







kvm性能优化方案
kvm性能优化,主要集中在cpu、内存、磁盘、网络,4个方面,当然对于这里面的优化,也是要分场景的,不同的场景其优化方向也是不同的,下面具体聊聊这4个方面的优化细节。
cpu
在介绍cpu之前,必须要讲清楚numa的概念,建议先参考如下两篇文章
查看cpu信息脚本:
- #!/bin/bash
- # Simple print cpu topology
- # Author: kodango
- function get_nr_processor()
- {
- grep '^processor' /proc/cpuinfo | wc -l
- }
- function get_nr_socket()
- {
- grep 'physical id' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}' | wc -l
- }
- function get_nr_siblings()
- {
- grep 'siblings' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}'
- }
- function get_nr_cores_of_socket()
- {
- grep 'cpu cores' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}'
- }
- echo '===== CPU Topology Table ====='
- echo
- echo '+--------------+---------+-----------+'
- echo '| Processor ID | Core ID | Socket ID |'
- echo '+--------------+---------+-----------+'
- while read line; do
- if [ -z "$line" ]; then
- printf '| %-12s | %-7s | %-9s |\n' $p_id $c_id $s_id
- echo '+--------------+---------+-----------+'
- continue
- fi
- if echo "$line" | grep -q "^processor"; then
- p_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- if echo "$line" | grep -q "^core id"; then
- c_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- if echo "$line" | grep -q "^physical id"; then
- s_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- done < /proc/cpuinfo
- echo
- awk -F: '{
- if ($1 ~ /processor/) {
- gsub(/ /,"",$2);
- p_id=$2;
- } else if ($1 ~ /physical id/){
- gsub(/ /,"",$2);
- s_id=$2;
- arr[s_id]=arr[s_id] " " p_id
- }
- }
- END{
- for (i in arr)
- printf "Socket %s:%s\n", i, arr[i];
- }' /proc/cpuinfo
- echo
- echo '===== CPU Info Summary ====='
- echo
- nr_processor=`get_nr_processor`
- echo "Logical processors: $nr_processor"
- nr_socket=`get_nr_socket`
- echo "Physical socket: $nr_socket"
- nr_siblings=`get_nr_siblings`
- echo "Siblings in one socket: $nr_siblings"
- nr_cores=`get_nr_cores_of_socket`
- echo "Cores in one socket: $nr_cores"
- let nr_cores*=nr_socket
- echo "Cores in total: $nr_cores"
- if [ "$nr_cores" = "$nr_processor" ]; then
- echo "Hyper-Threading: off"
- else
- echo "Hyper-Threading: on"
- fi
- echo
- echo '===== END ====='
相信通过上面两篇文章,基本已经可以搞清楚node、socket、core、logic processor的关系,可以知道内存、l3-cache、l2-cache、l1-cache和cpu的关系。
针对kvm的优化,一般情况,都是通过pin,将vm上的cpu绑定到某一个node上,让其共享l3-cache,优先选择node上的内存,bind方法可以通过virt-manage processor里面的pinning动态绑定。这个绑定是实时生效的。
由于没有下载到speccpu2005,所以写了个大量消费cpu和内存的程序,来检验绑定cpu所带来的性能提升,程序如下:
- #include <stdio.h>
- #include <pthread.h>
- #include <stdlib.h>
- #define BUF_SIZE 512*1024*1024
- #define MAX 512*1024
- #define COUNT 16*1024*1024
- char * buf_1 = NULL;
- char * buf_2 = NULL;
- void *pth_1(void *data)
- {
- char * p1 = NULL;
- char * p2 = NULL;
- int value1 = 0;
- int value2 = 0;
- int value_total = 0;
- int i = 0;
- int j = 0;
- for (i = 0; i <=COUNT; i++) {
- value1 = rand() % (MAX + 1);
- value2 = rand() % (MAX + 1);
- p1 = buf_1 + value1*1024;
- p2 = buf_2 + value2*1024;
- for (j = 0; j < 1024; j++) {
- value_total += p1[j];
- value_total += p2[j];
- }
- }
- return NULL;
- }
- void *pth_2(void *data)
- {
- char * p1 = NULL;
- char * p2 = NULL;
- int value1 = 0;
- int value2 = 0;
- int value_total = 0;
- int i = 0;
- int j = 0;
- for (i = 0; i <=COUNT; i++) {
- value1 = rand() % (MAX + 1);
- value2 = rand() % (MAX + 1);
- p1 = buf_1 + value1*1024;
- p2 = buf_2 + value2*1024;
- for (j = 0; j < 1024; j++) {
- value_total += p1[j];
- value_total += p2[j];
- }
- }
- return NULL;
- }
- int main(void)
- {
- buf_1 = (char *)calloc(1, BUF_SIZE);
- buf_2 = (char *)calloc(1, BUF_SIZE);
- memset(buf_1, 0, BUF_SIZE);
- memset(buf_2, 0, BUF_SIZE);
- pthread_t th_a, th_b;
- void *retval;
- pthread_create(&th_a, NULL, pth_1, 0);
- pthread_create(&th_b, NULL, pth_2, 0);
- pthread_join(th_a, &retval);
- pthread_join(th_b, &retval);
- return 0;
- }
我的实验机器上,偶数cpu在node 0 上,奇数cpu在node 1上,vm有2个cpu,程序有2个线程,分别将vm绑定到8,9和10,12,通过time命令运行程序,time ./test,测试结果如下
- 8,9
- real 1m53.999s
- user 3m34.377s
- sys 0m3.020s
- 10,12
- real 1m25.706s
- user 2m49.497s
- sys 0m0.699s
这里需要注意的一点是,通过virt-manage pin cpu,仅仅进行cpu bind,会共享l3-cache,并没有限制一定用某一个node上的内存,所以仍然会出现跨node使用内存的情况。
内存
优化项包括EPT、透明大页、内存碎片整理、ksm,下面一个一个来介绍
EPT
针对内存的使用,存在逻辑地址和物理地址的转换,这个转换时通过page table来进行的,并且转换过程由cpu vmm硬件加速,速度是很块的。
但是引入vm之后,vm vaddr----->vm padddr--------->host paddr,首先vm需要进行逻辑地址和物理地址的转换,但是vm的物理地址还是host机的逻辑地址,需要再进行一次逻辑地址到物理地址的转换,所以这个过程有2次地址转换,效率非常低。
幸亏intel提供了EPT技术,将两次地址转换变成了一次。这个EPT技术是在bios中,随着VT技术开启一起开启的。
透明大页
逻辑地址向物理地址的转换,在做转换时,cpu保持一个翻译后备缓冲器TLB,用来缓存转换结果,而TLB容量很小,所以如果page很小,TLB很容易就充满,这样就很容易导致cache miss,相反page变大,TLB需要保存的缓存项就变少,减少cache miss。
透明大页的开启:echo always > /sys/kernel/mm/transparent_hugepage/enabled
内存碎片整理的开启:echo always> /sys/kernel/mm/transparent_hugepage/defrag
KSM
文章http://blog.chinaunix.net/uid-20794164-id-3601786.html,介绍的很详细,简单理解就是可以将host机内容相同的内存合并,节省内存的使用,特别是当vm操作系统都一样的情况,肯定会有很多内容相同的内存,开启了KSM,则会将这些内存合并为一个,当然这个过程会有性能损耗,所以开启与否,需要考虑使用场景,如果不注重vm性能,而注重host内存使用率,可以考虑开启,反之则关闭,在/etc/init.d/下,会有两个服务,服务名称为ksm和ksmtuned,都需要关闭。
磁盘
磁盘的优化包括:virtio-blk、缓存模式、aio、块设备io调度器
virtio
半虚拟化io设备,针对cpu和内存,kvm全是全虚拟化设备,而针对磁盘和网络,则出现了半虚拟化io设备,目的是标准化guest和host之间数据交换接口,减少交互流程和内存拷贝,提升vm io效率,可以在libvirt xml中设置,disk中加入<target dev='vda' bus='virtio'/>
缓存模式
从vm写磁盘,有3个缓冲区,guest fs page cache、Brk Driver writeback cache(qemu的cache)、Host FS page cache,在host上的设置,无法改变guest fs page cache,但是可以改变后面2个cache,缓存模式有如下5种,当采用Host FS page cache,会有一个写同步,会实时将host cache中的数据flush到磁盘上,当然这样做比较安全,不会丢失数据,但写性能会受到影响。具体模式见下图。
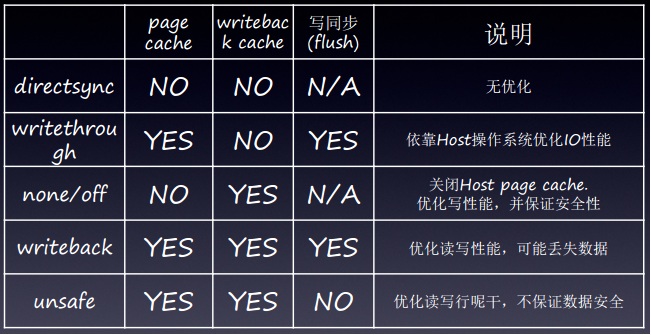
第1和第5种,都太极端了,很少会有人使用,常使用的是中间3种,其性能比较如下:
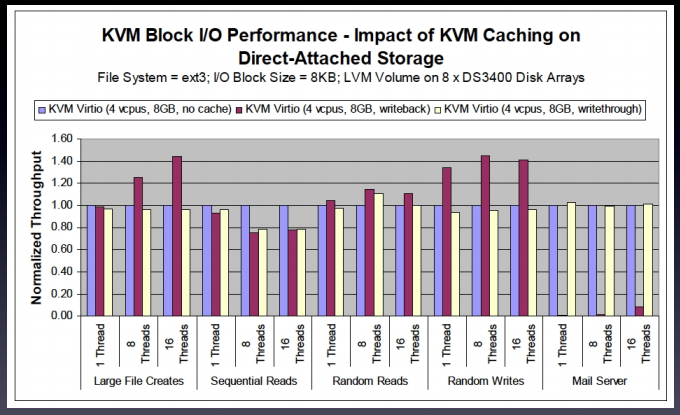
可以看出writeback mode在mail server这种小文件 高io的服务器上,其性能是很差的,none模式大部分情况要比writethrough性能稍好一点,所以选择none。
启用方式在libvirt xml disk中加入<driver name='qemu' type='qcow2' cache='none'/>
aio
异步读写,分别包括Native aio: kernel AIO 和 threaded aio: user space AIO emulated by posix thread workers,内核方式要比用户态的方式性能稍好一点,所以一般情况都选择native,开启方式<driver name='qemu' type='qcow2' cache='none' aio='native'/>
块设备调度器
cfq:perprocess IO queue,较好公平性,较低aggregate throughput
deadline:per-device IO queue,较好实时性,较好aggregate throughput,不够公平,当某些vm有大量io操作,占用了大量io资源时,其它后加入的vm很有可能抢占不到io资源。
这个目前笔者还没有做过测试,但是查看网易和美团云的方案,都将其设置为cfq。
开启方式:echo cfq > /sys/block/sdb/queue/scheduler
网络
优化项包括virtio、vhost、macvtap、vepa、SRIOV 网卡,下面有几篇文章写的非常好
- https://www.redhat.com/summit/2011/presentations/summit/decoding_the_code/wednesday/wagner_w_420_kvm_performance_improvements_and_optimizations.pdf
- https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html-single/Virtualization_Tuning_and_Optimization_Guide/index.html#chap-Virtualization_Tuning_Optimization_Guide-Networking
- http://www.openstack.cn/p2118.html
- http://www.ibm.com/developerworks/cn/linux/1312_xiawc_linuxvirtnet/
- http://xiaoli110.blog.51cto.com/1724/1558984
virtio
更改虚拟网卡的类型,由全虚拟化网卡e1000、rtl8139,转变成半虚拟化网卡virtio,virtio需要qemu和vm内核virtio驱动的支持,这个原理和磁盘virtio原理一样,不再赘述。
vhost_net
vhost_net将virtiobackend处理程序由user space转入kernel space,将减少两个空间内存拷贝和cpu的切换,降低延时和提高cpu使用率
macvtap
代替传统的tap+bridge,有4中模式,bridge、vepa、private、passthrough
1, Bridge, 完成与 Bridge 设备类似功能,数据可以在属于同一个母设备的子设备间交换转发. 当前的Linux实现有一个缺陷,此模式下MACVTAP子设备无法和Linux Host通讯,即虚拟机无法和Host通讯,而使用传统的Bridge设备,通过给Bridge设置IP可以完成。但使用VEPA模式可以去除这一限制. macvtap的这种bridge模式等同于传统的tap+bridge的模式.
2, VEPA, 式是对802.1Qbg标准中的VEPA机制的部分软件实现,工作在此模式下的MACVTAP设备简单的将数据转发到母设备中,完成数据汇聚功能,通常需要外部交换机支持Hairpin模式才能正常工作。
3, Private, Private模式和VEPA模式类似,区别是子 MACVTAP之间相互隔离。
4, Passthrough, 可以配合直接使用SRIOV网卡, 内核的macvtap数据处理逻辑被跳过,硬件决定数据如何处理,从而释放了Host CPU资源。MACVTAP Passthrough 概念与PCI Passthrough概念不同,PCI Passthrough针对的是任意PCI设备,不一定是网络设备,目的是让Guest OS直接使用Host上的 PCI 硬件以提高效率。MACVTAP Passthrough仅仅针对 MACVTAP网络设备,目的是饶过内核里MACVTAP的部分软件处理过程,转而交给硬件处理。综上所述,对于一个 SRIOV 网络设备,可以用两种模式使用它:MACVTAP Passthrough 与 PCI Passthrough
PCI pass-through
直通,设备独享。
SO-IOV
优点是虚拟网卡的工作由host cpu交给了物理网卡来实现,降低了host cpu的使用率,缺点是,需要网卡、主板、hypervisor的支持。
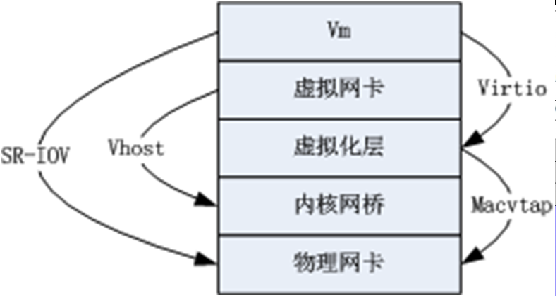
这几种优化方案,其关系可由下面这张图来表示。
测试结果,在实验室2台host,分别起1台vm(vm1、vm2),用iperf测试vm1和vm2之间的吞吐量,用ping测试2者之间的响应时间,host机为百兆网卡,结果如下表所示,可以看出随着优化的深入,其吞吐量和响应时间都有所改善,由于暂时没有硬件的支持,macvtap vepa和SR-IOV没有得到测试。
| Test item | Iperf(ping) |
| rtl8139 | 87Mb/s(1.239ms) |
| virtio | 89Mb/s(1.140ms) |
| Virtio + host_net | 92Mb/s(1.014ms) |
| Macvtap(bridge) + virtio +host_net | 94Mb/s(0.989ms) |
| host | 95Mb/s(0.698ms) |
总结来看网络虚拟化具有三个层次:
1, 0成本,通过纯软件virtio、vhost、macvtap提升网络性能;
2, 也可以用非常低的成本按照802.1Qbg中的VEPA模型创建升级版的虚拟网络,引出虚拟机网络流量,减少Host cpu负载,但需要物理交换机的配合;
3, 如果网络性能还是达不到要求,可以尝试SR-IOV技术,不过需要SR-IOV网卡的支持。
总结:文章总共阐述了cpu、内存、磁盘、网络的性能优化方案,大部分都是通过kvm参数和系统内核参数的修改来实现。
一个完整的数据包从虚拟机到物理机的路径是:
虚拟机--QEMU虚拟网卡--虚拟化层--内核网桥--物理网卡

KVM的网络优化方案,总的来说,就是让虚拟机访问物理网卡的层数更少,直至对物理网卡的单独占领,和物理机一样的使用物理网卡,达到和物理机一样的网络性能。
方案一 全虚拟化网卡和virtio

Virtio 与全虚拟化网卡区别
全虚拟化网卡是虚拟化层完全模拟出来的网卡,半虚拟化网卡通过驱动对操作系统做了改造;
viritio简单的说,就是告诉虚拟机,hi 你就是在一个虚拟化平台上跑,咱们一起做一些改动,让你在虚拟化平台上获得更好的性能;

关于virtio的使用场景
因 为windows虚拟机使用viritio有网络闪断的情况发生,windows 虚拟机如果网络压力不高,建议使用e1000这样的全虚拟化网卡,如果网络压力比较高,建议使用SRIVO或者PCI Device Assignment这样的技术;viritio也在不断的演进,希望windows的闪断的问题越来越少。
KVM天生就是为linux系统设计的,linux系统请放心大胆的使用viritio驱动;
方案二 vhost_net macvtap技术

vhost_net使虚拟机的网络通讯直接绕过用户空间的虚拟化层,直接可以和内核通讯,从而提供虚拟机的网络性能;
macvtap则是跳过内核的网桥;
使用vhost_net,必须使用virtio半虚拟化网卡;
vhost_net虚拟机xml文件配置,
<interface type='bridge'> <mac address=''/> <source bridge='br0'/> <model type='virtio'/> <driver name="vhost"/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface>
如果不使用vhost_net,则为
<driver name="qemu"/>
<interface type='direct'> <mac address='00:16:3e:d5:d6:77'/> <source dev='lo' mode='bridge'/> <model type='e1000'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface>
注意:macvtap在windows虚拟机上性能很差,不建议使用
vhost_net macvtap比较
macvlan的功能是给同一个物理网卡配置多个MAC地址,这样可以在软件商配置多个以太网口,属于物理层的功能。
macvtap是用来替代TUN/TAP和Bridge内核模块,macvtap是基于macvlan这个模块,提供TUN/TAP中tap设备使用的接口,
使用macvtap以太网口的虚拟机能够通过tap设备接口,直接将数据传递到内核中对应的macvtap以太网口。
vhost-net是对于virtio的优化,virtio本来是设计用于进行客户系统的前端与VMM的后端通信,减少硬件虚拟化方式下根模式个非根模式的切换。
而是用vhost-net后,可以进一步进入CPU的根模式后,需要进入用户态将数据发送到tap设备后再次切入内核态的开销,而是进入内核态后不需要在进行内核态用户态的切换,进一步减少这种特权级的切换,说vhost-net属于哪个层不准确,而是属于进行二层网络数据传递的优化。
方案三 虚拟机网卡独占

网卡passthrough在虚拟机的配置方法
1 使用lcpci 设备查看pci设备信息
04:00.0 Ethernet controller: Intel Corporation 82571EB Gigabit Ethernet Controller (rev 06)
04:00.1 Ethernet controller: Intel Corporation 82571EB Gigabit Ethernet Controller (rev 06)也可以使用virsh nodedev-list �tree得到信息
+- pci_0000_00_07_0
| |
| +- pci_0000_04_00_0
| | |
| | +- net_p1p1_00_1b_21_88_69_dc
| |
| +- pci_0000_04_00_1
| |
| +- net_p1p2_00_1b_21_88_69_dd
2 使用virsh nodedev-dumxml pci_0000_04_00_0得到xml配置信息
[root@]# virsh nodedev-dumpxml pci_0000_04_00_0
<device> <name>pci_0000_04_00_0</name> <parent>pci_0000_00_07_0</parent> <driver> <name>e1000e</name> </driver> <capability type='pci'> <domain>0</domain> <bus>4</bus> <slot>0</slot> <function>0</function> <product id='0x105e'>82571EB Gigabit Ethernet Controller</product> <vendor id='0x8086'>Intel Corporation</vendor> </capability> </device>
3 编辑虚拟机xml文件,加入pci设备信息
<hostdev mode='subsystem' type='pci' managed='yes'> <source> <address domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </source> </hostdev>
Domain bus slot function信息从dumpxml出的xml文件获取,define虚拟机,然后开启虚拟机就可以,注意以为附件上去的是物理设备,需要在系统里面安装相应的驱动。
方案四 SR-IVO技术
SRIOV 的原理
SR-IVO 是the single root I/O virtualization 的简写,是一个将PCIe共享给虚拟机使用的标准,目前用在网络设备上比较多,理论上也可以支持其他的PCI设备,SRIOV需要硬件的支持。

以下内容来自oracle网站,链接为 http://docs.oracle.com/cd/E38902_01/html/E38873/glbzi.html

物理功能 (Physical Function, PF)
用 于支持 SR-IOV 功能的 PCI 功能,如 SR-IOV 规范中定义。PF 包含 SR-IOV 功能结构,用于管理 SR-IOV 功能。PF 是全功能的 PCIe 功能,可以像其他任何 PCIe 设备一样进行发现、管理和处理。PF 拥有完全配置资源,可以用于配置或控制 PCIe 设备。
虚拟功能 (Virtual Function, VF)
与物理功能关联的一种功能。VF 是一种轻量级 PCIe 功能,可以与物理功能以及与同一物理功能关联的其他 VF 共享一个或多个物理资源。VF 仅允许拥有用于其自身行为的配置资源。
每 个 SR-IOV 设备都可有一个物理功能 (Physical Function, PF),并且每个 PF 最多可有 64,000 个与其关联的虚拟功能 (Virtual Function, VF)。PF 可以通过寄存器创建 VF,这些寄存器设计有专用于此目的的属性。
一 旦在 PF 中启用了 SR-IOV,就可以通过 PF 的总线、设备和功能编号(路由 ID)访问各个 VF 的 PCI 配置空间。每个 VF 都具有一个 PCI 内存空间,用于映射其寄存器集。VF 设备驱动程序对寄存器集进行操作以启用其功能,并且显示为实际存在的 PCI 设备。创建 VF 后,可以直接将其指定给 IO 来宾域或各个应用程序(如裸机平台上的 Oracle Solaris Zones)。此功能使得虚拟功能可以共享物理设备,并在没有 CPU 和虚拟机管理程序软件开销的情况下执行 I/O。
SR-IOV 的优点
SR-IOV 标准允许在 IO 来宾域之间高效共享 PCIe 设备。SR-IOV 设备可以具有数百个与某个物理功能 (Physical Function, PF) 关联的虚拟功能 (Virtual Function, VF)。VF 的创建可由 PF 通过设计用来开启 SR-IOV 功能的寄存器以动态方式进行控制。缺省情况下,SR-IOV 功能处于禁用状态,PF 充当传统 PCIe 设备。
具有 SR-IOV 功能的设备可以利用以下优点:
性能-从虚拟机环境直接访问硬件。
成本降低-节省的资本和运营开销包括:
节能
减少了适配器数量
简化了布线
减少了交换机端口
SRIOV 的使用
启动SRIVO内核模块
modprobe igb
激活虚拟功能VF
modprobe igb max_vfs=7
千兆网卡最多支持8个vf0-7,千兆网卡目前支持比较好的是INTEL I350, 82576S虽然也支持SRIOV但是只支持虚拟机是linux的情况,windows系统不支持;
万兆网卡最多支持64个vg0-63,intel的新新一代万兆网卡都支持SRIOV x520 x540等;
如果需要重新设置vf 可以删除模块在重新加载
modprobe -r igb
将配置永久写入配置文件
echo "options igb max_vfs=7" >>/etc/modprobe.d/igb.conf
通过lspci命令可以看多主网卡和子网卡
# lspci | grep 82576
0b:00.0 Ethernet controller: Intel Corporation 82576 Gigabit Network Connection (rev 01)
0b:00.1 Ethernet controller: Intel Corporation 82576 Gigabit Network Connection (rev 01)
0b:10.0 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.1 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.2 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.3 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.4 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.5 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.6 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:10.7 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:11.0 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:11.1 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:11.2 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:11.3 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:11.4 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
0b:11.5 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)虚拟机可以听过pci网卡独占的方式使用子网卡;
# virsh nodedev-list | grep 0b
pci_0000_0b_00_0
pci_0000_0b_00_1
pci_0000_0b_10_0
pci_0000_0b_10_1
pci_0000_0b_10_2
pci_0000_0b_10_3
pci_0000_0b_10_4
pci_0000_0b_10_5
pci_0000_0b_10_6
pci_0000_0b_11_7
pci_0000_0b_11_1
pci_0000_0b_11_2
pci_0000_0b_11_3
pci_0000_0b_11_4
pci_0000_0b_11_5
<interface type='hostdev' managed='yes'> <source> <address type='pci' domain='0' bus='11' slot='16' function='0'/> </source> </interface>
方案五 网卡多队列
centos 7 开始支持virtio网卡多队列 ,可以大大提高虚拟机网络性能,配置方法如下:
虚拟机的xml网卡配置
<interface type='network'> <source network='default'/> <model type='virtio'/> <driver name='vhost' queues='N'/> </interface>
N 1 - 8 最多支持8个队列
在虚拟机上执行以下命令开启多队列网卡
#ethtool -L eth0 combined M
KVM网络优化方案个人认为以硬件为主,硬件上万兆+SRIOV的方案会越来越普及,但是在线迁移的问题有待解决。















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









