






一.回归算法
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。在机器学习领域,人们说起回归,有时候是指一类问题,有时候是指一类算法,这一点常常会使初学者有所困惑。常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)
1.最小二乘法(Ordinary Least Square)
我们以最简单的一元线性模型来解释最小二乘法。什么是一元线性模型呢? 监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),如果预测的变量是连续的,我们称其为回归。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线性是一个超平面…
对于一元线性回归模型, 假设从总体中获取了n组观察值(X1,Y1),(X2,Y2), …,(Xn,Yn)。对于平面中的这n个点,可以使用无数条曲线来拟合。要求样本回归函数尽可能好地拟合这组值。综合起来看,这条直线处于样本数据的中心位置最合理。 选择最佳拟合曲线的标准可以确定为:使总的拟合误差(即总残差)达到最小。有以下三个标准可以选择:
(1)用“残差和最小”确定直线位置是一个途径。但很快发现计算“残差和”存在相互抵消的问题。
(2)用“残差绝对值和最小”确定直线位置也是一个途径。但绝对值的计算比较麻烦。
(3)最小二乘法的原则是以“残差平方和最小”确定直线位置。用最小二乘法除了计算比较方便外,得到的估计量还具有优良特性。这种方法对异常值非常敏感。
最常用的是普通最小二乘法( Ordinary Least Square,OLS):所选择的回归模型应该使所有观察值的残差平方和达到最小。(Q为残差平方和)- 即采用平方损失函数。
样本回归模型:
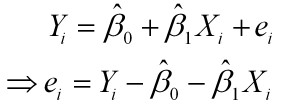
其中ei为样本(Xi, Yi)的误差
平方损失函数:
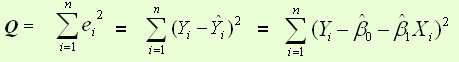
则通过Q最小确定这条直线,即确定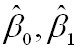
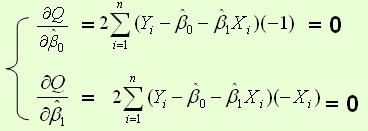
根据数学知识我们知道,函数的极值点为偏导为0的点。
解得:
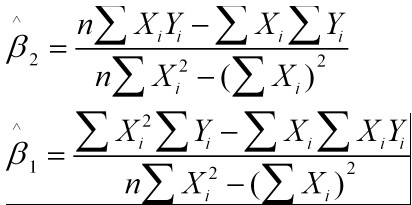
这就是最小二乘法的解法,就是求得平方损失函数的极值点。
2.逻辑回归(Logistic Regression)
什么是逻辑回归?
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinear model)。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
•如果是连续的,就是多重线性回归;
•如果是二项分布,就是Logistic回归;
•如果是Poisson分布,就是Poisson回归;
•如果是负二项分布,就是负二项回归。
Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归。
Logistic回归的主要用途:
•寻找危险因素:寻找某一疾病的危险因素等;
•预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
•判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
Logistic回归主要在流行病学中应用较多,比较常用的情形是探索某疾病的危险因素,根据危险因素预测某疾病发生的概率,等等。例如,想探讨胃癌发生的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群肯定有不同的体征和生活方式等。这里的因变量就是是否胃癌,即“是”或“否”,自变量就可以包括很多了,例如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。
常规步骤
Regression问题的常规步骤为:
1.寻找h函数(即hypothesis);
2.构造J函数(损失函数);
3.想办法使得J函数最小并求得回归参数(θ)
构造预测函数h
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
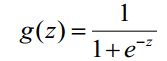
Sigmoid 函数在有个很漂亮的“S”形,如下图所示(引自维基百科):
下面左图是一个线性的决策边界,右图是非线性的决策边界。
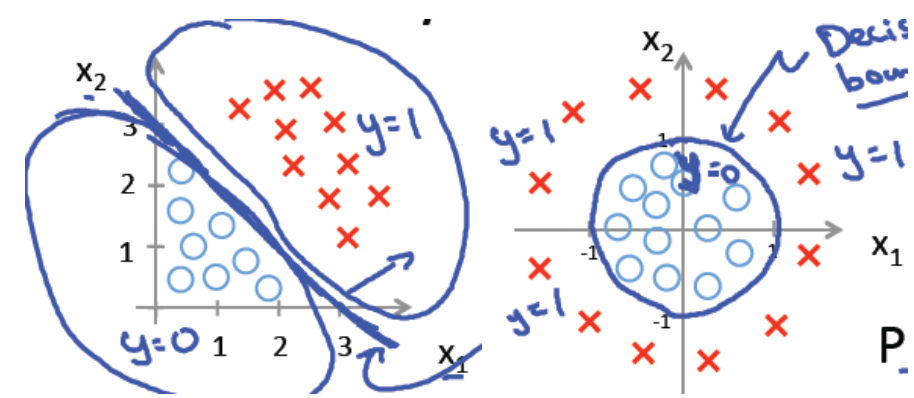
对于线性边界的情况,边界形式如下:
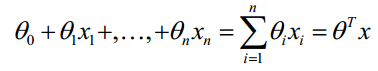
构造预测函数为:
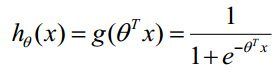
函数
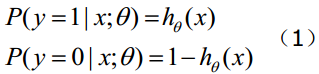
构造损失函数J
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
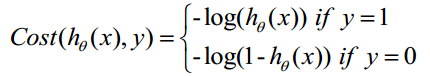
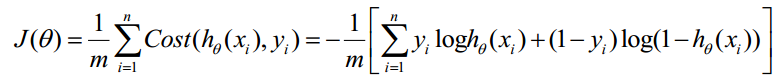
下面详细说明推导的过程:
(1)式综合起来可以写成:
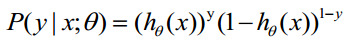
取似然函数为:

对数似然函数为:
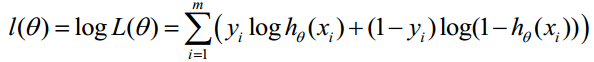
最大似然估计就是求使取最大值时的lθ其实这里可以使用梯度上升法求解,求得的Jθ就是要求的最佳参数。但是,在Andrew Ng的课程中将取为下式,即:
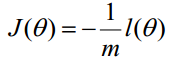
因为乘了一个负的系数-1/m,所以取Jθ最小值时的θ为要求的最佳参数。
梯度下降法求的最小值
θ更新过程:
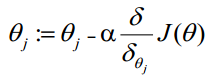
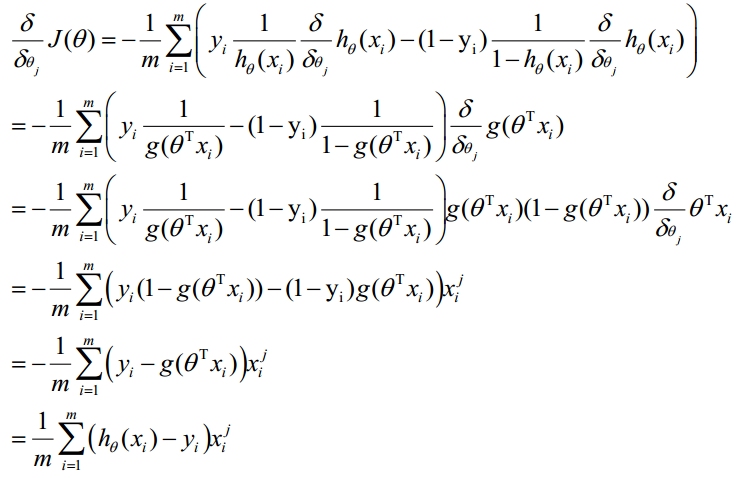
θ更新过程可以写成:
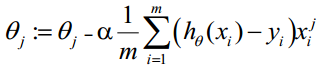
向量化Vectorization
Vectorization是使用矩阵计算来代替for循环,以简化计算过程,提高效率。
如上式,Σ(…)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization。
下面介绍向量化的过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知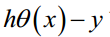
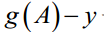
θ更新过程可以改为:
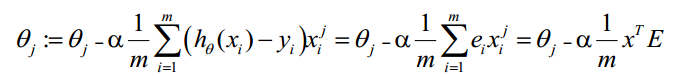
综上所述,Vectorization后θ更新的步骤如下:
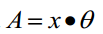
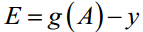
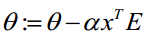
3.逐步回归(Stepwise Regression)
4.多元自适应回归样条(Multivariate Adaptive Regression Splines)
5.本地散点平滑估计(Locally Estimated Scatterplot Smoothing)
二.基于实例的算法:
基于实例的算法常常用来对决策问题建立模型,这样的模型常常先选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较。通过这种方式来寻找最佳的匹配。因此,基于实例的算法常常也被称为“赢家通吃”学习或者“基于记忆的学习”。常见的算法包括 k-Nearest Neighbor(KNN), 学习矢量量化(Learning Vector Quantization, LVQ),以及自组织映射算法(Self-Organizing Map , SOM).
1.k-Nearest Neighbor(KNN)
KNN最邻近规则,主要应用领域是对未知事物的识别,即判断未知事物属于哪一类,判断思想是,基于欧几里得定理,判断未知事物的特征和哪一类已知事物的的特征最接近;
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比(组合函数)。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
K-NN可以说是一种最直接的用来分类未知数据的方法。基本通过下面这张图跟文字说明就可以明白K-NN是干什么的
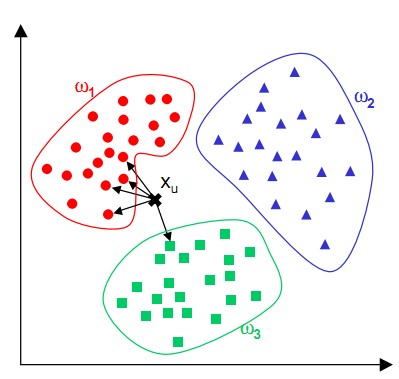
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
算法步骤:
step.1—初始化距离为最大值
step.2—计算未知样本和每个训练样本的距离dist
step.3—得到目前K个最临近样本中的最大距离maxdist
step.4—如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5—重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6—统计K-最近邻样本中每个类标号出现的次数
step.7—选择出现频率最大的类标号作为未知样本的类标号
2.自组织映射网络和学习向量量化网络
在人的视网膜、脊髓中有一种现象,当一个神经细胞兴奋后,会对周围神经细胞产生抑制作用。极端情况下,不允许其他细胞兴奋,这就是上文提到的学习规则中的胜者为王。
竞争学习算法分为3步:
(1).向量归一化
输入的模式向量X和竞争层各细胞的内星权向量Wj(j-1,2,…,m)都是进行归一化。并且每次迭代都要进行归一化操作。
(2).寻找获胜神经元
竞争层各细胞的内星权向量Wj(j-1,2,…,m)与输入向量X进行相似度比较,不论是用欧氏距离,还是夹角法,(由于X和W都已归一化,)得到的结论都是:与X点积最大的Wj对应的竞争层的细胞j中获胜者。
(3).网络输出权值调整
获胜神经元的输出为1,其他细胞的输出为0。
只有获胜细胞才可以调整其权向量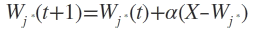
α是学习率,随着学习的进展应逐渐减小。
由于这是一种无导师的学习规则,所以迭代的终止条件是学习率衰减到0或某个预定的很小的数。
竞争学习的原理
获胜神经元调整权值的结果是使Wj进一步向当前的输入向量X靠近。当下次出现与X相像的输入模式时,上次的神经元更容易获胜。在反复的竞争学习中,竞争层的各神经细胞对应的权值逐渐被调整为输入样本空间的聚类中心。
三.决策树学习
1.分类及回归树(Classification And Regression Tree, CART)
2.随机森(Random forest)















 1268
1268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









