







先看效果:
小姐姐的眼睛很漂亮
SadTalker:使用一张图片和一段语音来生成口型和头、面部视频.
西安交通大学开源了人工智能SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。
论文地址:Learning Realistic 3D Motion Coefficients
整体来说 Talking head 就是用语音驱动每一帧图片的表情(眼睛、嘴巴等)和头部(head motion)运动,并重建人脸以生成视频。表情运动是局部的,头部运动是全局的,且表情跟声音的关系比较强,头部姿态跟声音的关系比较弱,将这两个系数解耦开可以减少人脸扭曲。
sadtalker的原理基于深度学习技术,主要包括两个关键步骤:情感分类和文本生成。
一、下载工程文件
git clone https://github.com/Winfredy/SadTalker.git
文件如下:

二、安装Python
发现只支持python 3.10.6,>>>点击下载<<<
安装完成将Python添加到PATH
三、安装ffmpeg
下载 ffmpeg
解压到本地并记下bin的路径,将路径添加到PATH
也可以使用 scoop 安装 ffmpeg:
scoop install ffmpeg。
四、启动
运行webui.bat

第一次运行会下载gfpgan 模型,同时会自动安装requirements.txt里的组件,需要一点时间。
上传一张人物照片,上传一段wav格式的语音。

在右侧设置:
crop:短的,裁剪的,大头贴模式
resize:调整大小
full:原图
Still Mode:静止模式,较少的手部动作
GFPGAN as Face enhancer:人脸增强,GFPGAN是一个免费使用的开源软件,可以提高照片的分辨率和修复一些损坏。
点击“Generate”就开始生成了。
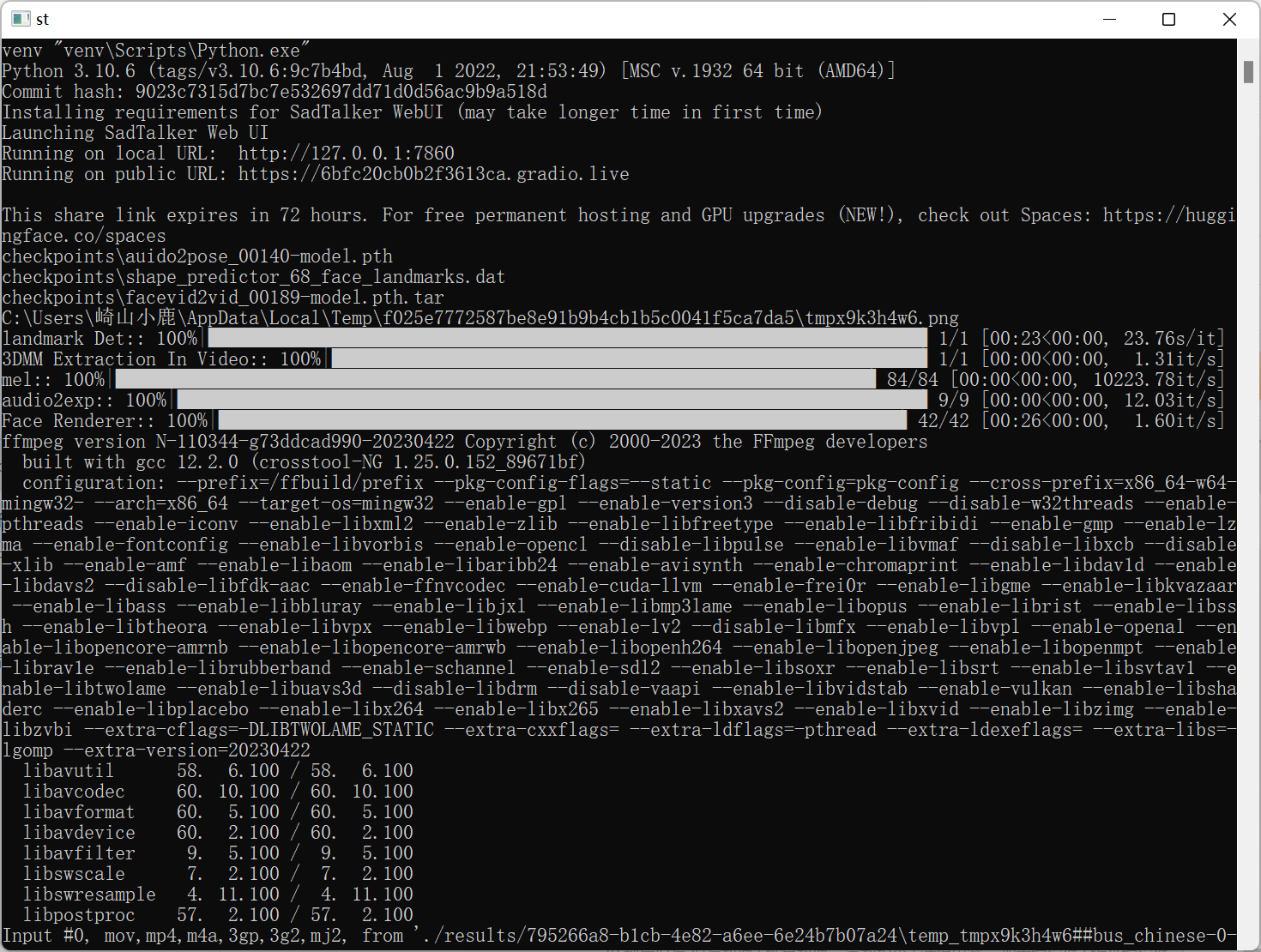
用了我10G内存和4G显存
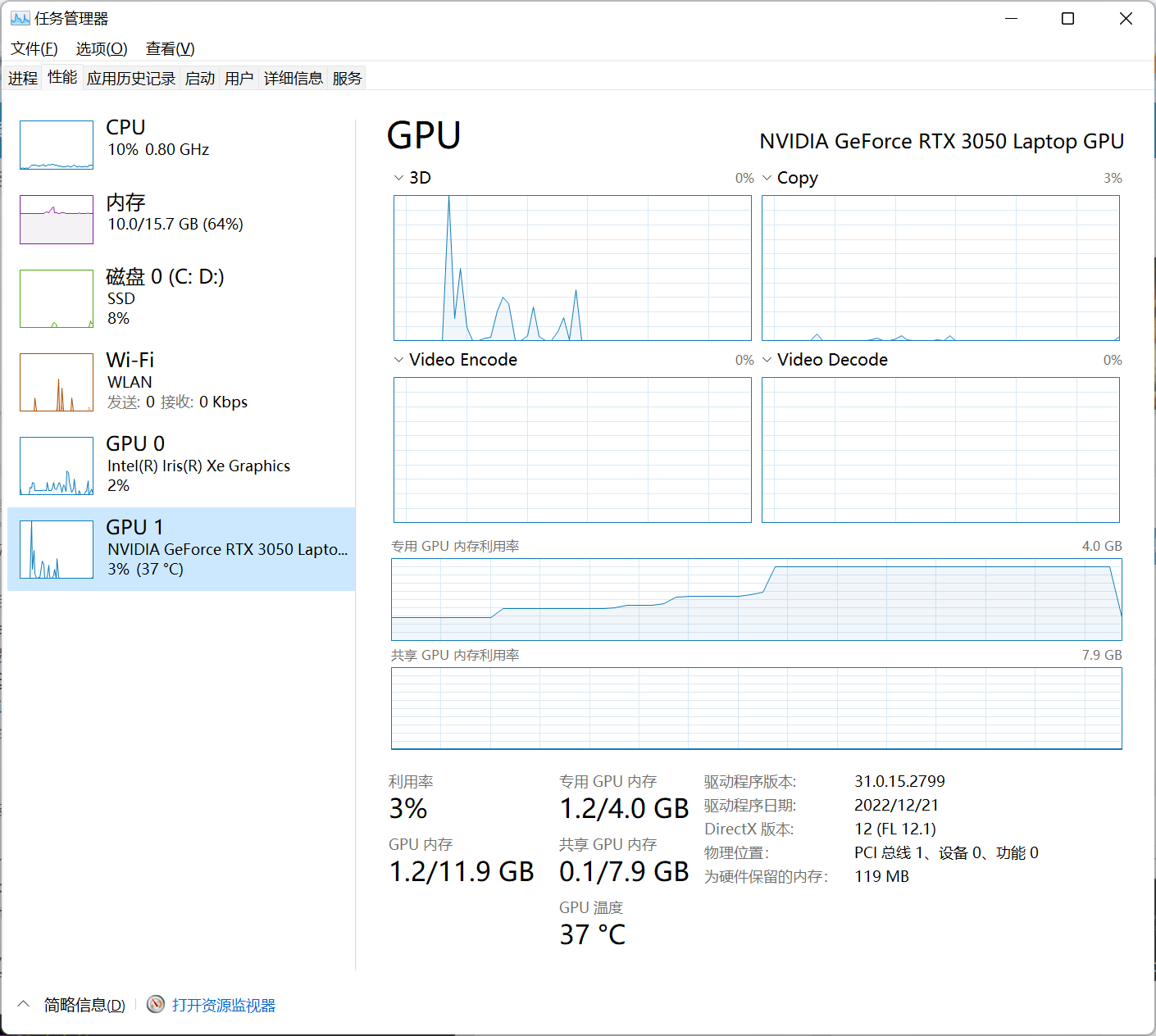
●gradio的版本不对也会影响启动,建议安装3.27.0版本: pip install gradio==3.27.0
参考:金双石科技 -
















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











