







计算机类PDF整理:【详细!!】计算机类PDF整理
Redis专栏合集
【专栏】基础篇04| Redis 该怎么保证数据不丢失(上)
【专栏】基础篇05| Redis 该怎么保证数据不丢失(下)
【专栏】实践篇08| All in docker!动手搭建Redis集群
欢迎关注公号:【离心计划】,逃离技术舒适圈
前言
在平常工作中,我们使用Redis作为缓存时,只有两种模式:只读缓存和读写缓存,两者的区别就是是否接收写请求。而无论是哪种方式,因为缓存和DB的同时存在,我们的基本工作模式就是:请求来了先去缓存中拿,如果缓存中有数据就返回,没有数据就查DB。而查完DB后读写缓存的做法是update缓存数据,只读缓存的做法是delete缓存数据。是update还是delete是两者的手法上的基本区别。而当更新请求来的时候,比如库存加减,那么读写缓存就是要做两步:update缓存、update数据库,只读缓存则是:delete缓存、update数据库。
因此我们今天讨论的问题就是在两种模式下,数据的增删改查出现缓存与数据库数据不一致的问题,为了更清楚,我们只拿只读缓存举例,最后对比一下两者即可。
操作失败导致的不一致
只读缓存下我们做的两步分别是delete缓存和update数据库,那么两步操作必然有个先后顺序,如果先删除缓存再更新数据库,那么如果删除缓存成功,更新数据库失败,那么就会导致下一次读取数据库会读到旧值导致数据不一致;如果删除缓存失败,更新数据库成功,那么请求依旧会读到缓存中的旧值导致数据不一致。而交换删除缓存和更新数据库的位置,也是一样的情况,因此我们得出结论:操作失败会导致数据不一致问题。
| 时间 | 线程A(写) | 线程B(读) |
| t1 | 删除缓存 | |
| t2 | 更新DB(失败) | |
| t3 | 缓存缺失查询DB | |
| t4 | 更新缓存,脏数据 |

那么操作失败,在我们代码中属于异常捕获的一部分,我们常见的机制就是补偿,这边的补偿就是重试。重试我们需要考虑两个问题
-
同步还是异步
-
重试多少次
同步重试意味着这次请求必然会更耗时,而且重试的次数比较多时耗时更严重,因此我们毅然决然采用异步重试。那么异步重试我们是起异步线程重试么,为了保证最终的一致性,异步线程还得保证一直重试直到成功,如果此时应用重启那么这条重试就永远失效了。这里存在本质的问题就是,“重试”这个操作需要被可靠执行,所谓可靠执行就是操作一旦生成不会消失,并且一定会被执行直到成功。
所以,消息队列就是符合我们的场景,我们可以在操作失败后生产一条消息告诉消费者需要重试,因为消息队列保证了消息的可靠投递与可靠消费,它具有两个特性:
-
消息一旦生产,只有被所有消费者消费成功后才会删除
-
消息只有被消费成功后才会返回ack,否则一直会投递给消费者
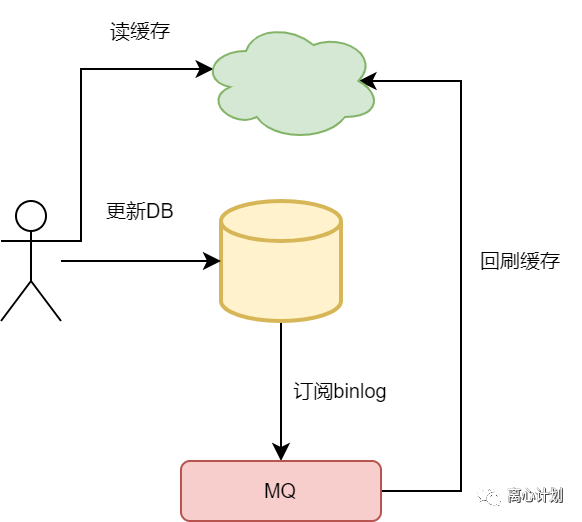
另外,还有一种异步策略,是将消息机制下沉到DB层,也就是利用一些中间件比如canel订阅Mysql binlog这种方式,这样只要写数据库成功了,就能订阅到binlog,消费者只要刷新缓存就行了。这种方案的优势在于,应用层不用主动发消息,毕竟发消息也有可能发送失败,将这种异常问题留给中间件,应用层只用关心写入DB是否成功,成功就正常进行,不成功也没有缓存数据一致性问题,直接报错就可以或者有其他降级策略。
并发导致的不一致
我们这边只考虑特殊的读写并发,由于读读并发不会有问题,写写并发和读写并发是一样的逻辑,因此我们的前提是删除缓存与更新DB两步都能成功,由于不是原子操作导致的并发问题,现象就像下面这种情况(现象一)
| 时间 | 线程A(写) | 线程B(读) |
| t1 | 删除缓存 | |
| t2 | 缓存缺失,读取DB | |
| t3 | 更新DB | |
| t4 | 更新缓存 |
这样就会导致线程B更新的缓存值就是旧值,后续读到的都会是脏数据,当这种情况时我们可以在线程A更新完DB后过一小段时间再进行删除缓存,这样可以减少脏数据的影响时间,这种策略也叫延迟双删,当然其实并不建议采用这种方式,因为这种方案有个大问题就是延迟多久,固定的值在变化不断的场景下就显得心有余而力不足了。
当然,如果我们交换一下两步的顺序,先更新DB再删除缓存,那么情况就是如下:(现象二)
| 时间 | 线程A(写) | 线程B(读) |
| t1 | 更新DB | |
| t2 | 读取到旧值返回 | |
| t3 | 删除缓存 | |
| t4 | 第二次读刷新缓存 |
这样的问题是,线程B在t2时间内会返回旧值,但是这种情况会马上被线程A通过删除缓存解决掉,因此影响的时间会比先删除缓存的策略更短。
除了这个时序,还有一种时序就是下面这样,就会导致缓存中存在的是旧值,这和先删除缓存是一样的问题,但是这种情况发生的概率会先删缓存小很多,因为首先要满足缓存正好过期,其次线程A更新DB与删除缓存的耗时要比线程B更新缓存还要快,这样下来概率就非常小了(现象三)
| 时间 | 线程A(写) | 线程B(读) |
| t1 | 缓存过期,查询DB | |
| t2 | 更新DB | |
| t3 | 删除缓存 | |
| t4 | 更新缓存 |
因此结合操作失败和读写并发,我们得出结论,先更新DB再删除缓存,并配合异步机制的方案更加稳定。
从缓存利用率考虑
这样看下来,写请求时有两种做法,删除缓存或者直接更新缓存,这两种做法看起来最终的效果一致,但是当我们从缓存利用率的角度出发,更新缓存会将所有更新DB的值都重新刷回缓存,如果大量的更新值都不会频繁读,那么这种策略就会导致大量的无效缓存,因此这种方案更适合读写流量差不多的情况下,写完后马上会被读的场景,否则,采用删除缓存的做法会更好,因为只有读时才会重刷缓存。
可见,具体采用怎样的策略还是需要看具体应用场景,没有银弹。
强一致性怎么做
上面我们讨论的数据一致性其实本质上是最终一致性,为了保证最后的结果是一致的就行,这种方案适合数据一致性不敏感的场景,但是非要做强一致性也就是不允许出现gap,那怎么做的呢?
这个问题其实其实就是解决并发问题,并且是在分布式环境下的话,就需要用到分布式锁方案,考虑到现象二和现象三(上面有标记),大致的流程如下,在更新DB与查询DB时加锁,主要就是为了防止出现二三两个现象。
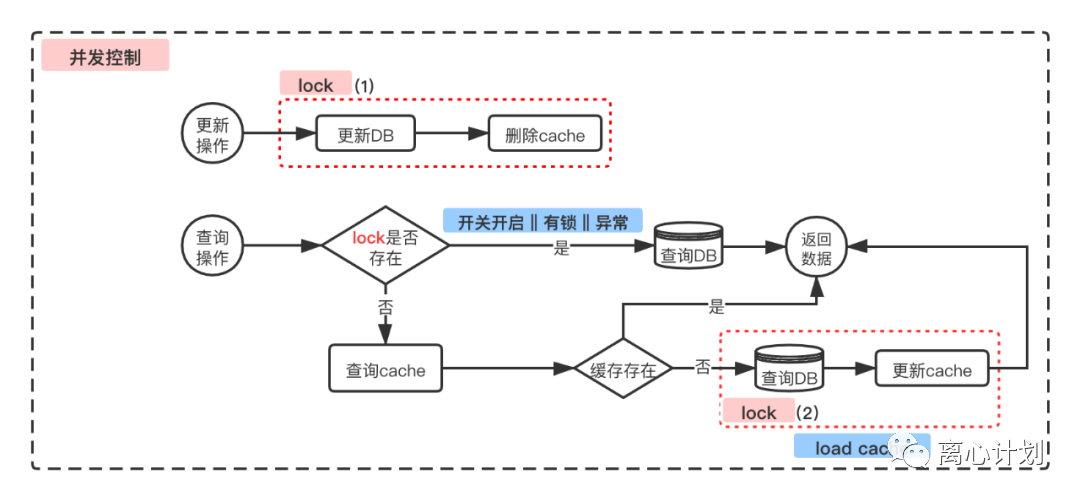
(图片引用自《携程最终一致和强一致性缓存实践》,见引用)
当然,最后缓存强一致性引入的代价可能会导致性能上有所损耗,但是在缓存命中率高的情况下,依旧能够提升接口响应时间,减少一定的DB压力。这边推荐一种Redis分布式锁方案Redisson,大家感兴趣可以了解一下。
小结
这一节我们梳理了一下在,当我们为了提升接口性能,减少DB压力时,增加了旁路缓存,但是引入了新的中间件也引入了数据不一致的问题,如果业务允许,我们可以采用最终一致性方案;如果业务不允许,则需要强一致性方案。无论怎样,缓存依旧是一把利大于弊的双刃剑,其中的各种问题不容小觑,下一节我们会继续讨论一下缓存的各种异常情况以及常见的解决方案~
引用:
-
https://www.infoq.cn/article/hh4iouiijhwb4x46vxeo














 7170
7170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









