







 本文通过递归树方法详细分析了递归算法的时间复杂度,以归并排序、快速排序和斐波那契数列为例,揭示了算法的时间复杂度计算原理。在归并排序中,递归树呈现满二叉树形态,时间复杂度为O(nlogn)。快排在极端情况下时间复杂度仍为O(nlogn)。对于斐波那契数列,不同路径导致不同时间复杂度,但总体较高。全排列问题中,通过递归树展示了时间复杂度大致在O(n!)范围内。理解分析方法比精确数值更重要。
本文通过递归树方法详细分析了递归算法的时间复杂度,以归并排序、快速排序和斐波那契数列为例,揭示了算法的时间复杂度计算原理。在归并排序中,递归树呈现满二叉树形态,时间复杂度为O(nlogn)。快排在极端情况下时间复杂度仍为O(nlogn)。对于斐波那契数列,不同路径导致不同时间复杂度,但总体较高。全排列问题中,通过递归树展示了时间复杂度大致在O(n!)范围内。理解分析方法比精确数值更重要。
目的
借助递归树来分析递归算法的时间复杂度
递归树
递归的思想就是将大问题分解为小问题来求解,然后再将小问题分解为小小问题。这样一层一层地分解,直到问题的数据规模被分解得足够小,不用继续递归分解为止。
如果我们把这个一层一层的分解过程画成图就是一棵树——递归树。举例一棵斐波那契数列的递归树。节点里的数字表示数据的规模,一个节点的求解可以分解为左右子节点两个问题的求解。
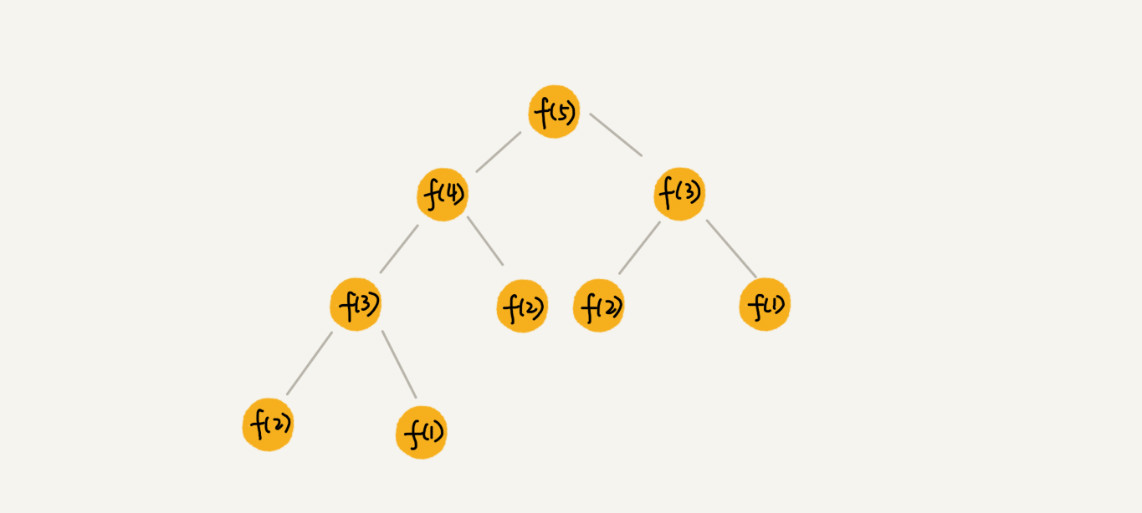
如何用递归树来求时间复杂度
以归并排序为例,通过递归树来进行时间复杂度分析。归并排序的递归树示意图:
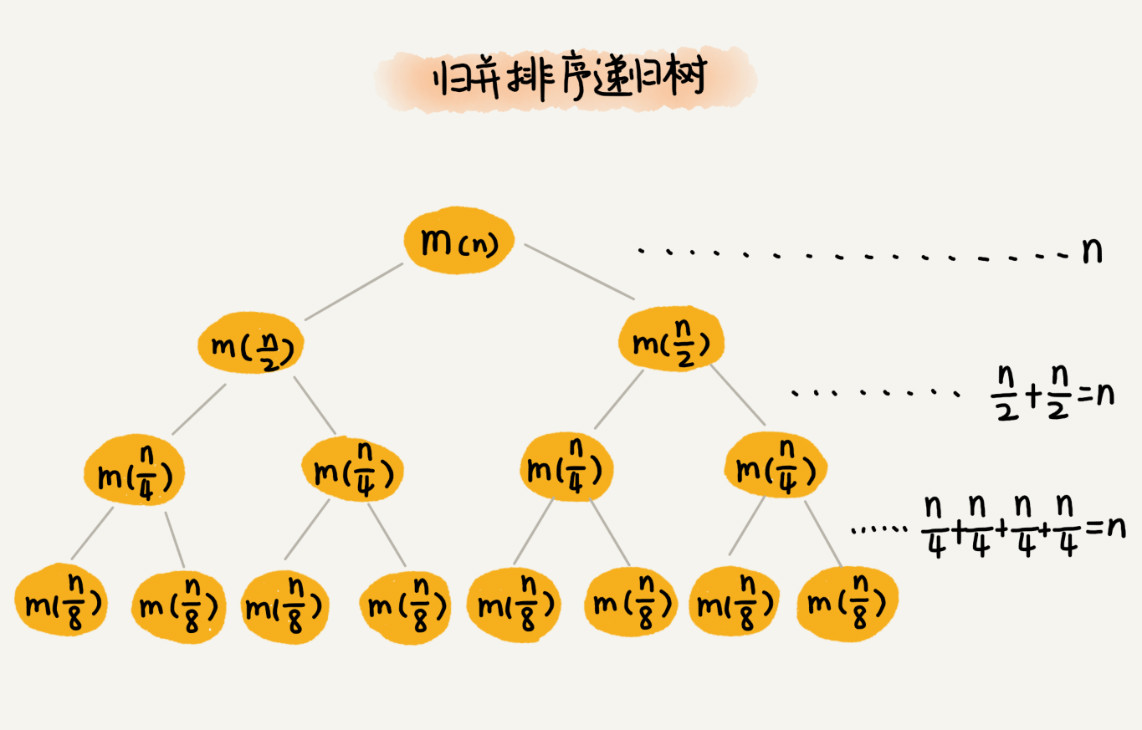
每一层排序时间消耗为n,如果知道了树的高度h,那么总的时间复杂度就是O(n∗h)。对于归并排序来说,归并排序递归树是一棵满二叉树。我们前两节中讲到,满二叉树的高度大约是 log2n,所以,归并排序递归实现的时间复杂度就是 O(nlogn)。
实战一:分析快排的时间复杂度
递归树:(假设快拍每次分区都很不平均,一个分区是另一个分区的 9 倍)
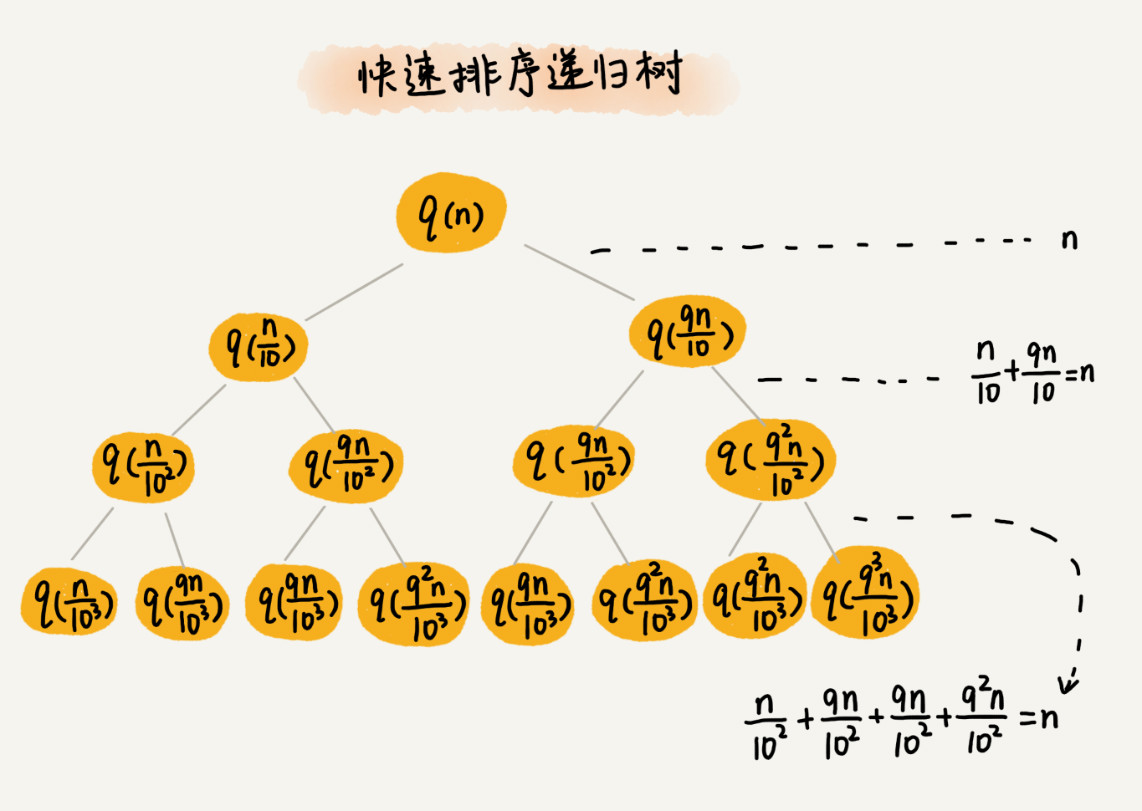
快速排序的过程中,每次分区都要遍历待分区区间的所有数据,所以,每一层分区操作所遍历的数据的个数之和就是 n。我们现在只要求出递归树的高度 h,这个快排过程遍历的数据个数就是 h∗n ,也就是说,时间复杂度就是 O(h∗n)。
- 快排的结束条件是待排序的区间大小为1,也即叶子结点规模为1
- 递归树中最短的一个路径每次都乘以 1/10,最长的一个路径每次都乘以 9/10
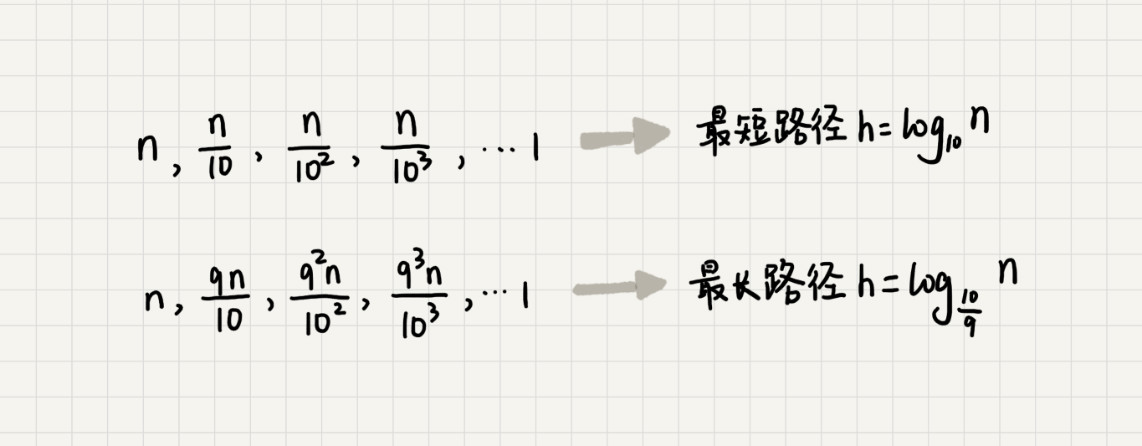
遍历数据的个数总和就介于 nlog10n 和 nlog910n 之间。根据复杂度的大 O 表示法,对数复杂度的底数不管是多少统一写成 logn,所以,当分区大小比例是 1:9 时,快速排序的时间复杂度仍然是 O(nlogn).
实战二:分析斐波那契数列的时间复杂度
跨台阶的递归树示意图:
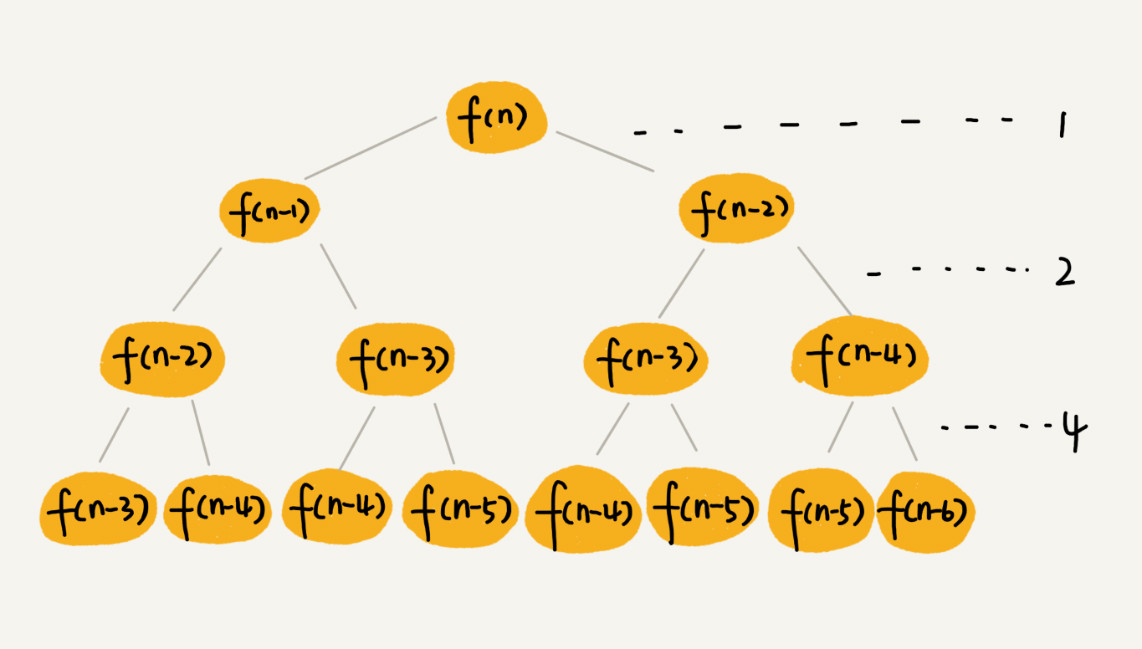
- f(n) 分解为 f(n−1) 和 f(n−2),每次数据规模都是 −1 或者 −2,叶子节点的数据规模是 1 或者 2。所以,从根节点走到叶子节点,每条路径是长短不一的。
- 每次都是 −1,那最长路径大约就是 n;如果每次都是 −2,那最短路径大约就是 n/2。每次分解之后的合并操作只需要一次加法运算,这次加法运算的时间消耗记作 1。
- 从上往下,第一层的总时间消耗是 1,第二层的总时间消耗是 2,第三层的总时间消耗就是 2的平方。依次类推,第 k 层的时间消耗就是 2的k−1方,那整个算法的总的时间消耗就是每一层时间消耗之和。
- 如果最长路径大约就是 n,那么总和就是2的n次方-1;如果最长路径长度是n/2,那么总时间消耗是2的n/2次方-1
分析全排列的时间复杂度
全排列的递推公式是:
假设数组中存储的是1,2, 3...n。
f(1,2,...n) = {最后一位是1, f(n-1)} + {最后一位是2, f(n-1)} +...+{最后一位是n, f(n-1)}。
// 调用方式:
// int[]a = a={1, 2, 3, 4}; printPermutations(a, 4, 4);
// k表示要处理的子数组的数据个数
public void printPermutations(int[] data, int n, int k) {
if (k == 1) {
for (int i = 0; i < n; ++i) {
System.out.print(data[i] + " ");
}
System.out.println();
}
for (int i = 0; i < k; ++i) {
int tmp = data[i];
data[i] = data[k-1];
data[k-1] = tmp;
printPermutations(data, n, k - 1);
tmp = data[i];
data[i] = data[k-1];
data[k-1] = tmp;
}
}递归树示意图
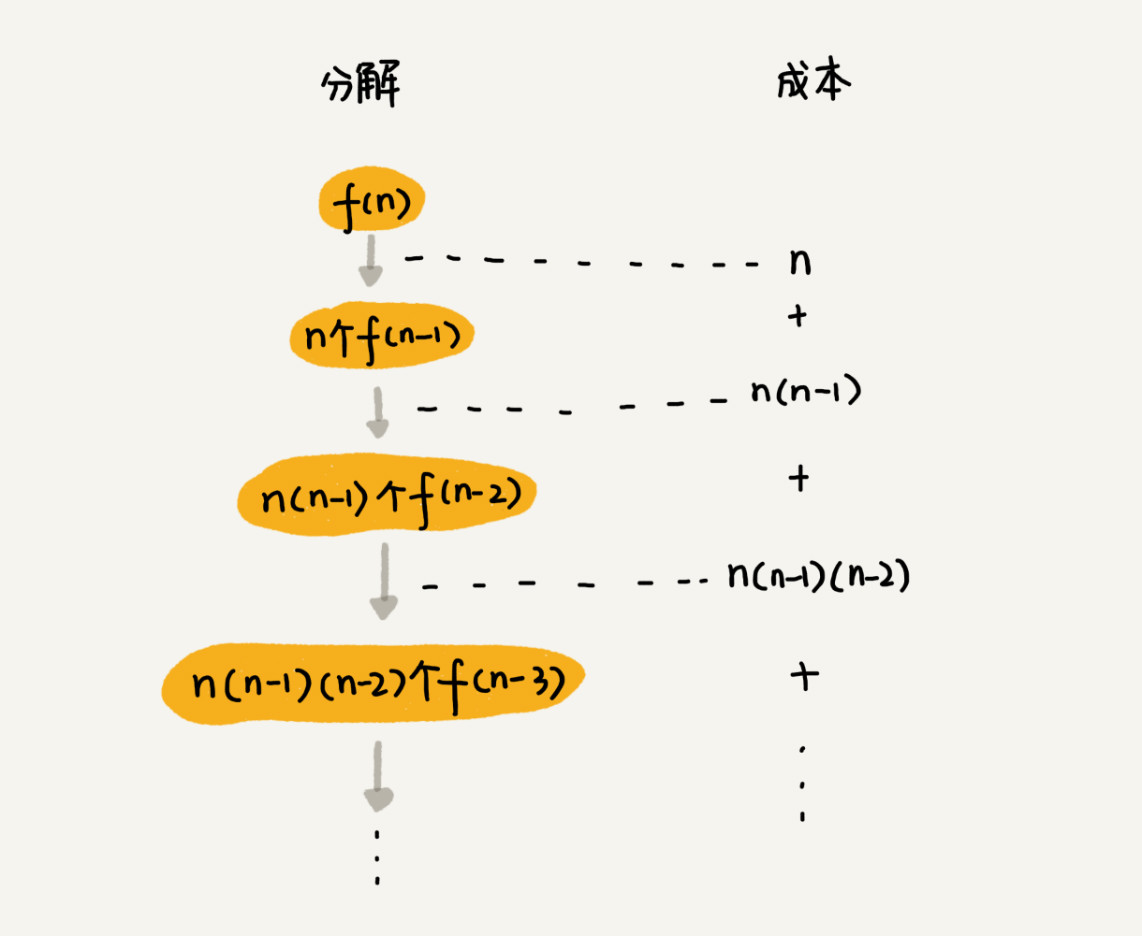
第一层分解有 n 次交换操作,第二层有 n 个节点,每个节点分解需要 n−1 次交换,所以第二层总的交换次数是 n∗(n−1)。第三层有 n∗(n−1) 个节点,每个节点分解需要 n−2 次交换,所以第三层总的交换次数是 n∗(n−1)∗(n−2)。以此类推,第 k 层总的交换次数就是 n∗(n−1)∗(n−2)∗...∗(n−k+1)。最后一层的交换次数就是 n∗(n−1)∗(n−2)∗...∗2∗1。每一层的交换次数之和就是总的交换次数。
n + n*(n-1) + n*(n-1)*(n-2) +... + n*(n-1)*(n-2)*...*2*1
最后一个数,n∗(n−1)∗(n−2)∗...∗2∗1 等于 n!,而前面的 n−1 个数都小于最后一个数,所以,总和肯定小于 n∗n!,也就是说,全排列的递归算法的时间复杂度大于 O(n!),小于 O(n∗n!),虽然我们没法知道非常精确的时间复杂度,但是这样一个范围已经让我们知道,全排列的时间复杂度是非常高的。
总结:掌握分析的方法很重要,思路是重点,不要纠结于精确的时间复杂度到底是多少。

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









