







Over the past 7 years, Netflix streaming has expanded from thousands of members watching occasionally to millions of members watching over two billion hours every month. Each time a member starts to watch a movie or TV episode, a “view” is created in our data systems and a collection of events describing that view is gathered. Given that viewing is what members spend most of their time doing on Netflix, having a robust and scalable architecture to manage and process this data is critical to the success of our business. In this post we’ll describe what works and what breaks in an architecture that processes billions of viewing-related events per day.
Use Cases
By focusing on the minimum viable set of use cases, rather than building a generic all-encompassing solution, we have been able to build a simple architecture that scales. Netflix’s viewing data architecture is designed for a variety of use cases, ranging from user experiences to data analytics. The following are three key use cases, all of which affect the user experience:
What titles have I watched?
Our system needs to know each member’s entire viewing history for as long as they are subscribed. This data feeds the recommendation algorithms so that a member can find a title for whatever mood they’re in. It also feeds the “recent titles you’ve watched” row in the UI. What gets watched provides key metrics for the business to measure member engagement and make informed product and content decisions.
Where did I leave off in a given title?
For each movie or TV episode that a member views, Netflix records how much was watched and where the viewer left off. This enables members to continue watching any movie or TV show on the same or another device.
What else is being watched on my account right now?
Sharing an account with other family members usually means everyone gets to enjoy what they like when they’d like. It also means a member may have to have that hard conversation about who has to stop watching if they’ve hit their account’s concurrent screens limit. To support this use case, Netflix’s viewing data system gathers periodic signals throughout each view to determine whether a member is or isn’t still watching.
Current Architecture
Our current architecture evolved from an earlier monolithic database-backed application (see
this QCon talk
or
slideshare
for the detailed history). When it was designed, the primary requirements were that it must serve the member-facing use cases with low latency and it should be able to handle a rapidly expanding set of data coming from millions of Netflix streaming devices. Through incremental improvements over 3+ years, we’ve been able to scale this to handle low billions of events per day.
Current Architecture Diagram
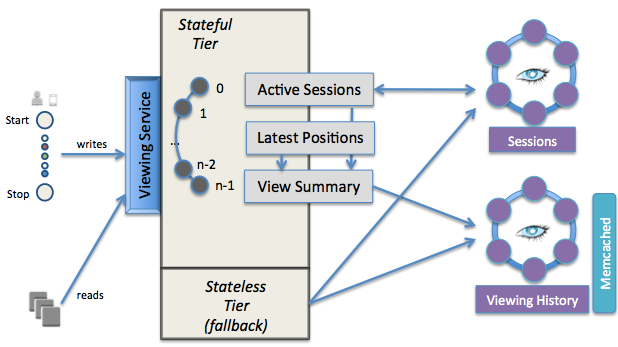
The current architecture’s primary interface is the viewing service, which is segmented into a stateful and stateless tier. The stateful tier has the latest data for all active views stored in memory. Data is partitioned into N stateful nodes by a simple mod N of the member’s account id. When stateful nodes come online they go through a slot selection process to determine which data partition will belong to them. Cassandra is the primary data store for all persistent data. Memcached is layered on top of Cassandra as a guaranteed low latency read path for materialized, but possibly stale, views of the data.
We started with a stateful architecture design that favored consistency over availability in the face of network partitions (for background, see the
CAP theorem
). At that time, we thought that accurate data was better than stale or no data. Also, we were pioneering running Cassandra and memcached in the cloud
so starting with a stateful solution allowed us to mitigate risk of failure for those components. The biggest downside of this approach was that failure of
a single stateful node would prevent 1/nth of the member base from writing to or reading from their viewing history.
After experiencing outages due to this design, we reworked parts of the system to gracefully degrade and provide limited availability when failures happened. The stateless tier was added later as a pass-through to external data stores. This improved system availability by providing stale data as a fallback mechanism when a stateful node was unreachable.
Breaking Points
Our stateful tier uses a simple sharding technique (account id mod N) that is subject to hot spots, as Netflix viewing usage is not evenly distributed across all current members. Our Cassandra layer is not subject to these hot spots, as it uses consistent hashing with virtual nodes to partition the data. Additionally, when we moved from a single AWS region to running in multiple AWS regions, we had to build a custom mechanism to communicate the state between stateful tiers in different regions. This added significant, undesirable complexity to our overall system.
We created the viewing service to encapsulate the domain of viewing data collection, processing, and providing. As that system evolved to include more functionality and various read/write/update use cases, we identified multiple distinct components that were combined into this single unified service. These components would be easier to develop, test, debug, deploy, and operate if they were extracted into their own services.
Memcached offers superb throughput and latency characteristics, but isn’t well suited for our use case. To update the data in memcached, we read the latest data, append a new view entry (if none exists for that movie) or modify an existing entry (moving it to the front of the time-ordered list), and then write the updated data back to memcached. We use an eventually consistent approach to handling multiple writers, accepting that an inconsistent write may happen but will get corrected soon after due to a short cache entry TTL and a periodic cache refresh. For the caching layer, using a technology that natively supports first class data types and operations like append would better meet our needs.
We created the stateful tier because we wanted the benefit of memory speed for our highest volume read/write use cases. Cassandra was in its pre-1.0 versions and wasn’t running on SSDs in AWS. We thought we could design a simple but robust distributed stateful system exactly suited to our needs, but ended up with a complex solution that was less robust than mature open source technologies. Rather than solve the hard distributed systems problems ourselves, we’d rather build on top of proven solutions like Cassandra, allowing us to focus our attention on solving the problems in our viewing data domain.
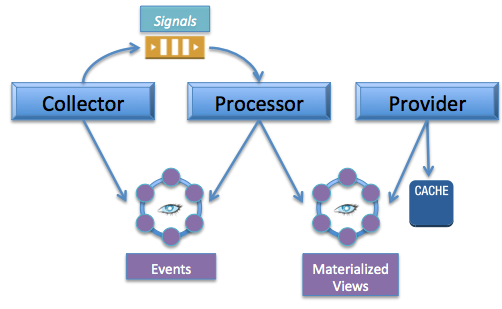
Next Generation Architecture
In order to scale to the next order of magnitude, we’re rethinking the fundamentals of our architecture. The principles guiding this redesign are:
-
Availability over consistency - our primary use cases can tolerate eventually consistent data, so design from the start favoring availability rather than strong consistency in the face of failures.
-
Microservices - Components that were combined together in the stateful architecture should be separated out into services ( components as services ).
-
Components are defined according to their primary purpose - either collection, processing, or data providing.
-
Delegate responsibility for state management to the persistence tiers, keeping the application tiers stateless.
-
Decouple communication between components by using signals sent through an event queue.
-
-
Polyglot persistence - Use multiple persistence technologies to leverage the strengths of each solution.
-
Achieve flexibility + performance at the cost of increased complexity .
-
Use Cassandra for very high volume, low latency writes. A tailored data model and tuned configuration enables low latency for medium volume reads.
-
-
Use Redis for very high volume, low latency reads. Redis’ first-class data type support should support writes better than how we did read-modify-writes in memcached.
-
Our next generation architecture will be made up of these building blocks:















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









