



本文为您介绍Flink批处理的一些基本原理和配置调优。
背景信息
作为支持流处理和批处理的统一计算框架,Flink能够同时处理两种不同的数据模式。尽管Flink在流处理和批处理模式下共享许多核心执行机制,但两种模式在作业执行机制、配置参数和性能调优方面存在一些关键差异。本文将专门针对Flink批处理作业,为您介绍其独特的执行机制、配置参数。通过深入理解这些差异,您将能够更加高效地对作业进行调优,以及排查和解决在使用Flink批处理作业中遇到的问题。
说明
实时计算Flink版也对Flink批处理进行了专门的支持,提供了作业开发、作业运维、作业编排、资源队列管理、数据结果探查等能力,您可以通过Flink批处理快速入门快速地了解上手。
批作业和流作业的比较
在介绍Flink批处理作业的配置参数和调优方法之前,首先需要了解Flink批处理与流处理作业在执行机制上的差异。
执行模式
-
流处理作业:流处理模式专注于处理持续不断的无界数据流,其核心在于实现低延迟的数据处理。在这种模式下,数据会以流水线模式在节点间即时传递并被处理。因此,流处理作业所有节点的子任务会同时部署和执行。
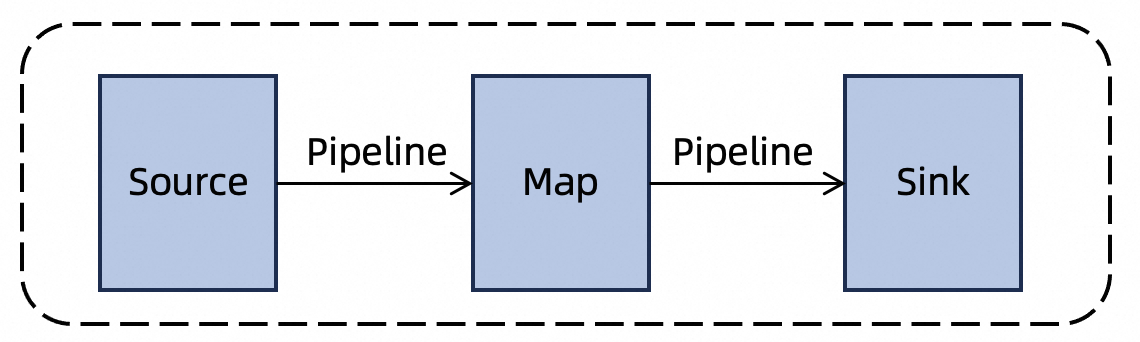
-
批处理作业:批处理模式专注于处理有界数据集,重点在于提供高吞吐量的数据处理。在这种执行模式下,作业通常由多个阶段组成,互不依赖的阶段可以并行执行,以提高资源利用率;对于存在数据依赖的阶段,下游任务需等待上游任务完成后才能启动。
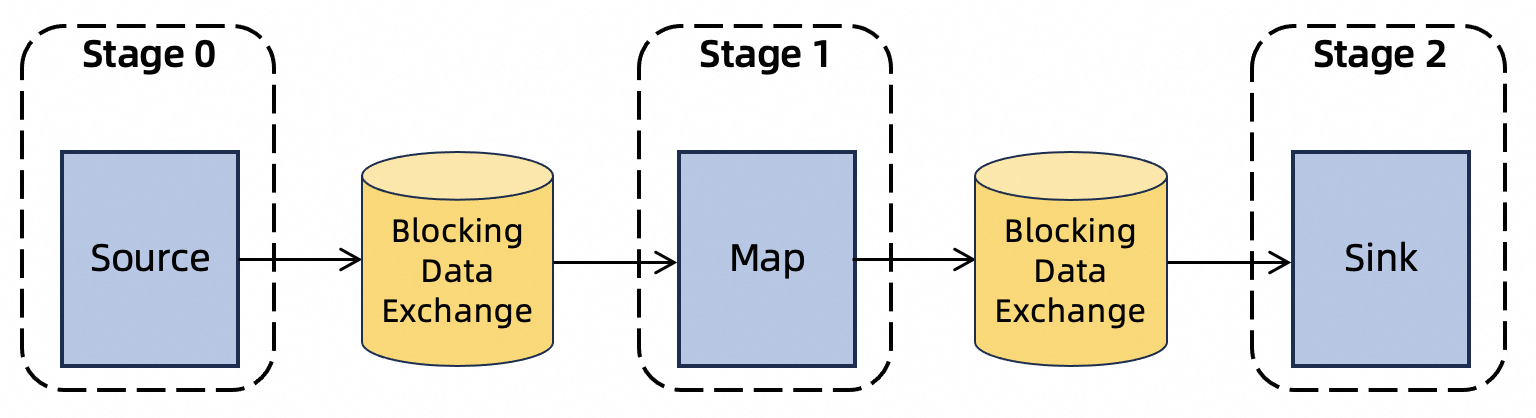
数据传输
-
流处理作业:为了实现低延迟,流处理作业的中间数据保留在内存中并直接通过网络进行传输,不会持久化。如果下游节点处理能力不足,则可能会导致上游节点遭遇反压。


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











