







ResNet网络(2015年提出)
1.ResNet网络详解
- ResNet网络在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测任务第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
原论文:Deep Residual Learning for Image Recognition
Kaiming He xiangyu Zhang Shaoqing Ren Jian Sun(都是华人)
- 网络中的亮点
-
超深的网络结构(突破100层)(原论文中作者有尝试搭建1000多层的网络)
不能简单的堆叠网络层,这样不能提升网络的性能。
原论文中提到叠加网络层数出现的问题:
-
梯度消失或梯度爆炸
问题描述:随着网络层数不断加深,梯度消失或梯度爆炸情况会越来越明显。
-
假设每一层的误差梯度是一个小于1的数,那么在反向传播的过程中,每向前传播一次,都要乘以一个小于1的误差梯度。当网络层数越深,乘以的误差梯度越小,则最终得出的误差梯度越接近于0,即梯度消失。
-
反过来假设每一层的梯度是一个大于1的数,那么在反向传播的过程中,每向前传播一次,都要乘以一个大于1的误差梯度。当网络层数越深,乘以的误差梯度越大,则最终得出的误差梯度越接近于无穷,即梯度爆炸。
解决办法:
通常通过对数据进行标准化处理,权重初始化,以及Batch Normalization
-
-
退化问题(degradation problem)
问题描述:在解决了梯度消失或者梯度爆炸的问题之后,仍然会面临退化问题(层数深的网络结构可能还没有层数少的网络结构效果好)
(一种观点认为,这是由于信息在深度网络传递过程中会产生失真,网络越深,失真越严重,类似于系统的积累误差)
解决办法:何凯明中提出了一种包含恒等映射(identity mapping)的网络模块,称为残差结构,通过残差结构就能解决退化问题。
-
-
提出residual模块(残差模块)
- residual模块效果:
效果
如图1所示,可以看到随着网络结构的深度不断增加,错误率越低。解决了退化问题。应用残差结构:可以使用论文中提出的残差结构来不断加深网络,获得更好的结果(加快训练速度,提升模型的训练效果)
当残差为0时,学习单元仅做了恒等映射,至少保证了网络性能不会下降;而实际上,一般学习单元的残差不会为0,这就保证了网络总能学习到新的知识,从而拥有更好的性能。
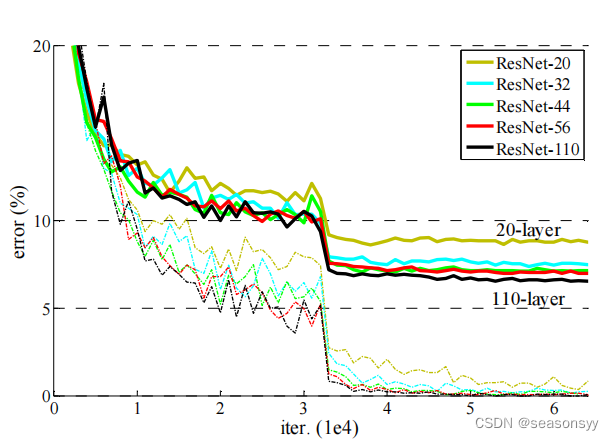
图1
图中的实线:验证集错误率
虚线:训练集错误率
-
residual模块结构:
如图5所示有两种:针对层数较少的residual残差结构(左图)和针对层数较多的residual残差结构(右图)
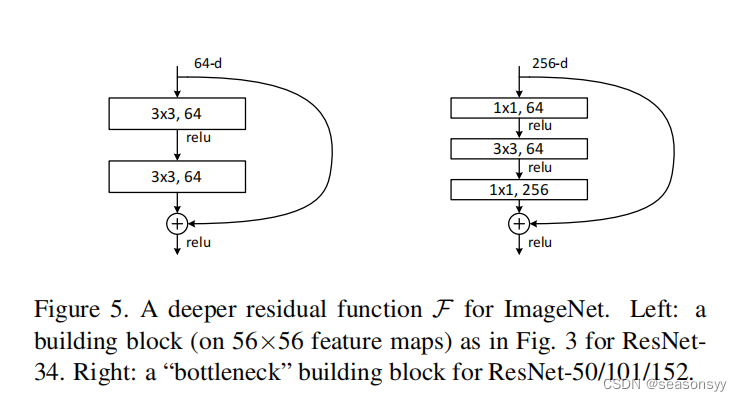
图5 残差学习单元接收输入数据后,首先对数据进行备份,然后进行学习,最终将学习结果与备份数据相加后,输出给下一个学习单元。 通过这种结构,使得深层网络总能够获得前层网络的完整信息,并在此基础上学习新的知识。
这就相当于每一层在学习的过程中,都可以**“复习”或“查阅”**之前的学习成果。那么,即使不能有效地学习出新的知识,单靠将前层的学习结果恒等向后传递,深度网络的性能也不会比浅层网络更差。
对于每一层而言,前层恒等映射而来的信息可认为是已经学习到的模型,每一层只需要学习现有的知识和理想模型之间尚缺的部分,或者称为“残差”部分,因此,这种网络称为残差网络。恒等映射有点类似于电路中的短路,也称为短路连接(shortcut connection)
图5左图部分 图5右图部分 残差结构是针对ResNet34网络的残差结构(层数较少) 右图的残差结构是针对ResNet-50/101/152的残差结构(层数较多) 主线:将输入的特征矩阵送入两个3×3的卷积层,得到结果 主线:通过1×1的卷积层(降维)、3×3的卷积层、1×1的卷积层(升维)【1×1卷积层的作用:降维和升维】 shortcut直接从输入连接到输出 同左 总体:从主分支上得到的特征矩阵与输入的特征矩阵进行相加,再通过ReLU激活函数。 同左 注意1:第一个卷积层后有ReLU激活函数,第二个卷积层后没有ReLU激活函数,是主线和输入的特征矩阵相加之后,再通过ReLu激活函数的。 同左 注意2:主分支与shortcut(捷径)的输出特征矩阵shape必须相同(高、宽、通道,所有维度都一样),这样两个矩阵才能在相同的维度上相加。 同左 参数量:(3×3×256)×256+(3×3×256)×256=1179648 参数量:(1×1×256)×64+(3×3×64)×64+(1×1×64)×256=69632
实线和虚线的残差结构有什么不同?
有些残差结构的shortcut标记实线,有些残差结构的shortcut标记虚线。
原因:只有通过虚线残差结构得到输出之后,再将输出输入到实线的残差结构中,才能保证输出特征矩阵的shape和输入特征矩阵的shape是一样的。
虚线残差结构部分额外的作用:将输入特征矩阵的高、宽、深度进行变化。
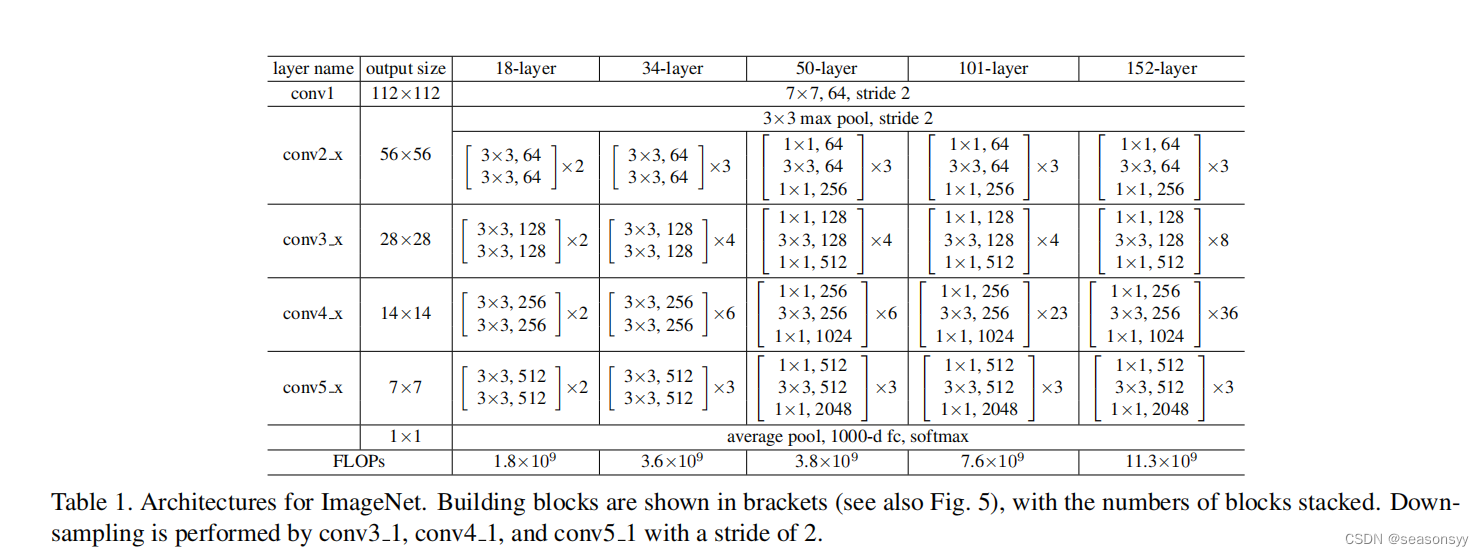
ResNet网络结构如表1所示。
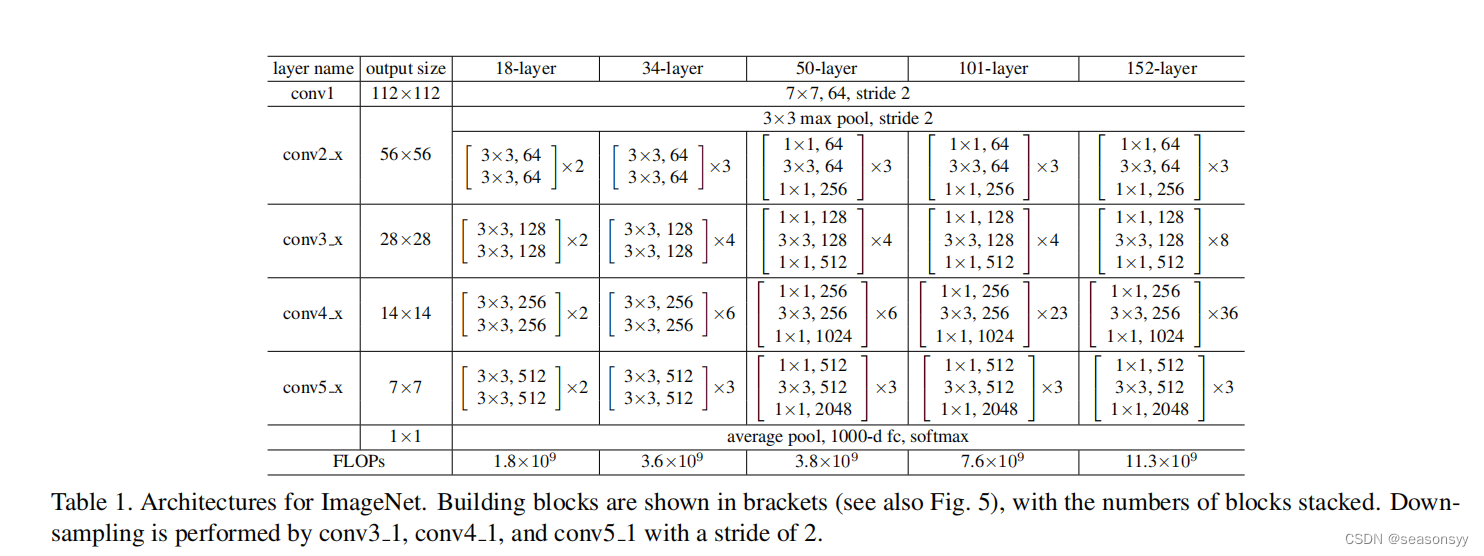
ResNet-18 ResNet-34 ResNet-50 ResNet-101 ResNet-152 Conv1 Conv2_x第一层 实线 实线 虚线(但是仅调整特征矩阵的深度,高和宽不变[56,56,64]——>[56,56,256] 虚线(但是仅调整特征矩阵的深度,高和宽不变) 虚线(但是仅调整特征矩阵的深度,高和宽不变) Conv3_x第一层 虚线 虚线 虚线(改变宽度、高度、深度) 虚线(改变宽度、高度、深度) 虚线(改变宽度、高度、深度) Conv4_x第一层 虚线 虚线 虚线(改变宽度、高度、深度) 虚线(改变宽度、高度、深度) 虚线(改变宽度、高度、深度) Conv5_x第一层 虚线 虚线 虚线(改变宽度、高度、深度) 虚线(改变宽度、高度、深度) 虚线(改变宽度、高度、深度) 针对层数较少的residual残差结构(图5左图)解释实线和虚线的不同。
如图3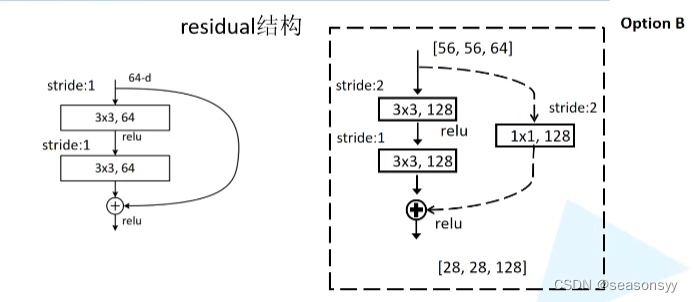
图3
以34-layer为例来进行介绍。
图3左图实线的部分 图3右图虚线部分 输入的特征矩阵的shape和输出的特征矩阵的shape是一样的,所以能够直接进行相加 输入的特征矩阵的shape和输出的特征矩阵的shape是不一样的(conv3_x的输入特征矩阵shape为[56,56,64],输出特征矩阵shape为[28,28,128]) 3×3的卷积层的stride=1 主分支:3×3的卷积层的stride=2,使得特征矩阵的大小从56变为28,通过128个卷积核改变特征矩阵的深度为128。 shortcut:加上了1×1的卷积核,stride=2,使得特征矩阵的大小从56变为28,使用128个卷积核改变特征矩阵的深度为128。 这样,主分支和shortcut的输出特征矩阵的shape就一样了。[28,28,128] 针对层数较多的residual残差结构(图5右图)解释实线和虚线的不同。
如图4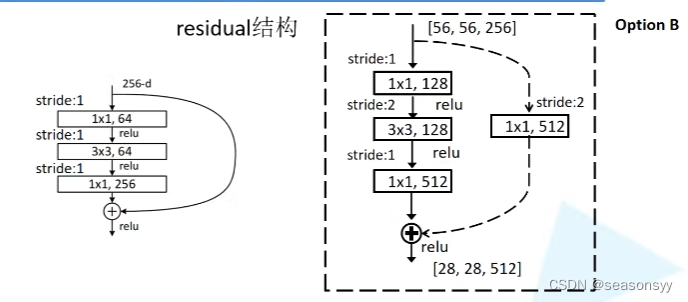
图4
以Conv3_x所对应的一系列残差结构50-layer、101-layer、152-layer
输入特征矩阵的shape是[56,56,256]
输出特征矩阵的shape是[28,28,512]
图4右图虚线部分(option B ) 输入的特征矩阵[56,56,256] 主分支①:1×1卷积核,stride=1,只起到降维作用,维度从256降到128。[56,56,128] 主分支②:3×3卷积核,特征图大小缩减为原来的一半,维度不变[28,28,128] 主分支③:1×1卷积核,不改变大小,增加特征图维度。[28,28,512] shortcut:1×1的卷积核,stride=2,大小缩减为原来一半,维度改变[28,28,512](原论文中针对shortcut有A,B,C三种方案,但是B方案效果最好) 注意:原论文中,虚线部的主分支上,第一个1×1卷积层的步距是2,第二个3×3卷积层步距是1。但是在pytorch官方实现过程中是第一个1×1卷积层的步距是1,第二个3×3卷积层步距为2,这样能够在imagenet的top1上提升大概0.5%的准确率。(可参考Resnet v1.5https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5for_pytorch) -
使用Batch Normalization加速训练(丢弃dropout)
目的:使一批(batch)feature map的每一个channel满足均值为0,方差为1的分布规律。
https://blog.csdn.net/qq_37541097/article/details/104434557
2.ResNet网络结构
ResNet网络结构如图0所示
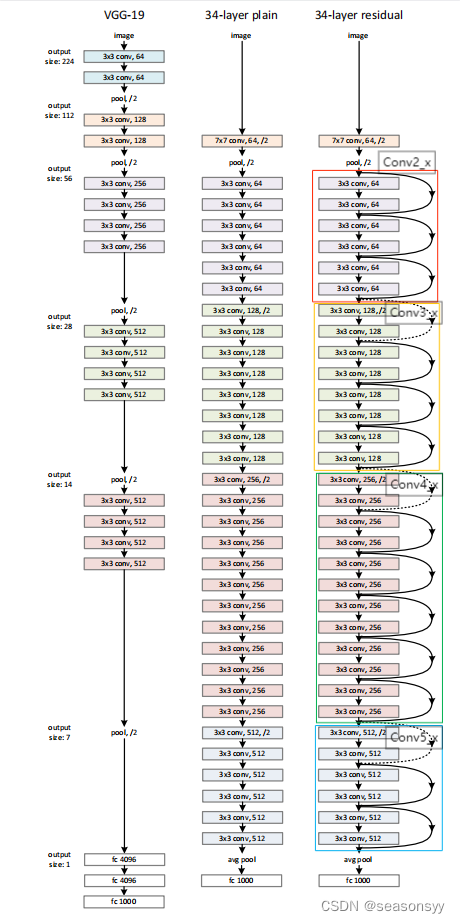
图0
各层的参数如表1所示
迁移学习简介
使用迁移学习的优势:
-
能够快速的训练出一个理想的结果
-
当数据集较小时也能训练出理想的效果
注意:使用别人预训练模型参数时,要注意别人的预处理方式。
(和别人预训练方式一样,才可能获取较好的结果)
前面卷积层提取到的信息不仅在本网络中适用,在其他网络中也适用,所以产生了迁移的概念。
即把学习好的浅层网络的一些参数迁移到新的网络当中,这样新的网络也就拥有了识别底层通用特征的能力了,就能更加快速的学习新的数据集的高维特征。
常见的迁移学习的方式:
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
硬件参数有限,训练时间有限,选2/3
硬件参数不受限,训练时间长,效果更好,选1
代码运行结果
代码参考:
b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV14E411H7Uw/?spm_id_from=333.999.0.0&vd_source=647760d93691c99109dee33aad004b62
github:https://gitcode.net/mirrors/wzmiaomiao/deep-learning-for-image-processing?utm_source=csdn_github_accelerator
代码位置:\deep-learning-for-image-processing-master\pytorch_classification\Test5_resnet
代码使用数据集:花分类数据集
训练准确度:
使用迁移学习,第一个epoch准确度为89.6%
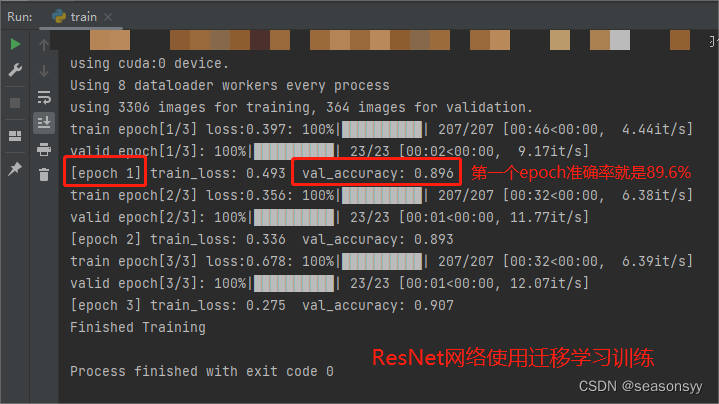
图6
使用迁移学习预测准确度:
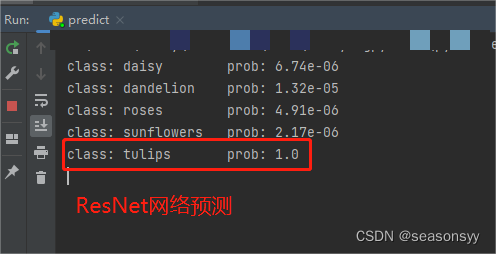
图7
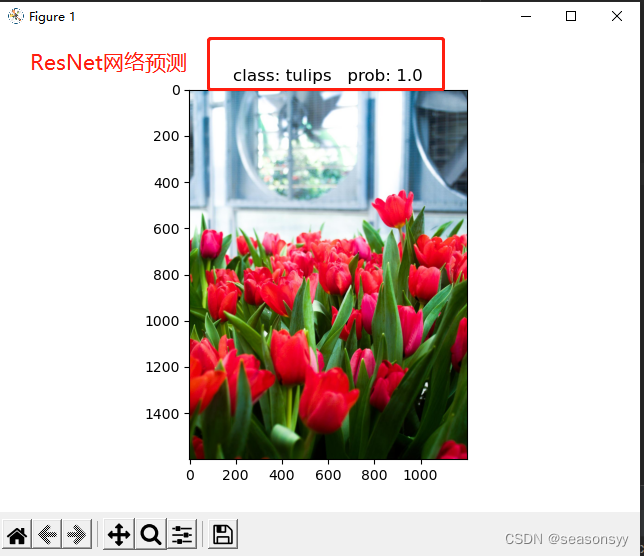
图8
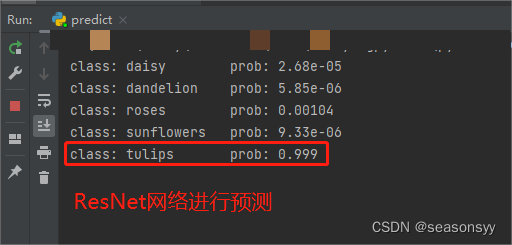
图9
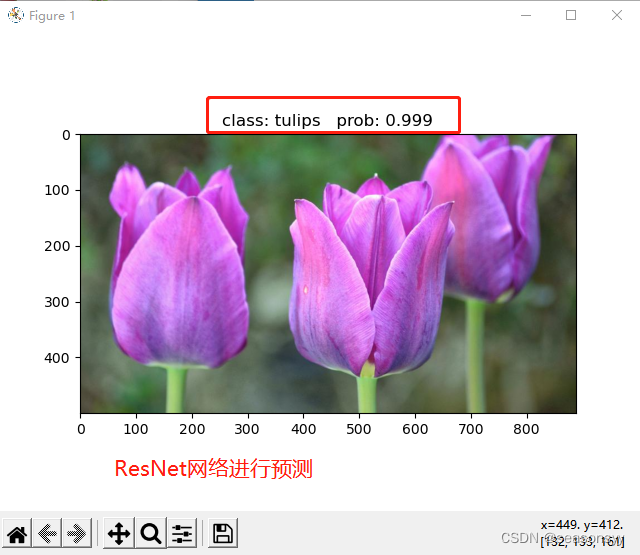
图10
不使用迁移学习训练准确度:
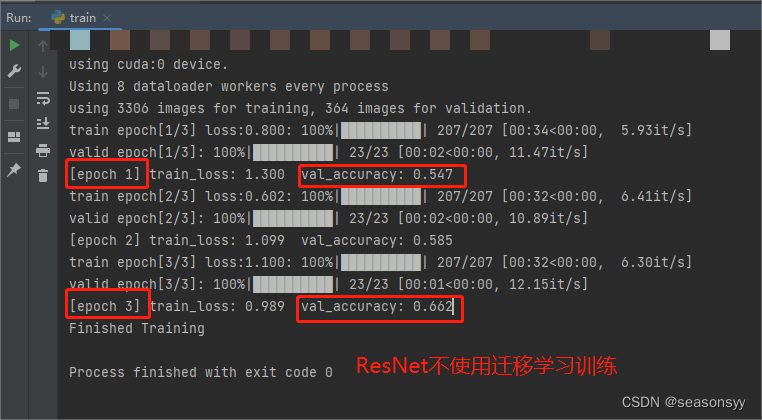
图11
不使用迁移学习预测准确度:
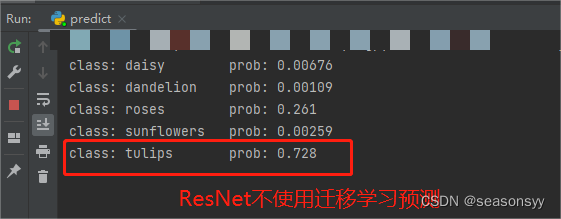
图12
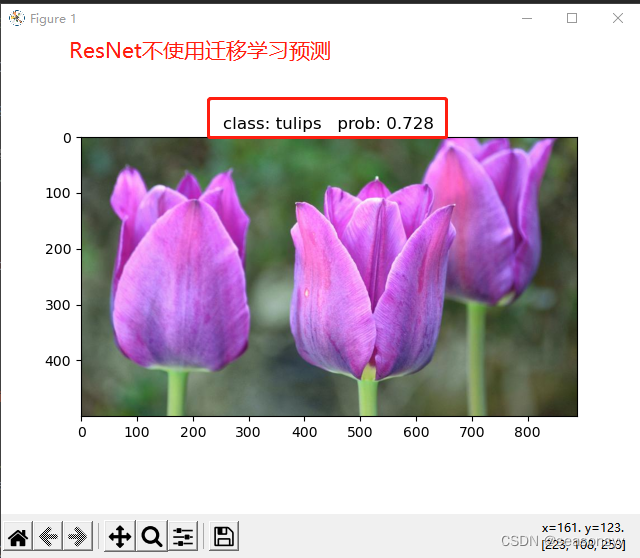
图13
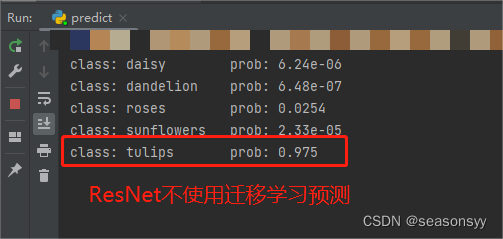
图14
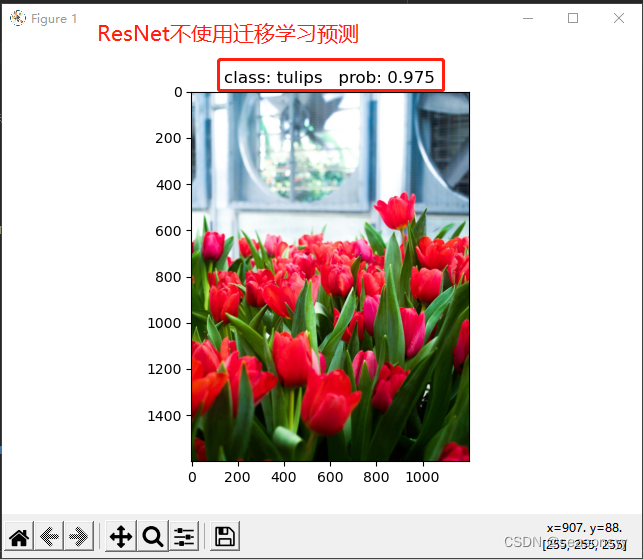
图15
参考文献
b站博主@霹雳吧啦Wz:https://www.bilibili.com/video/BV1T7411T7wa/?spm_id_from=333.999.0.0&vd_source=647760d93691c99109dee33aad004b62
原论文:Deep Residual Learning for Image Recognition
《深度卷积神经网络 原理与实践》周浦城 李从利 王勇 韦哲 编著
出版社:北京:电子工业出版社,2020.10
ISBN: 978-7-121-39663-2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









