件之一
* 这里会将这几个对象进行封装,其中会将inputStream流创建为一个Documet对象,然后返回一个解析的对象
* XMLConfigBuilder,所做的事情:
* 1.将inputstream流创建为一个Document对象,然后封装在对象XPathParser中;
* 2.new Configuration()对象得到configuration;
* 3.如果environment不为空,设置全局的environment为传入的environment;
* 4.如果properties不为空,则将传入的properties设置到configuration中的variables中。
*/
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
/**
* 这里有两个操作
* 1.parser.parse()方法就是开始解析Mybatis.xml配置文件,得到一个Configuration对象,而这个
* Configuration对象就是上面new出来的configuration对象;
* 2.调用build方法将上下文configuration对象封装成一个DefaultSqlSessionFactory,也就是我们常常
* 看见的SqlSessionFactory
* 所以核心的重点是parser.parse()方法,需要重点分析
*/
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
XMLConfigBuilder 的创建涉及了Configuration的初始化
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
super(new Configuration());
ErrorContext.instance().resource("SQL Mapper Configuration");
this.configuration.setVariables(props);
this.parsed = false;
this.environment = environment;
this.parser = parser;
}
public Configuration() {
/**
* 这里初始化类型别名注册器
* typeAliasRegistry主要注册的是比如像SqlsessionFactory的一些类别
* 事务工厂的类和一些其他的类
*
* typeAliasRegistry中的key和value最终都会注册到
* TypeAliasRegistry类中的map typeAliases中
* 比如在解析配置文件的configuration中的数据源的时候
* 通过数据源的type就可以在typeAliases中根据type,比如POOLED
* 得到一个数据源工厂PooledDataSourceFactory
*/
typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
typeAliasRegistry.registerAlias("JNDI", JndiDataSourceFactory.class);
typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class);
typeAliasRegistry.registerAlias("UNPOOLED", UnpooledDataSourceFactory.class);
.......通过构建XMLConfigBuilder 对象将Configuration进行初始化得到一个对象Configuration,然后解析完成过后返回这个对象,最后设置到DefaultSqlSessionFactory中,那么DefaultSqlSessionFactory也就可以调度Configuration对象中的功能。
3.3 Configuration的解析
public Configuration parse() {
/**
* 这个parsed代表的意思就是说mybatis上下文配置文件是否已经被解析过了,如果在一个线程中
* 被多次解析,那么就要报错,因为不能创建多个Configuration对象,比如像我们的dataSouce,相同
* 的数据库连接可能在一个系统中存在多个吗,显然是没有必要的,所以这里
* 用了一个parsed参数来控制,万一你调用了多次的parse方法,那么肯定有一次是失败的
* 简单来说就是一个XMLConfigBuilder对象只能调用一次parse方法进行解析配置初始化Configuration
*/
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
//如果没有被解析过,下面马上就要解析了,所以设置是否解析过的参数为true,代表已经解析过
parsed = true;
//这个就是核心的解析方法,主要解析configuration标签
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
private void parseConfiguration(XNode root) {
try {
// issue #117 read properties first
/**
* 这里是解析的properties,这个是干什么的呢,像在一般的系统中,mybatis的配置文件中常常
* 会引入一个必然jdbc.properties文件,所以这里就是解析引入了外部的properties文件的
* 解析了jdbc.properties文件过后,会将mybatis中使用了properties中的参数进行替换
*
* 下面的代码其实都是解析mybatis的配置文件,也就是configuration标签的
* 从下面的代码可以看出这个配置文件的标签是有顺序的,不可以乱写顺序的,比如说properties
* 这个标签必须要在最开始写,如果写到中间或者最后是要报错的,因为代码就是这样写的
* 但是从宏观来看,也是必须的,你首先要将引入的文件解析到变量表中,然后下面引用它的变量才能拿的到
*/
propertiesElement(root.evalNode("properties"));
/**
* 解析settigns
*/
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
/**
* 解析typeAliases
*/
typeAliasesElement(root.evalNode("typeAliases"));
/**
* 解析plugins
*/
pluginElement(root.evalNode("plugins"));
/**
* 解析objectFactory
*/
objectFactoryElement(root.evalNode("objectFactory"));
/**
* 解析objectWrapperFactory
*/
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
/**
* 解析reflectorFactory
*/
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
/**
* 解析environments,这个就比较重要了,这里就是去解析我们的数据源那些
*/
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
/**
* 这里就是解析我们的mappers,mappers就是配置了项目中的mybatis的sql配置文件
*
*/
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}3.3.1 Environment的解析
/**
* 这里是解析configuration中的environment标签和子标签的方法
* @param context
* @throws Exception
*/
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
/**
* 这里就是设置environment的值,在configuration标签中需要设置一个
* default的ID值,这个必须要设置,而且下面的environment中的id值一样
* 否则就不解析environment标签的内容
*/
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
//获取environment中的id值,和configuration中的default的值对比,如果
//说两个值是一样的,才能进行解析environment中的值
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
//这里先拿到事务工厂,事务工厂比如你在environment中配置了transactionManager
//type=JDBC,那么这里的事务工厂得到就是JdbcTransactionFactory
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
//数据源工厂,解析标签datasource,就是拿到数据库的连接信息,然后通过反射得到实例对象
//初始化连接池
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
//通过数据源工厂得到一个数据源DataSource
DataSource dataSource = dsFactory.getDataSource();
//通过建造者模式得到一个Environment对象,将获取的事务工厂和数据源信息封装到environmentBuilder对象中
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
//最后将构建好的环境对象Environment设置到configuration中
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}Environment的解析结果就是将Environment标签都解析出来然后放入创建的Environment对象中,然后在设置到全局的configuration对象中。
3.3.2 Mapper的解析
/**
* 从官网上我们知道mybatis有好几种配置mapper的方法
* 其中有
* resource的方式:
* <mappers>
* <mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
* </mappers>
* url的方式:
* <mappers>
* <mapper url="file:///var/mappers/PostMapper.xml"/>
* </mappers>
* 包的方式:
* <mappers>
* <package name="org.mybatis.builder"/>
* </mappers>
*
* 其中package的方式的优先级最高
* 其中mappers中的每个mapper都遵循下面的代码逻辑:
* 1.一个mapper中只能定义package、url、class、resouce的方式之一;
* 2.其中package的优先级最高,最先解析package,如果package存在,其他的忽略不解析;
* 3.否则开始解析resource(条件是url和class必须为空,否则报错);
* 4.解析url和class都一样的,当解析到url或者class的时候,其他两个配置的属性必须要为空。
*
* @param parent
* @throws Exception
*/
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
//解析package的方式,直接将配置的package添加到configuration中
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
//获取resource,url,mapperClass
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
//解析resouce的方式
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
//解析url的方式
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
//解析class的方式
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
上面的 mapper的解析有好多中方式,其中其实就分了两种,一种是xml文件的解析,一个是类方式的解析,这里分析下xml的解析
public void parse() {
//isResourceLoaded去重的功能 ,代表已经解析过的资源文件
if (!configuration.isResourceLoaded(resource)) {
//解析mapper
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
//解析parameterMap,解析出来过后根据parameterMap的id作为key,解析出来的属性封装成一个对象作为value
//放入map中添加到Configuration中的parameterMaps
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
//解析resultMap,一样的逻辑
resultMapElements(context.evalNodes("/mapper/resultMap"));
//解析sql标签
sqlElement(context.evalNodes("/mapper/sql"));
/**
* 这里就是解析select 、insert、delete、update的标签
*/
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}buildStatementFromContext/buildStatementFromContext
/**
* 这里就是解析<select id="queryAll" resultMap="all" resultType="com.mybatis.example.entity.User" >
* 这种标签的,当然还包括了insert 、update、delete标签
* @param list
* @param requiredDatabaseId
*/
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
//这里的XMLStatementBuilder就是解析xml中声明sql的一个builder
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
//开始解析
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}最后调用 statementParser.parseStatementNode()select|insert|update|delete的标签解析成一个一个的声明对象,放入到configuration中mappedStatements的map中。


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









