







参考:【Python技能树共建】Beautiful Soup_梦想橡皮擦的博客-CSDN博客
Beautiful Soup主要用于将 HTML 标签转换为 Python 对象树,然后让我们从对象树中提取数据。
基础用法
import requests
from bs4 import BeautifulSoup
def ret_html():
"""获取HTML元素"""
res = requests.get('https://www.crummy.com/software/BeautifulSoup/', timeout=3)
return res.text
if __name__ == '__main__':
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
print(soup)上述输出就是普通的html格式文件,我们可以调用 soup 对象的 soup.prettify() 方法,可以将 HTML 标签进行格式化操作
BeautifulSoup 类的构造函数中传递的两个参数,一个是待解析的字符串,另一个是解析器,官方建议的是 lxml,因其解析速度快。
BeautifulSoup 类可以将 HTML 文本解析成 Python 对象树,而这里面又包括最重要的四种对象,分别是 Tag,NavigableString,BeautifulSoup,Comment 对象
测试文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div class="userful">
<ul>
<li class="info">我需要的信息1</li>
<li class="test">我需要的信息2</li>
<li class="strange">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾1</li>
<li class="info">垃圾2</li>
</ul>
</div>
</body>
</html>BeautifulSoup 对象
该对象本身就代表整个 HTML 页面,而且实例化该对象的时候,还会自动补齐 HTML 代码。
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
print(type(soup))Tag 对象
Tag 是标签的意思,Tag 对象就是网页标签,或者叫做网页元素对象,例如获取 bs4 官网的 h1 标签对象,代码如下所示:
html_str = ret_html()
soup = BeautifulSoup(html_str, 'lxml')
# print(soup.prettify())
print(soup.h1)
输出soup.h1的type,可以看到,它是一个tag对象
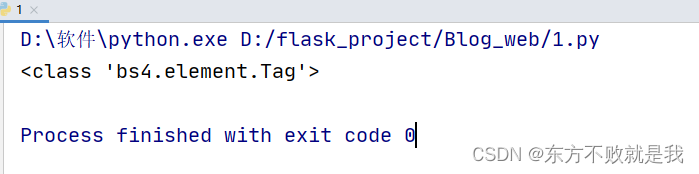
既然是 Tag 对象,那就会具备一些特定的属性值
获取标签名称
print(soup.h1)
print(type(soup.h1))
print(soup.h1.name) # 获取标签名称
通过 Tag 对象获取标签的属性值
print(soup.img) # 获取网页第一个 img 标签
print(soup.img['src']) # 获取网页元素DOM的属性值
通过 attrs 属性获取标签的所有属性
print(soup.img) # 获取网页第一个 img 标签
print(soup.img.attrs) # 获取网页元素的所有属性值,以字典形式返回 
print("soup.link",soup.link) print("soup.link['href']",soup.link['href']) print("soup.link.attrs",soup.link.attrs)

NavigableString 对象
NavigableString 对象获取的是标签内部的文字内容,例如 p 标签,在下述代码中提取的是 我是橡皮擦
<p>我是橡皮擦</p>
获取该对象也非常容易,使用 Tag 对象的 string 属性即可。
nav_obj = soup.h1.string
print(type(nav_obj))
输出结果如下所示
<class 'bs4.element.NavigableString'>
如果目标标签是一个单标签,会获取到 None 数据
除了使用对象的 string 方法外,还可以使用 text 属性和 get_text() 方法来获取标签内容
print(soup.h1.text)
print(soup.p.get_text())
print(soup.p.get_text('&'))
其中 text 是获取所有子标签内容的合并字符串,而 get_text() 也是相同的效果,不过使用 get_text() 可以增加一个分隔符,例如上述代码的 & 符号,还可以使用,strip=True 参数去除空格。

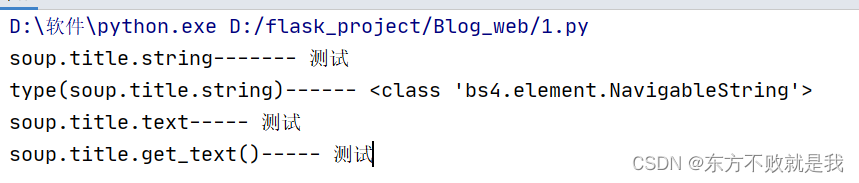
print("soup.title.string-------",soup.title.string) print("type(soup.title.string)------",type(soup.title.string)) print("soup.title.text-----",soup.title.text) print("soup.title.get_text()-----",soup.title.get_text())
find() 方法和 find_all() 方法
调用 BeautifulSoup 对象和 Tag 对象的 find() 方法,可以在网页中找到指定对象,该方法的语法格式如下:
obj.find(name,attrs,recursive,text,**kws)
方法的返回结果是查找到的第一个元素,如果没查询到,返回 None。
参数说明如下:
name:标签名称;attrs:标签属性;recursive:默认搜索所有后代元素;text:标签内容。
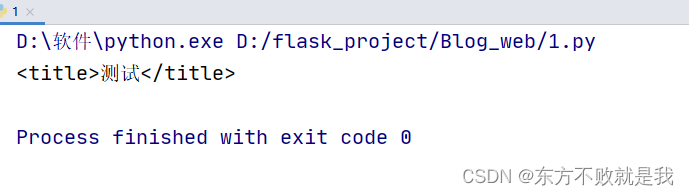
soup = BeautifulSoup(open('test.html', encoding='utf-8'), 'lxml') print(soup.find('title'))#查找title标签
也可以使用 attrs 参数进行查找
soup = BeautifulSoup(open('test.html', encoding='utf-8'), 'lxml') print(soup.find(attrs={'class':'info'}))
find() 方法还提供了一些特殊的参数,便于直接查找,例如可以使用 id=xxx,查找属性中包含 id 的标签,可以使用 class_=xxx,查找属性中包含 class 的标签。
print(soup.find(class_='cta'))
与 find() 方法成对出现的是 find_all() 方法,看名称就能知道其返回结果收是全部匹配标签,语法格式如下:
obj.find_all(name,attrs,recursive,text,limit) limit 参数,它表示最多返回的匹配数量,find() 方法可以看作 limit=1,这样就变得容易理解了。
练习
获取所有p标签文本
获取所有p标签里的文本
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
def fetch_p(html):
soup=BeautifulSoup(html,'lxml')
p_list=soup.findall('p')
results=[p.text for p in p_list]
return results
if __name__ == '__main__':
html = '''
<html>
<head>
<title>这是一个简单的测试页面</title>
</head>
<body>
<p class="item-0">body 元素的内容会显示在浏览器中。</p>
<p class="item-1">title 元素的内容会显示在浏览器的标题栏中。</p>
</body>
</html>
'''
p_text = fetch_p(html)
print(p_text)获取网页的text
from bs4 import BeautifulSoup
def fetch_text(html):
soup=BeautifulSoup(html,'lxml')
result=soup.text
return result
if __name__ == '__main__':
html = '''
<html>
<head>
<title>这是一个简单的测试页面</title>
</head>
<body>
<p class="item-0">body 元素的内容会显示在浏览器中。</p>
<p class="item-1">title 元素的内容会显示在浏览器的标题栏中。</p>
</body>
</html>
'''
text = fetch_text(html)
print(text)
查找网页里所有图片地址
from bs4 import BeautifulSoup
def fetch_imgs(html):
soup=BeautifulSoup(html,'html.parser')
imges=[tag['src'] for tag in soup.find_all('img')]
return imgs
def test():
imgs = fetch_imgs(
'<p><img src="http://example.com"/><img src="http://example.com"/></p>')
print(imgs)
if __name__ == '__main__':
test()














 1552
1552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









