






 本文探讨了在微服务项目中,通过在SpringBoot后端和MySQL数据库中实施表格分片和数据库分片来解决随着用户基数增长导致的服务性能问题。作者详细描述了如何通过扩展Interceptor和使用AbstractRoutingDataSource进行路由,以提高查询效率。
本文探讨了在微服务项目中,通过在SpringBoot后端和MySQL数据库中实施表格分片和数据库分片来解决随着用户基数增长导致的服务性能问题。作者详细描述了如何通过扩展Interceptor和使用AbstractRoutingDataSource进行路由,以提高查询效率。
背景
微服务项目中通常包含各种服务。其中一项服务与存储用户相关的数据有关。我们使用Spring Boot作为后端,使用MySQL数据库。
目标
随着用户基数的增长,服务性能受到了影响,延迟也上升了。由于只有一个数据库和一张表,许多查询和更新由于锁异常返回错误。此外,随着数据库的规模不断扩大,性能进一步下降。因此,需要一种解决方案来处理不断增长的用户基数。
解决方案
表格分片
第一种方法是在单个数据库中创建多个类似的表,并使用user_id作为分片键。
我们在user_id列出现的任何地方创建了每个表的10个副本。因此,代码中需要进行两个更改。第一个更改是获取用户请求中的user_id。第二个更改是替换由Hibernate生成的查询中的表名。
关于第一个更改,获取user_id很容易,因为我们已经在请求标头中获取了user_id。
对于第二个更改,我们扩展了Hibernate的EmptyInterceptor类,并覆盖了onPrepareStatement方法,该方法在准备SQL字符串时调用。该方法有一个字符串参数,即SQL语句。该SQL语句中也包含表名。因此,这里根据请求头中存在的user_id用所需的表名替换表名。例如,如果user_id为77。我们取它10的模得到7,并将表名user_profile替换为user_profile_7,因为我们已经在数据库中创建了10个副本。以下是扩展EmptyInterceptor类的代码。如果您使用的是spring boot 3,则EmptyInterceptor已经弃用,你可以使用StatementInspector接口,并覆盖inspect方法,并将逻辑从onPrepareStatement方法移动到inspect方法中。
public class DynamicTableNameSharding extends EmptyInterceptor {
@Override
public String onPrepareStatement(String sql) {
// 替换表名
if (Boolean.parseBoolean(DatabaseEnvironment.TABLE_SHARDING_ENABLED.label)) {
for (String tableName : SHARDED_TABLES) {
if(sql.contains(tableName)) {
ServletRequestAttributes attr = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
String shardingNumber = getSharding(attr);
sql = sql.replace(tableName, tableName + shardingNumber);
// 这里不要使用break,因为一条查询可以包含多个表,因此需要更改所有已启用分片的表的名称
}
}
}
return super.onPrepareStatement(sql);
}
}在上述函数中,SHARDED_TABLES是已启用分片的表的列表。getSharding方法根据请求头中传递的用户ID返回分片号。由于在单个查询中存在多个表(例如连接或复杂逻辑),因此我们使用for循环来正确替换查询中出现的所有表。
我们还通过扩展DefaultVisitListener类,在某些操作中使用了JOOQ。
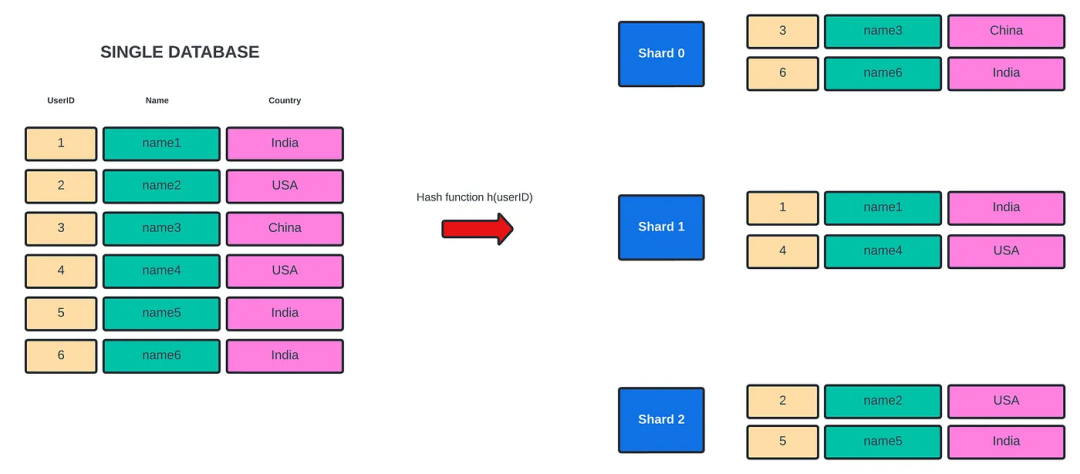
数据库分片
虽然通过表格分片提升了一定性能,但还有进一步改进的空间,我们进一步对数据库进行分片。与创建表副本类似,我们创建10个数据库服务器/实例的副本,每个服务器都有10个表的副本。总共有100个表副本。
因此,同时保持10个数据库服务器运行也需要路由查询到正确的数据库。
首先,在的Spring Boot应用程序中创建了10个数据源,每个数据源都有不同的数据库URL。现在,我们需要一种方法将数据库连接路由到正确的数据源。因此,我们使用了AbstractRoutingDataSource,它是一个路由getConnection()调用到其中一个多个目标数据源的抽象DataSource实现,这个目标数据源基于一个查找键。然后,我们重写了这个方法determineCurrentLookupKey。
因此,这个方法返回一个键,用于标识我们已定义的10个数据源中的一个特定数据源。因此,我们也更改了一些用于确定表和数据库的逻辑。我们使用个位数字标识数据库服务器,使用十位数来标识表。例如,用户ID为447将被路由到第7个数据库服务器及该服务器上的第4个表副本。因此,我们在10个数据库服务器上有100个表,这大大提高了性能。
结论
在这个例子中,我们既使用了表分片又使用了数据库分片。除此以外,我们可以进一步提高性能,方法是在单个服务器中增加更多的数据库,可能总共有1000个表的副本。















 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









