






pandas是python里功能很强大的数据分析与处理库,包括excel文件的读取,按标签分类处理,按时间序列处理,数据矩阵的单值分析和统计学计算。因为功能非常强大,所以一个复杂的业务逻辑只需要几十行甚至几行代码就能实现,这得益于库开发者们的工作成果,当然要实现也需要学习者有足够好的数学基础和编程语言基础。
超预期和风险扫描需要的功能如下:
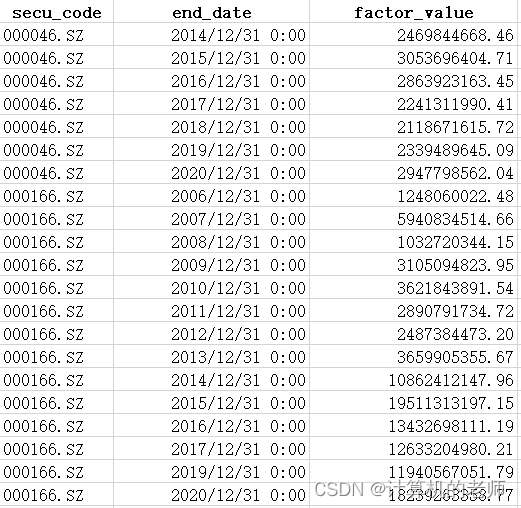
按照secu_code对数据进行分组处理,对每个组的数据按时间序列排序,并且自动提取近N年的factor_value,N年内缺失的数据用--标注。
![]()
pandas.read_excel(path)可将xlsx文件转化为dataframe对象
dataframe包含了许多的函数方法,loc用索引对矩阵的精准处理(增删改查)但要注意,iloc用行号对矩阵做增删改查,sort_values的排序,shape的行列数查询以便做整表处理等等

用列表来分别存储多个不同标签的dataframe,df['attribute']==可以返回一个满足条件的bool series,行数和df匹配,df[series]则返回一个满足true的dataframe,可用在大规模分类里。
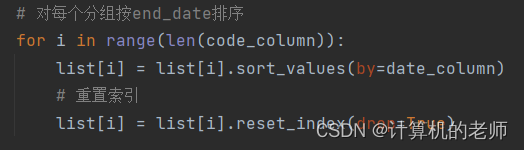
df.sortvalue(attribute,ascending)按照某属性值升序True,或降序False排列
排列后index会被打乱,如果要用loc处理数据记得reset_index()
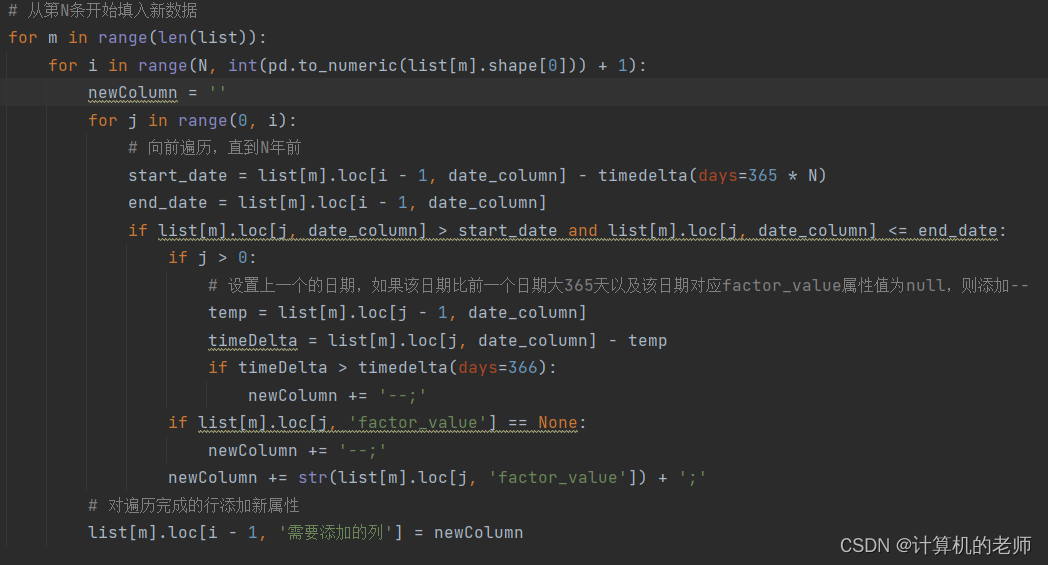 要实现自动化肯定要对每个分类组用相同的业务逻辑进行处理,所以for m in range(len(list))
要实现自动化肯定要对每个分类组用相同的业务逻辑进行处理,所以for m in range(len(list))
左闭右开和数值对应的数据我一直有点模糊不清,所以在这里debug了好长时间。
第二个for是添加新的属性值,N开始取,0-N-1为N个数据才需要填进去,直到最后一个数据也要取,第三个for是取符合条件的0-(i-1)的值
做这种全表处理的时候,一定要注意,初始点是几,结尾点是几,他们和总长度的数学关系是什么,因为前一个循环的值会给后一个循环用,初学者最好拿笔写一写,算一算,程序的价值核心就是把握头就能轻松得到尾,头都把握不住那这点价值也就没有了。
datetime可以和deltatime做时间运算,得到很便于人理解的结果
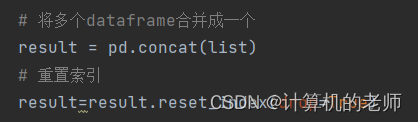
各种dataframe处理好之后concat外连接,再重置一下索引就大功告成了















 866
866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









