







hive数据模型中包含内部表、外部表、分区表和桶表。
一、内部表
内部表也称为管理表。因为这种表,Hive会或多或少地空值数据的生命周期。Hive默认情况下回将这些表的数据存储在由配置项hive.metastore.warehouse.dir所定义的目录(比如/user/hive/warehouse)的子目录下。
如果我有一个表test,那么在HDFS中会创建/user/hive/warehouse/test目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);test表所对应的所有数据都存放在这个目录中。
如果删除这张表,则表在关系数据中存储的元数据以及在warehouse目录下的数据也会被清除掉。
同时管理表不方便与其他工作共享数据。例如我们有一份由Pig或者其他工具创建并且主要由这一工具使用的数据,同时我们还想使用Hive在这份数据上执行一些查询,可是并没有给予Hive对数据的所有权,我们可以创建一个外部表指向这份数据,而并不需要对其具有所有权。
二、外部表
为了避免潜在产生混淆的可能性,如果用户不想使用默认的表路径,那么最好是使用外部表。
外部表可以读取指定目录下的以逗号为分隔的数据:
CREATE EXTERNAL TABLE IF NOT EXISTS stocks(
exchange STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_high FLOAT,
volume INT,
price_adj_close FLOAT)
ROW FORMAT DELIMITED FIFLDS TERMINATED BY ',' --逗号分隔文件
LOCATION '/data/stocks' --指定Hive数据的路径
因为表是外部的,所以Hive并非认为完全拥有这份数据,从而删除该表的时候不会删除这份数据。不过描述表的元数据信息会被删除掉。
三、分区表
分区表用于水平分散压力,将数据从物理上转移到和使用最频繁的用户更近的地方。
一、宽表和窄表
宽表和窄表的建设该如何选择?
这个问题相信纠结了很多从是数据库开发、数据仓库开发和后台开发人员;单单考虑这个问题,难给出一个绝对的答案;本人从事数据仓库开发工作到现在已经有一年半时间了,对于这个问题,我也曾经纠结过,但是是否有绝对的答案呢?事实上任何东西都没有绝对的说法。
考虑这样的一个问题,一个公司有这样的一个需求:
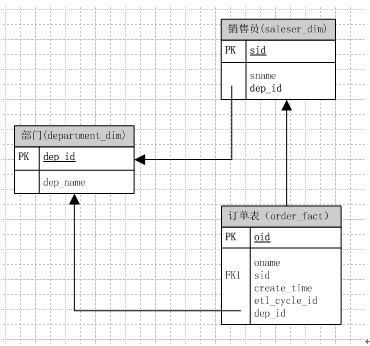
设计销售领域的订单事实表,该事实表应该包含哪些维度和度量?事实表和维表该分别如何去设计?
好了,我们把关键信息拿出来,首先我们要有维度包括:销售员、销售员所属部门、下订单的时间;度量:销售量;
那么,订单事实表,其实就是一个商品销售的清单;
依照这个思路,我们建立的第一个模型可能是以下这样的:

单单看上去,貌似是符合我们的问题的需要,而且符合数据库的范式设计:没有冗余字段;但是情况真的就是这样吗?
答案是否定的,确实对于一般的OLTP系统而言这样的表设计确实减少了冗余和,增删改查等操作也很方便,但是往往对于我们的统计系统、OLAP、数据挖掘而言,情况却并非如此,举个例子:我们要统计每个部门各自的销售量为多少?那么对于上表,sql是这样的:
select a.*,b.sid into #dep_saleser from department a,saleser_dim b on a.dep_id = b.dep_id;
select count(1),a.dep_name from #dep_saleser a,order_fact b on a.sid=b.sid group by a.dep_name;
对于这么一个简单的需求已经要写两了sql去实现了,其实数据库表模型的的设计是灵活的,我们完全可以根据我们的业务去设计我们的数据表;考虑到部门和销售员可以是同属于销售者这个维度,只是他们是有上下级别关系的那么依照这个思路,我们的模型可以建立为下面这样:

那么统计每个部门各自的销售量,可以用如下sql去实现:
select count(1),a.dep_name from saleser_dim a,order_fact b
on a.sid=b.sid group by a.dep_name;
确实对于这个模型而言,有些情况下会出现冗余(填写用户,没有填写部门;填写部门没填写用户);但是对于提取数统计的逻辑又相对来说要简单了好多;
考虑到要实现取数简单,我们还可以想出另外一种方法:
看上去好像不错哦~~,取数据也就一句sql就搞掂了,但是却是最最槽糕的情况,有可能一个销售员,前几天登记的部门是a,但是其实他的所属于的部门为b,那么对于上面这个模型,我们得改动销售员和订单表;而对于上面的其他两个模型都仅仅需要改动一张表就行了,造成查询数据部一致往往也就是这种数据模型所造成的。
所谓的宽表就是字段比较多的表,包含的维度层次比较多,造成冗余也比较多,毁范式设计,但是利于取数统计,而窄表往往对于OLTP比较合适,符合范式设计原则。
摘自:https://www.cnblogs.com/Leo_wl/p/8515794.html
二、开窗函数
使用 hive或 mysql时,一般聚合函数用的比较多。但对于某些偏分析的需求,group by可能很费力,子查询很多,这时就需要使用窗口分析函数了。其中,hive、oracle提供开窗函数,mysql不提供
分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化!到底什么是数据窗口?后面举例会详细讲到!
1. 基础结构:
分析函数(如:sum(),max(),row_number()...) + 窗口子句(over函数)
2. over函数写法:
over(partition by cookieid order by createtime) 先根据 cookieid 字段分区,相同的cookieid分为一区,每个分区内根据createtime字段排序(默认升序)
注:不加 partition by 的话则把整个数据集当作一个分区,不加 order by的话会对某些函数统计结果产生影响,如sum()
3. 测试数据:
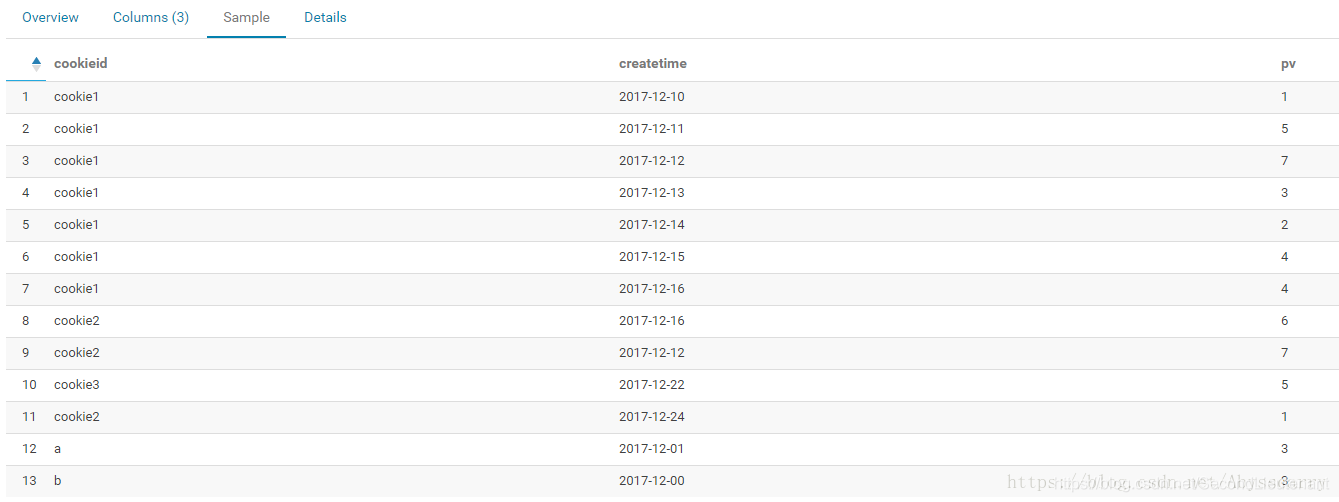
测试表 test1 只有三个字段 cookieid、createtime、pv
4. 窗口含义:
SELECT cookieid,createtime,pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1, -- 默认为从起点到当前行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --从起点到当前行,结果同pv1
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv3, --当前行+往前3行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv4, --当前行+往前3行+往后1行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv5 ---当前行+往后所有行
FROM test1;
结果:

注:这些窗口的划分都是在分区内部!超过分区大小就无效了
相信大家看了后就会明白,如果不指定ROWS BETWEEN,默认统计窗口为从起点到当前行;如果不指定ORDER BY,则将分组内所有值累加;
关键是理解 ROWS BETWEEN 含义,也叫做window子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无边界,UNBOUNDED PRECEDING 表示从最前面的起点开始, UNBOUNDED FOLLOWING:表示到最后面的终点
–其他AVG,MIN,MAX,和SUM用法一样
二、SUM 函数
select cookieid,createtime,pv,
sum(pv) over(PARTITION BY cookieid ORDER BY createtime) as pv1
FROM test1

首先 PARTITION BY cookieid,根据cookieid分区,各分区之间默认根据字典顺序排序,ORDER BY createtime,指定的是分区内部的排序,默认为升序
我们可以清晰地看到,窗口函数和聚合函数的不同,sum()函数可以根据每一行的窗口返回各自行对应的值,有多少行记录就有多少个sum值,而group by只能计算每一组的sum,每组只有一个值!
其中sum()计算的是分区内排序后一个个叠加的值,和order by有关!
如果不加 order by会咋样:
select cookieid,createtime,pv,
sum(pv) over(PARTITION BY cookieid) as pv1
FROM test1
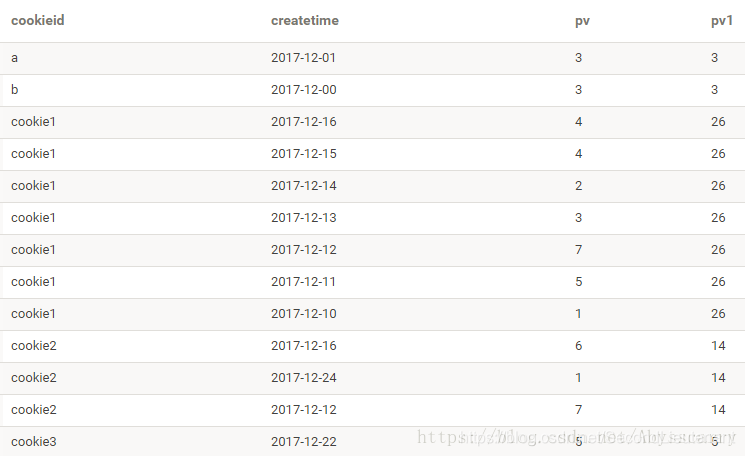
可以看到,如果没有order by,不仅分区内没有排序,sum()计算的pv也是整个分区的pv
注:max()函数无论有没有order by 都是计算整个分区的最大值
三、NTILE 函数
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
注1:如果切片不均匀,默认增加第一个切片的分布
注2:NTILE不支持ROWS BETWEEN
SELECT cookieid,createtime,pv,
NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS ntile1, --分组内将数据分成2片
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS ntile2, --分组内将数据分成3片
NTILE(4) OVER(PARTITION BY cookieid ORDER BY createtime) AS ntile3 --将所有数据分成4片
FROM test1

用法举例:
统计一个cookie,pv数最多的前1/3的天:
SELECT cookieid,createtime,pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS ntile
FROM test1;
取 ntile = 1 的记录,就是我们想要的结果!
四、ROW_NUMBER 函数
ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列
ROW_NUMBER() 的应用场景非常多,比如获取分组内排序第一的记录、获取一个session中的第一条refer等。
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn
FROM test1;

五、RANK 和 DENSE_RANK 函数
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
我们把 rank、dense_rank、row_number三者对比,这样比较清晰:
SELECT cookieid,createtime,pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rank1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS d_rank2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM test1

六、CUME_DIST 函数
cume_dist 返回小于等于当前值的行数/分组内总行数
比如,我们可以统计小于等于当前薪水的人数,所占总人数的比例
SELECT cookieid,createtime,pv,
round(CUME_DIST() OVER(ORDER BY pv),2) AS cd1,
round(CUME_DIST() OVER(PARTITION BY cookieid ORDER BY pv),2) AS cd2
FROM test1;

注:cd1没有partition,所有数据均为1组!
七、PERCENT_RANK 函数
percent_rank 分组内当前行的RANK值-1/分组内总行数-1
注:一般不会用到该函数,可能在一些特殊算法的实现中可以用到吧
SELECT cookieid,createtime,pv,
PERCENT_RANK() OVER(ORDER BY pv) AS rn1
from test1

八、LAG 和 LEAD 函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01') OVER(PARTITION BY cookieid ORDER BY createtime) AS lag1,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS lag2
FROM test1;

LEAD 函数则与 LAG 相反:
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
九、FIRST_VALUE 和 LAST_VALUE 函数
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值
SELECT cookieid,createtime,pv,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS first
FROM test1;

LAST_VALUE 函数则相反:
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值
这两个函数还是经常用到的(往往和排序配合使用),比较实用!
扩展阅读:http://lxw1234.com/archives/category/hive
三、Hive 中几种排序方法的区别与比较
Hive 中 Order by, Sort by ,Dristribute by,Cluster By 的作用和用法
1. order by
set hive.mapred.mode=nonstrict; (default value / 默认值)
set hive.mapred.mode=strict;
order by 和数据库中的Order by 功能一致,按照某一项 & 几项 排序输出。
与数据库中 order by 的区别在于在hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
hive> select * from test order by id;
FAILED: Error in semantic analysis: 1:28 In strict mode, if ORDER BY is specified, LIMIT must also be specified. Error encountered near token 'id'
原因: 在order by 状态下所有数据会到一台服务器进行reduce操作也即只有一个reduce,如果在数据量大的情况下会出现无法输出结果的情况,如果进行 limit n ,那只有 n * map number 条记录而已。只有一个reduce也可以处理过来。
2. sort by
sort by 不受 hive.mapred.mode 是否为strict ,nostrict 的影响
sort by 的数据只能保证在同一reduce中的数据可以按指定字段排序。
使用sort by 你可以指定执行的reduce 个数 (set mapred.reduce.tasks=<number>) 这样可以输出更多的数据。
对输出的数据再执行归并排序,即可以得到全部结果。
注意:可以用limit子句大大减少数据量。使用limit n后,传输到reduce端(单机)的数据记录数就减少到n* (map个数)。否则由于数据过大可能出不了结果。
http://www.alidata.org/archives/622
3. distribute by
按照指定的字段对数据进行划分到不同的输出reduce / 文件中。
insert overwrite local directory '/home/hadoop/out' select * from test order by name distribute by length(name);
此方法会根据name的长度划分到不同的reduce中,最终输出到不同的文件中。
length 是内建函数,也可以指定其他的函数或这使用自定义函数。
4. Cluster By
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。
倒序排序,且不能指定排序规则。 asc 或者 desc。














 1061
1061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









