







GMP涉及思想:用较少的线程完成大量任务,利用多核并行实现高并发
先聊聊GM模型的问题
- 频繁的gorouting切换╯﹏╰后果:额外的开销
- 线程缓存与协程所需要的缓存比例差距太大,导致大量的内存浪费
- 系统调度会导致工作的线程频繁阻塞与解阻塞
- 使用全局互斥锁mutex处理整个gorouting的操作
再来解释GMP模型
由于GM模型存在的缺陷,导致性能不佳,因此急切的需要一种调度控制器来协调线程与协程
G:等待执行的任务(协程)
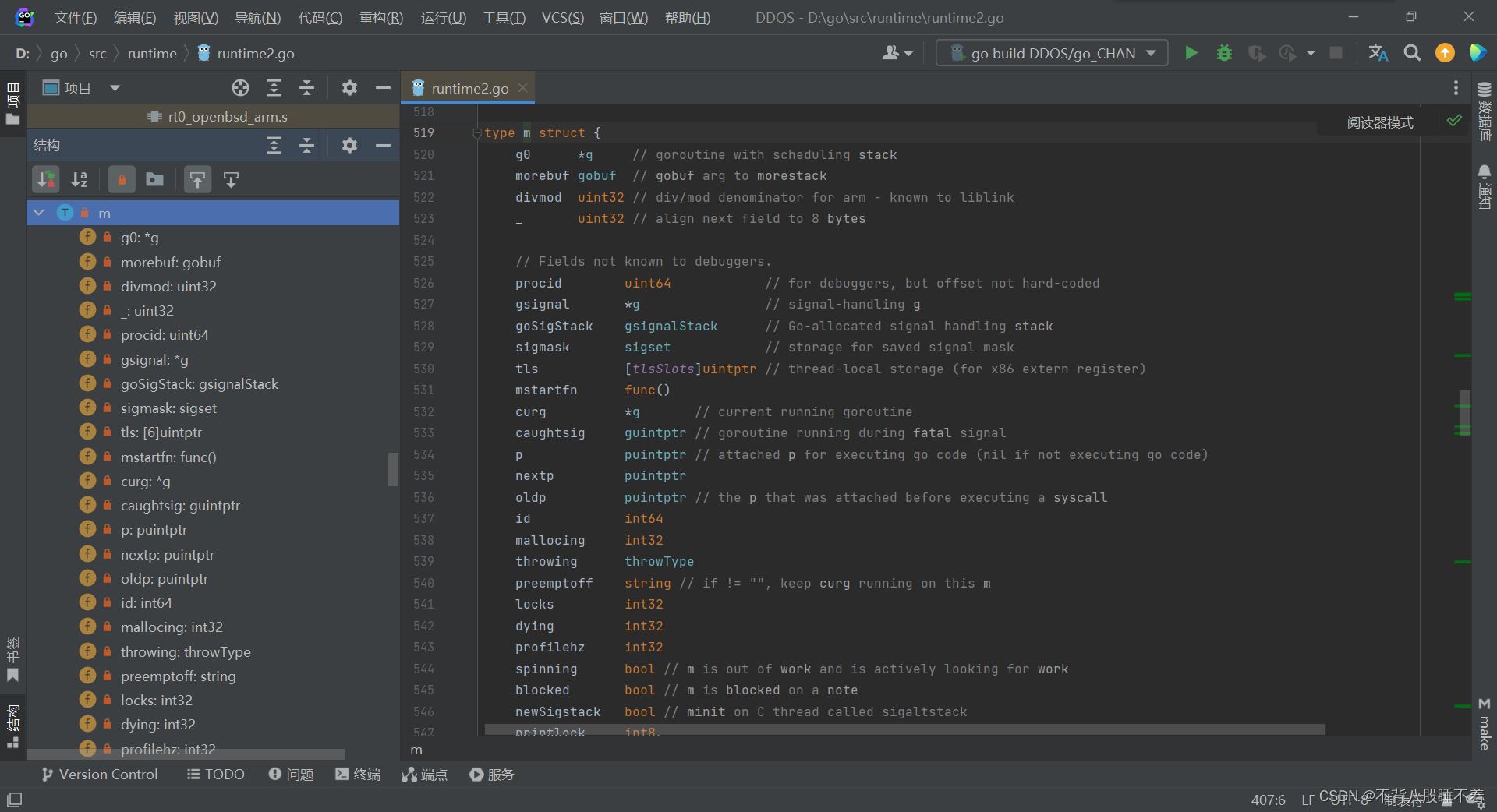
M:工作的线程
P:处理器(注意不是cpu)
三者关系
一个线程(M)工作时要与一个P进行绑定,假设现在我们启动三个线程和三个处理器
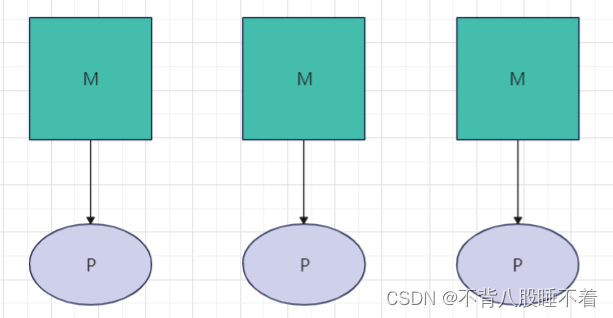
每个处理器都有自己的协程队列
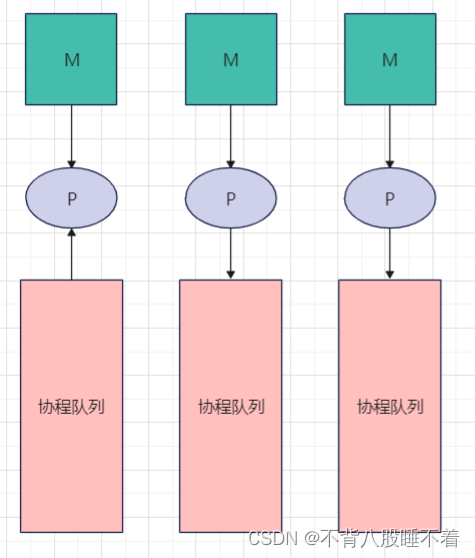
当有G(协程任务)需要处理时,会将G加入到P(处理器)的队列中
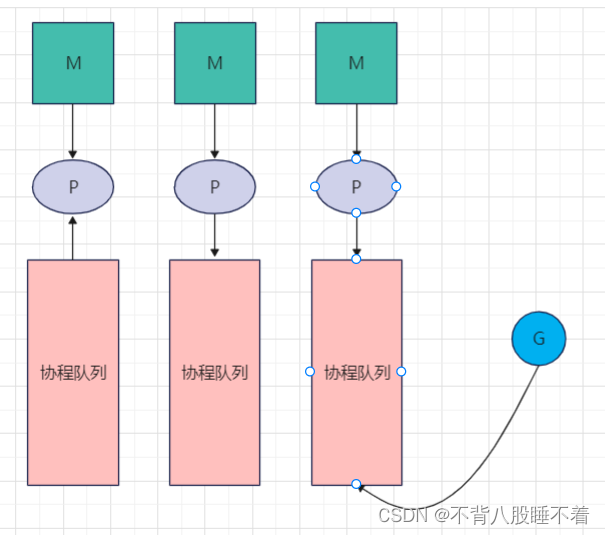
如果有大量的G那么队列迟早会满,此时会将G放入到全局队列中
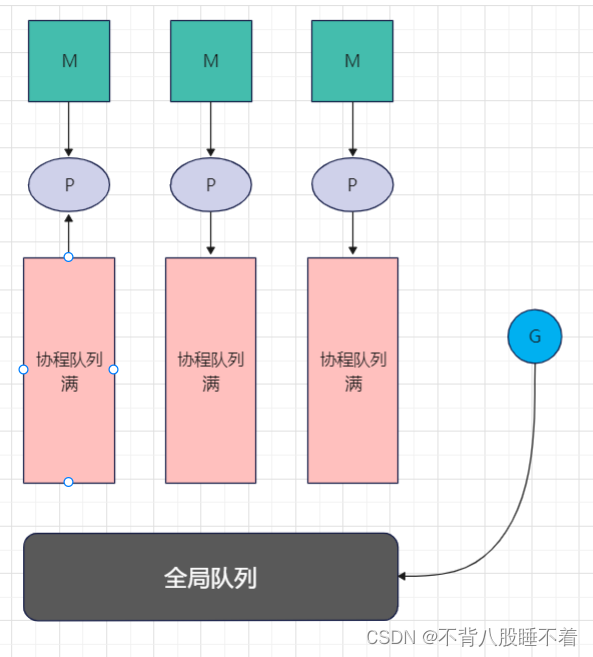
接下来聊聊取的顺序,M会疯狂的从协程队列中取G,如果自己的队列中没有了他会去全局队列中找G,如果全局队列中也没有他会去其他处理器的队列中抢
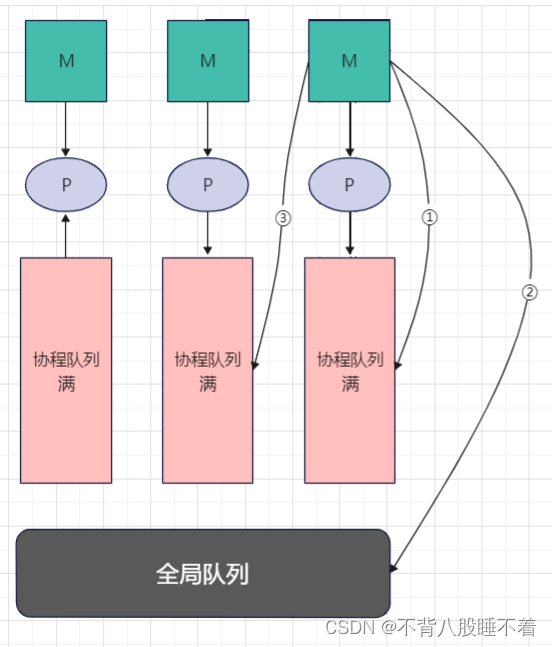
如果都没有取到,M会选择与P断开连接去休息
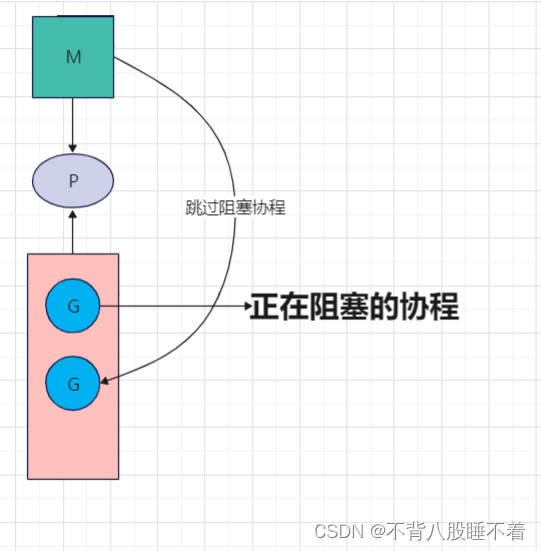
上面提到的问题中,我们并没有阐述当一个协程阻塞时的处理方式,当一个协程阻塞时,M不会等待,M会跳过该协程去执行其他协程
系统调用(Syscall)
这个定义不明白的可以去百度,大概意思是操作系统提供给用户的用来操做系统内核的函数接口,看下图应该不难理解
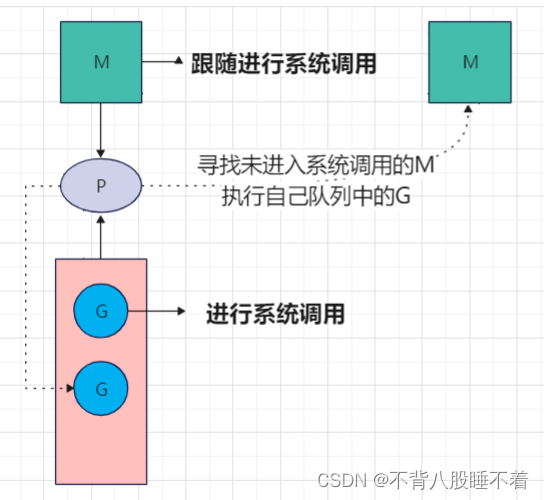
为什么要说系统调用,如果G进行了系统调用,那么M也会进入系统调用,此时P不会傻傻的等待,而会找其他的M执行自己队列中的G(此时有两种解决方式,要么解阻塞,要么就自旋也就是下面的方式)
感兴趣的童鞋也可以去看看源码,这里我浅浅的解一下图
这个是G的结构体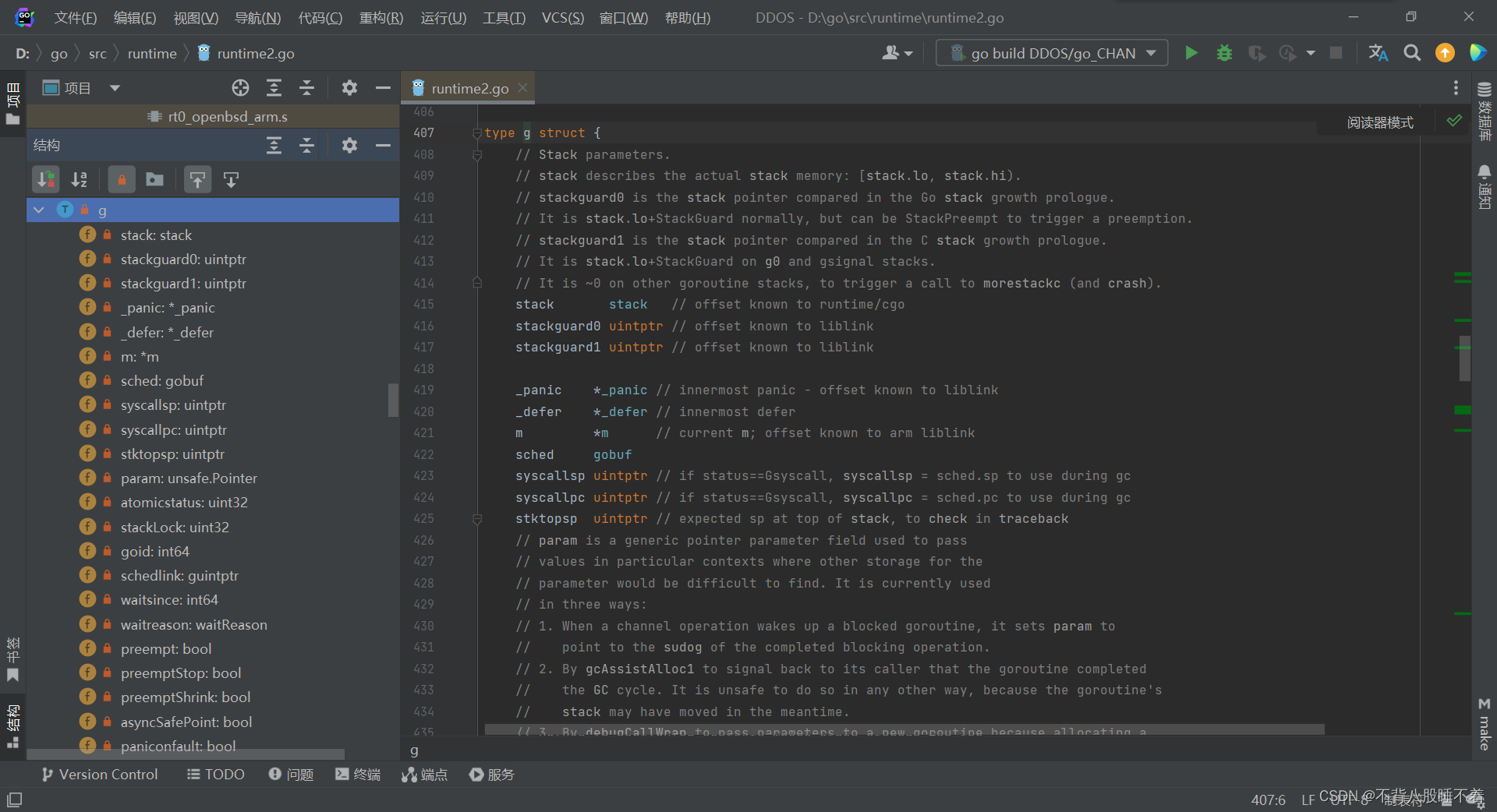
这个是M的结构体
这个是P的结构体
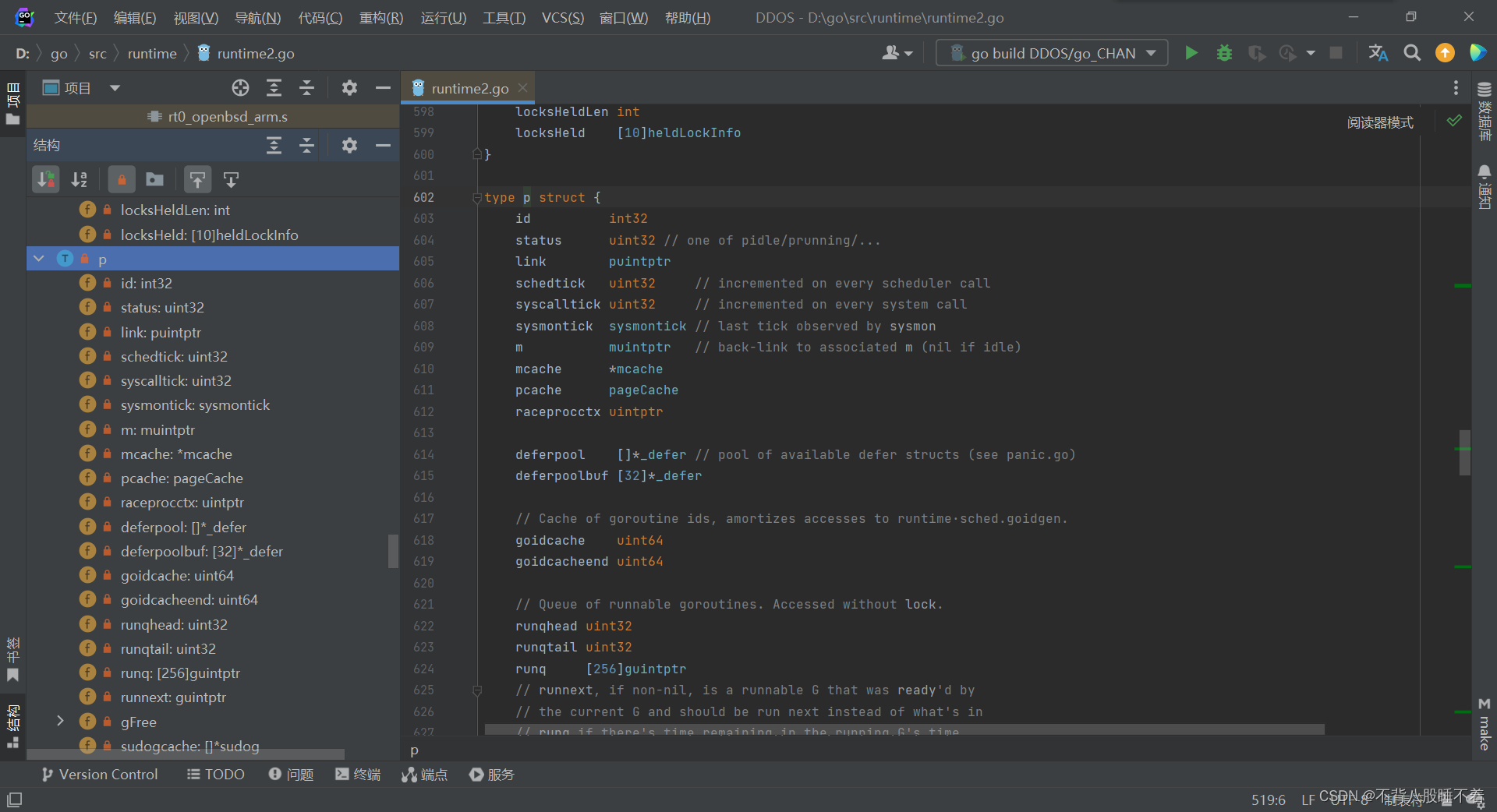
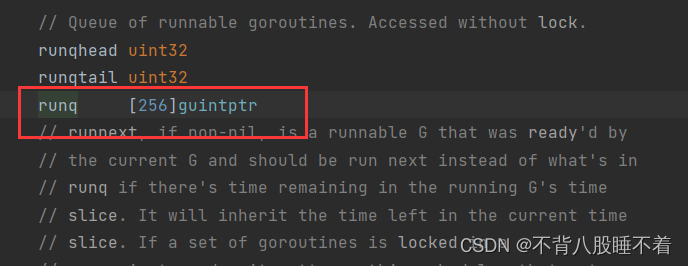
最后一个小细节,P的队列长度为256
20221120改
之前考虑不足,并没有思考一下问题
上面我们知道P的队列长度为256,那么最多可以用多少个P、多少个M,我们可不可以通过设置去改变呢?
1、首先M、P的数量关系不是绝对的1:1,当有一个G阻塞时,上文提到M也会跟着阻塞,那么就有可能创建新的M 继续执行 P队列中的 G
2、最多有多少个P? 这个是可以设置的,我们通过 $GOMAXPROCS查看 、设置
3、M也就是线程,最大值是10000
















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











