









这是一个拾遗系列, 觉得Java中有些比较有意思的点可以拿来记录一下 分享一下.更多拾遗系列文章
Abstract
半年前?, 对于从业Java快5年了,觉得自己已经比较了解HashMap了, 直到有一天去XX公司面试, 被问到
(1)HashMap为什么会导致100%? 我回答到因为在扩容过程中可能导致死循环而导致CPU高. 然后又被问到
(2)怎么导致的死循环? 额 这个具体就不知道了
(3) 然后惊呆的是面试官告诉过,在新版JDK里面是不会导致死循环的. 😂😂😂 这就相当尴尬了. 自己从来没听说过的…
所以就有了这个拾遗文章来"希望"解释清楚为啥.
实例代码
后面我们都会用下面的代码来测试是否会导致CPU 100%. 创建很多个任务来同时对map进行插入.
package datastructure;
import java.util.HashMap;
import java.util.UUID;
import java.util.concurrent.CountDownLatch;
/**
* 演示HashMap可能导致的CPU 100%的问题
*/
public class HashMapDeadLoop {
public static void main(String[] args) throws InterruptedException {
final HashMap m = new HashMap(2); // 尽量初始化一个小容量的
final int count = 10000;
final CountDownLatch finished = new CountDownLatch(count);
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < count; i++) {
final int j = i;
new Thread(new Runnable() {
@Override
public void run() {
m.put(UUID.randomUUID().toString(), "val" + j);
finished.countDown();
System.out.println("finished - " + j);
}
}, "put-" + i).start();
}
}
}).start();
// 新启动一个线程来打印剩余多少个没有完成插入...
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
System.out.println("Current left - " + finished.getCount());
if (finished.getCount() == 0) {
break;
}
try {
Thread.sleep(200);
}
catch (InterruptedException e) {
}
}
}
}).start();
finished.await();
}
}
当能够正常退出时✔️, 如下:
 如果不能正常退出时❌, 如下: 一直剩余3个没有插入成功. (每次运行可能剩余个数不一样)
如果不能正常退出时❌, 如下: 一直剩余3个没有插入成功. (每次运行可能剩余个数不一样)
 任务管理器里面看看 正好~300% cpu (3个线程各占100%):
任务管理器里面看看 正好~300% cpu (3个线程各占100%):

测试结果
虽然我们知道多线程很难验证其正确性或者证明它有问题, 但我还是测试了多次结果如下版本:
JDK1.7_80 -> 每次都出现100%
JDK1.8_102 -> 没有出现.
JDK1.8_202 -> 没有出现.
HashMap 如何扩容
因为JDK1.7和 1.8的HashMap存储结构有些不同, 所以分开来说.
HashMap 存储结构
JDK 1.7如下:
 JDK1.8 跟前面的差不多. 但是可以想象如果一直有bucket位置一样的节点存在的话, 那么整个链表就会很长, 所以JDK1.8中加入了, 如果单个bucket的节点大于8个就转化为一个红黑树来降低查询和插入时间. 当然它也会自动变回linked list如果节点太少的时候.
JDK1.8 跟前面的差不多. 但是可以想象如果一直有bucket位置一样的节点存在的话, 那么整个链表就会很长, 所以JDK1.8中加入了, 如果单个bucket的节点大于8个就转化为一个红黑树来降低查询和插入时间. 当然它也会自动变回linked list如果节点太少的时候.

如何扩容
因为这个问题跟是否是红黑树没有关系, 所以我们还是以linked list的方式来分析.
JDK 1.7的扩容方法(类HashMap中):
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { // 外层循环
while(null != e) { // 内层循环
Entry<K,V> next = e.next; // line 1
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // line 2
newTable[i] = e; // line 3
e = next; // line 4
}
}
}
简单来说一次正常的transfer会重新分配table index, 并且会逆序. 可以看到有2个循环. 外层循环负责遍历老table的每一个bucket. 而内层循环负责遍历某个bucket里面的每个元素.
还是前面的例子, 执行每一步之后的过程如下:

多线程状态下的扩容
假设有2个线程都想尝试扩容如下:
 可以看到上面第一次出现死循环的地方:
可以看到上面第一次出现死循环的地方:
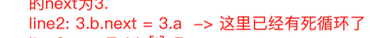
这里会导致get方法死循环. 而下面的:

则会导致transfer也就是当前的put (也就是resize方法死循环)了.
新版本JDK是否有问题?
如果单纯从前面的测试来看似乎是没有问题了, 那么实际是否如此呢?
我们看看新版JDK的扩容方法:
 可以看到很关键的一点, 链表的顺序并没有被逆序. 大致上来说, 就是因为扩容会扩容2倍. 所以分别采用2个指针low 和 high来指示扩容后的对象应该放在newTable的哪个bucket里面. 要么是原有的index j 要么是 index j + oldCap. (通过位与来决定)
可以看到很关键的一点, 链表的顺序并没有被逆序. 大致上来说, 就是因为扩容会扩容2倍. 所以分别采用2个指针low 和 high来指示扩容后的对象应该放在newTable的哪个bucket里面. 要么是原有的index j 要么是 index j + oldCap. (通过位与来决定)
举例来说:
某个map, size为8(2的幂次). 然后bucket index为5的bucket中, 有hashcode为5 (2进制:00101), 13 (2进制: 01101), 21 (2进制: 10101)可以看到低3位都为101.
如果要扩容成16, 那么我们知道5和21都应该被放到index为5的bucket. 而13应该被放到index为13 (也就是oldIndex+cap= 5+ 8)的bucket中. 而且你发现这个不需要逆序了.
最终发现JDK在这个bugid中fix了这个问题: https://bugs.openjdk.java.net/browse/JDK-8012913
原意是为了让Iterator返回更加一致的视图, 而不是可能被逆序的视图.
参考链接
- jdk8 源码: https://github.com/AdoptOpenJDK/openjdk-jdk8u
- https://www.cnblogs.com/softidea/p/4376962.html
- https://stackoverflow.com/questions/45404580/hashmap-resize-method-implementation-detail















 1900
1900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









