







关注公众号:【离心计划】,一起逃离舒适圈
Redis专栏合集
【专栏】基础篇04| Redis 该怎么保证数据不丢失(上)
【专栏】基础篇05| Redis 该怎么保证数据不丢失(下)
前言
上一节我们详细地介绍了Redis的几种集群模式,这一节我们尝试动手搭建一下哨兵和Redis Cluster模式,实际感受一下这两种集群模式。
环境搭建
All in docker,使用docker-compose容器编排工具管理,方便演示
安装docker
curl -sSL https://get.daocloud.io/docker | sh// 验证sudo docker -v
安装docker-compose
sudo curl --proxy "https://ntproxy.qa.nt.ctripcorp.com:8080" -L "https://github.com/docker/compose/releases/download/v2.2.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-composesudo chmod +x /usr/local/bin/docker-composesudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose// 验证sudo docker-compose version
主从+哨兵
由于哨兵之间需要进行投票选举,因此我们基于docker需要容器之间通信,我们统一使用虚拟网卡分配新的ip给每个容器,不走宿主机网卡,所以我们先创建虚拟网卡:
docker network create redis-cluster查看网卡信息
sudo docker network inspect redis-cluster然后我们先部署一主两从,编写docker-compose.yml,文件主要是创建了三个实例容器,并开启aof,分别映射到主机6379到6381三个端口上,并通过刚才创建的虚拟网卡进行通信和和分配ip
version: '1.0'services:master:image: rediscontainer_name: redis-masterrestart: alwayscommand: redis-server --appendonly yesports:- 6379:6379slave1:image: rediscontainer_name: redis-slave-1restart: alwayscommand: redis-server --slaveof redis-master 6379 --appendonly yesports:- 6380:6379slave2:image: rediscontainer_name: redis-slave-2restart: alwayscommand: redis-server --slaveof redis-master 6379 --appendonly yesports:- 6381:6379networks:default:external:name: redis-cluster
然后启动容器
sudo docker-compose up -d//查看启动容器docker-compose ps
我们先验证一下主从复制是否正常,先进入master容器,set一个key然后到从库6380上查看下是否存在这个key
sudo docker exec -it redis-master /bin/bashredis-cli127.0.0.1:6379> set name masonOK127.0.0.1:6379> get name"mason"redis-cli -h 10.130.45.51 -p 638010.130.45.51:6380> get name"mason"
验证没问题后我们开始部署哨兵实例,哨兵是特殊的Redis实例,因此我们先下载配置文件,并修改其中关于监控目标的实例地址信息,其中hostip设置成主机ip或者设置成主库在虚拟网卡上的ip也是可以的
wget http://download.redis.io/redis-stable/sentinel.conf##修改配置sentinel monitor mymaster <hostip> 6379 2
然后创建一个sentinel文件夹,将这个配置文件复制三份,sentinel1.conf、sentinel2.conf、sentinel3.conf,在sentinel文件夹下创建docker-compose.yml(注意不要和上面的主从yml文件放在一起),这边我们创建三个哨兵实例
version: '1.0'services:sentinel1:image: rediscontainer_name: redis-sentinel-1restart: alwaysports:- 26379:26379command: redis-sentinel /usr/local/etc/redis/sentinel.confvolumes:- ./sentinel1.conf:/usr/local/etc/redis/sentinel.confsentinel2:image: rediscontainer_name: redis-sentinel-2restart: alwaysports:- 26380:26379command: redis-sentinel /usr/local/etc/redis/sentinel.confvolumes:- ./sentinel2.conf:/usr/local/etc/redis/sentinel.confsentinel3:image: rediscontainer_name: redis-sentinel-3ports:- 26381:26379command: redis-sentinel /usr/local/etc/redis/sentinel.confvolumes:- ./sentinel3.conf:/usr/local/etc/redis/sentinel.confnetworks:default:external:name: redis-cluster
然后我们启动这三个实例
sudo docker-compose up -d可以选一个哨兵容器id查看下启动日式
sudo docker logs <containerId>
现在我们已经分配了主从和哨兵,可以看看虚拟网卡上的分配情况
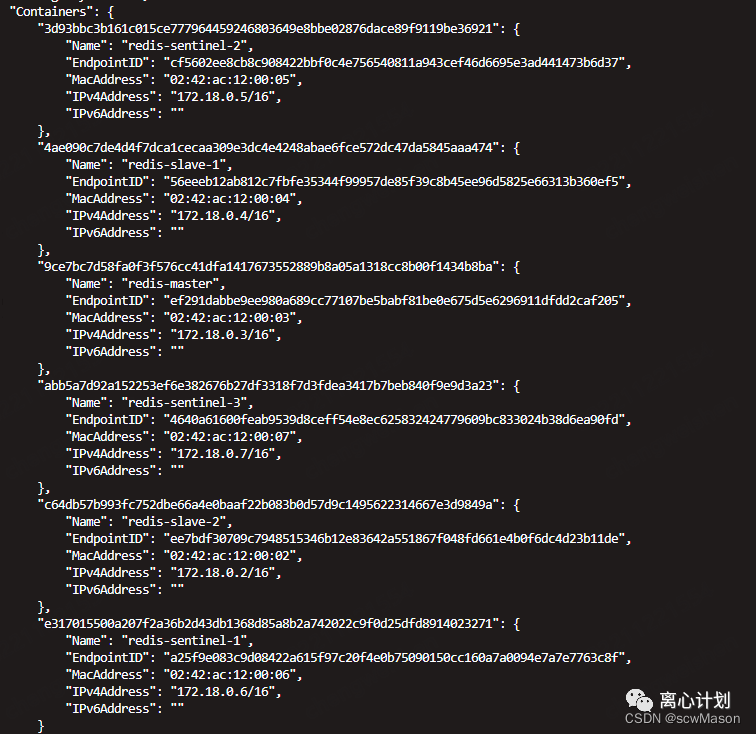
然后我们就要验证一下主库下线后的主从切换,我们直接停掉主实例的容器,然后观察哨兵的日志。
sudo docker stop redis-mastersudo docker logs <containerId>
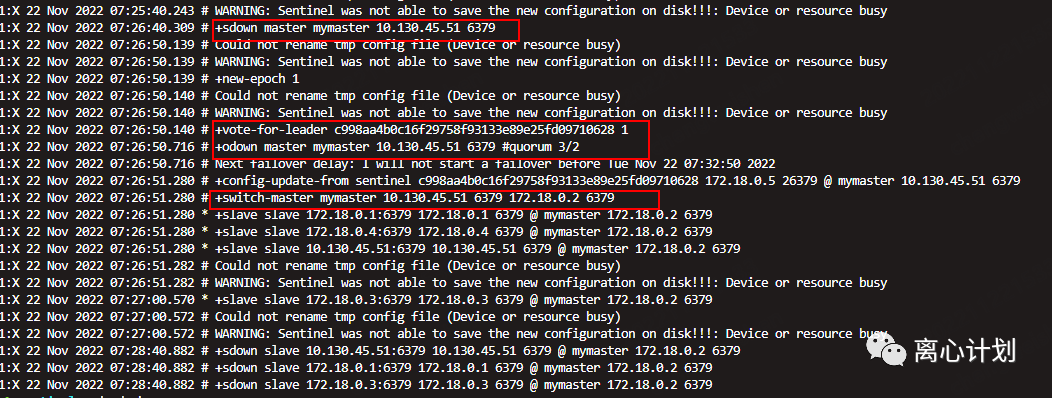
我们可以看到sdown表示主观下线,主观下线后收集了其他哨兵的判断,odown表示客观下线,3/2表示投票超过了一半。vote-for-leader表示在进行哨兵leader选举,switch-master表示切换新主库的目标,我们可以看到选举了172.18.0.2为新主库,为了验证我们再次进入新主库容器,重复上面主从复制的验证,就可以验证是否切换正常。
sudo docker exec -it redis-slave-2 /bin/bash
root@c64db57b993f:/data# redis-cli
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379>
root@c64db57b993f:/data# redis-cli -h 172.18.0.4 -p 6379
172.18.0.4:6379> get age
"18"Redis Cluster
cluster模式属于分片模式,我们直接编写shell脚本来帮助我们部署docker,首先我们还是创建一个配置模板:redis-cluster.templ
#端口port ${PORT}#非保护模式protected-mode no#启用集群模式cluster-enabled yescluster-config-file nodes.conf#超时时间cluster-node-timeout 5000#集群各节点IP地址cluster-announce-ip 10.130.45.51#集群节点映射端口cluster-announce-port ${PORT}#集群总线端口cluster-announce-bus-port 1${PORT}#开启aof持久化策略appendonly yes#后台运行#daemonize yes#进程号存储pidfile /var/run/redis_${PORT}.pid
然后是shell脚本clusterStart.sh,主要就是批量创建配置文件以及集群实例
start_port=6379;
end_port=6393;
for port in $(seq $start_port $end_port);
do
mkdir -p /home/redis/node-${port}/conf
PORT=${port} envsubst < ./redis-cluster.templ > /home/redis/node-${port}/conf/redis.conf
mkdir -p /home/redis/node-${port}/data;
done
for port in $(seq $start_port $end_port);
do
docker run -it -d -p ${port}:${port} -p 1${port}:1${port} \
--privileged=true -v /home/redis/node-${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \
--privileged=true -v /home/redis/node-${port}/data:/data \
--restart always --name redis-${port} --net redis-cluster \
--sysctl net.core.somaxconn=1024 redis redis-server /usr/local/etc/redis/redis.conf
done顺便写一个clusterStop.sh批量停止
start_port=6379;
end_port=6393;
for port in $(seq $start_port $end_port);
do
docker stop redis-${port}
docker rm redis-${port}
done我们配置三主+两从模式,首先进入一个实例容器,并执行cluster命令进行主从分配
sudo docker exec -it redis-6379 bashredis-cli --cluster create 172.18.0.2:6379 172.18.0.3:6380 172.18.0.4:6381 172.18.0.5:6382 172.18.0.6:6383 172.18.0.7:6384 172.18.0.8:6385 172.18.0.9:6386 172.18.0.10:6387 --cluster-replicas 2
cluster nodes 查看节点信息

然后主从复制的测试和我们上面哨兵一样,主从切换也是选择一台master并停止该容器
sudo docker stop redis-6380sudo docker exec -it redis-6379 bash

发现redis-6380主动被我们下线后,切换了6385这台之前的从库作为了新主库,可以再进行一下主从验证。
小结
这一节我们基于docker搭建了两种集群模式,还剩下像codis这些中心化集群模式,大家感兴趣可以自己尝试去动手搭建使用一下。当然,真正的生产集群下会有更多异常的问题出现,比如cluster模式由于去中心化每个实例时间需要保持频繁的消息同步,因此当集群数量偏大时就会有一定的通信开销;或者说由于实例假死导致的脑裂等问题都是由于引入了集群复杂度导致的,这些问题都值得思考,后续有机会也会在专栏中详解。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









